

Apa itu Normalisasi Batch
Normalisasi Batch adalah teknik terobosan dalam deep learning yang mempercepat pelatihan, meningkatkan konvergensi model, dan menyederhanakan proses pemilihan learning rate optimal dan inisialisasi bobot. Diusulkan oleh Ioffe dan Szegedy pada tahun 2015, normalisasi batch mengatasi masalah internal covariate shift, yang terjadi ketika distribusi input ke lapisan tertentu dalam jaringan saraf berubah selama pelatihan karena pembaruan parameter.
Tujuan utama dari normalisasi batch adalah untuk menstabilkan distribusi input untuk setiap lapisan dalam jaringan saraf, memungkinkan pelatihan yang lebih cepat dan stabil. Ini dicapai dengan melakukan normalisasi aktivasi setiap lapisan menggunakan rata-rata dan varian setiap fitur dalam mini-batch. Setelah dinormalisasi, data di-skalakan dan digeser menggunakan parameter yang dapat dipelajari yang diperbarui selama pelatihan. Ini memastikan bahwa model masih dapat merepresentasikan rentang distribusi input yang luas.
Pentingnya Normalisasi Batch
Pengenalan normalisasi batch telah sangat mempengaruhi bidang deep learning, karena telah menjadi komponen standar dalam desain berbagai arsitektur deep learning. Teknik ini menawarkan beberapa manfaat yang berkontribusi pada adopsi yang luas:
-Pelatihan lebih cepat
Dengan menstabilkan distribusi input, normalisasi batch memungkinkan penggunaan learning rate yang lebih tinggi, yang mempercepat proses pelatihan.
-
Konvergensi model yang lebih baik
Mengnormalisasi aktivasi lapisan membantu mencegah masalah gradien yang menghilang dan meledak, yang dapat menghambat konvergensi model. -
Sensitivitas terhadap inisialisasi berkurang
Normalisasi batch mengurangi efek inisialisasi bobot yang buruk, sehingga lebih mudah melatih jaringan yang dalam.
Generalisasi yang lebih baik
Efek regularisasi dari normalisasi batch dapat membantu mencegah overfitting dan meningkatkan generalisasi model pada data yang tidak terlihat.
- Penyetelan hiperparameter yang lebih sederhana
Karena normalisasi batch menstabilkan pelatihan, ini mengurangi kebutuhan penyetelan hiperparameter yang ekstensif, menghemat waktu dan resource komputasi.
Normalisasi batch telah berperan penting dalam meningkatkan kinerja banyak model state-of-the-art, terutama dalam tugas penglihatan komputer seperti klasifikasi gambar, deteksi objek, dan segmentasi semantik. Selain itu, teknik ini telah menginspirasi pengembangan metode normalisasi lainnya, seperti normalisasi lapisan, normalisasi contoh, dan normalisasi kelompok, yang telah menemukan aplikasi dalam berbagai domain, termasuk pemrosesan bahasa alami dan reinforcement learning.
Latar Belakang dan Teori
Covariate Shift
Covariate shift merujuk pada perubahan distribusi fitur input selama proses pelatihan. Fenomena ini sangat problematik dalam deep learning, karena dapat menyebabkan internal covariate shift, di mana distribusi input ke setiap lapisan berubah saat parameter lapisan sebelumnya diperbarui. Internal covariate shift dapat memperlambat pelatihan, karena memerlukan learning rate yang lebih rendah dan inisialisasi yang hati-hati untuk menjaga kestabilan.
Normalisasi Batch menangani masalah internal covariate shift dengan memastikan bahwa distribusi input ke setiap lapisan tetap konsisten selama pelatihan. Ini dicapai dengan melakukan normalisasi aktivasi setiap lapisan, secara efektif menstabilkan proses pembelajaran dan memungkinkan penggunaan learning rate yang lebih tinggi.
Algoritma Normalisasi Batch
Normalisasi batch diterapkan pada aktivasi setiap lapisan sebelum fungsi aktivasi diterapkan. Algoritma dapat dibagi menjadi langkah-langkah berikut:
- Hitung rata-rata dan varian aktivasi untuk setiap fitur dalam mini-batch.
- Normalisasi aktivasi menggunakan rata-rata dan varian yang dihitung.
- Skala dan geser aktivasi yang telah dinormalisasi menggunakan parameter yang dapat dipelajari (
\gamma \beta
Secara matematis, langkah normalisasi dapat diekspresikan sebagai:
di mana
Langkah skala dan geser dapat diekspresikan sebagai:
di mana
Parameter dan Hyperparameter Utama
Normalisasi batch memiliki beberapa parameter dan hyperparameter utama yang mempengaruhi perilakunya:
-
Ukuran mini-batch
Ukuran mini-batch yang digunakan untuk normalisasi mempengaruhi estimasi rata-rata dan varian. Ukuran batch yang lebih besar menyediakan estimasi yang lebih akurat tetapi mungkin memerlukan lebih banyak memori dan resource komputasi. Ukuran batch yang lebih kecil dapat memperkenalkan noise ke dalam proses normalisasi, tetapi juga dapat memiliki efek regularisasi yang bermanfaat. -
Momentum
Selama pelatihan, normalisasi batch menjaga rata-rata berjalan dari rata-rata dan varian, yang digunakan untuk normalisasi pada waktu pengujian. Parameter momentum menentukan bobot dari statistik mini-batch saat ini dalam rata-rata berjalan. Nilai momentum yang umum berkisar antara 0,9 dan 0,99. -
\epsilon
Parameter\epsilon \epsilon
Parameter yang dapat dipelajari (
Parameter
Membandingkan Model dengan dan tanpa Normalisasi Batch
Di bab ini, saya akan membandingkan kinerja model deep learning dengan dan tanpa normalisasi batch. Kita akan menggunakan dataset MNIST populer dan melatih jaringan saraf maju sederhana untuk mengklasifikasikan digit tulisan tangan. Terakhir, kita akan memplot kurva pembelajaran kedua model menggunakan matplotlib.
Pertama, mari impor perpustakaan yang diperlukan dan muat dataset:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization, Activation
from tensorflow.keras.optimizers import Adam
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
Sekarang, mari definisikan fungsi untuk membuat model, dengan lapisan normalisasi batch opsional:
def create_model(use_batchnorm):
model = Sequential()
model.add(Dense(128, input_shape=(784,)))
if use_batchnorm:
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(64))
if use_batchnorm:
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(10, activation='softmax'))
return model
Selanjutnya, kita akan membuat dan melatih dua model - satu dengan normalisasi batch dan satu tanpa:
model_without_bn = create_model(use_batchnorm=False)
model_without_bn.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
history_without_bn = model_without_bn.fit(x_train, y_train, batch_size=128, epochs=20, verbose=1, validation_data=(x_test, y_test))
model_with_bn = create_model(use_batchnorm=True)
model_with_bn.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
history_with_bn = model_with_bn.fit(x_train, y_train, batch_size=128, epochs=20, verbose=1, validation_data=(x_test, y_test))
Terakhir, mari plot kurva pembelajaran menggunakan matplotlib:
plt.style.use('ggplot')
plt.figure(figsize=(10, 6))
plt.plot(history_without_bn.history['accuracy'], linestyle='-', label='Training (No BN)')
plt.plot(history_without_bn.history['val_accuracy'], linestyle='--', label='Validation (No BN)')
plt.plot(history_with_bn.history['accuracy'], linestyle='-', label='Training (With BN)')
plt.plot(history_with_bn.history['val_accuracy'], linestyle='--', label='Validation (With BN)')
plt.title('Learning Curves: With and Without Batch Normalization')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
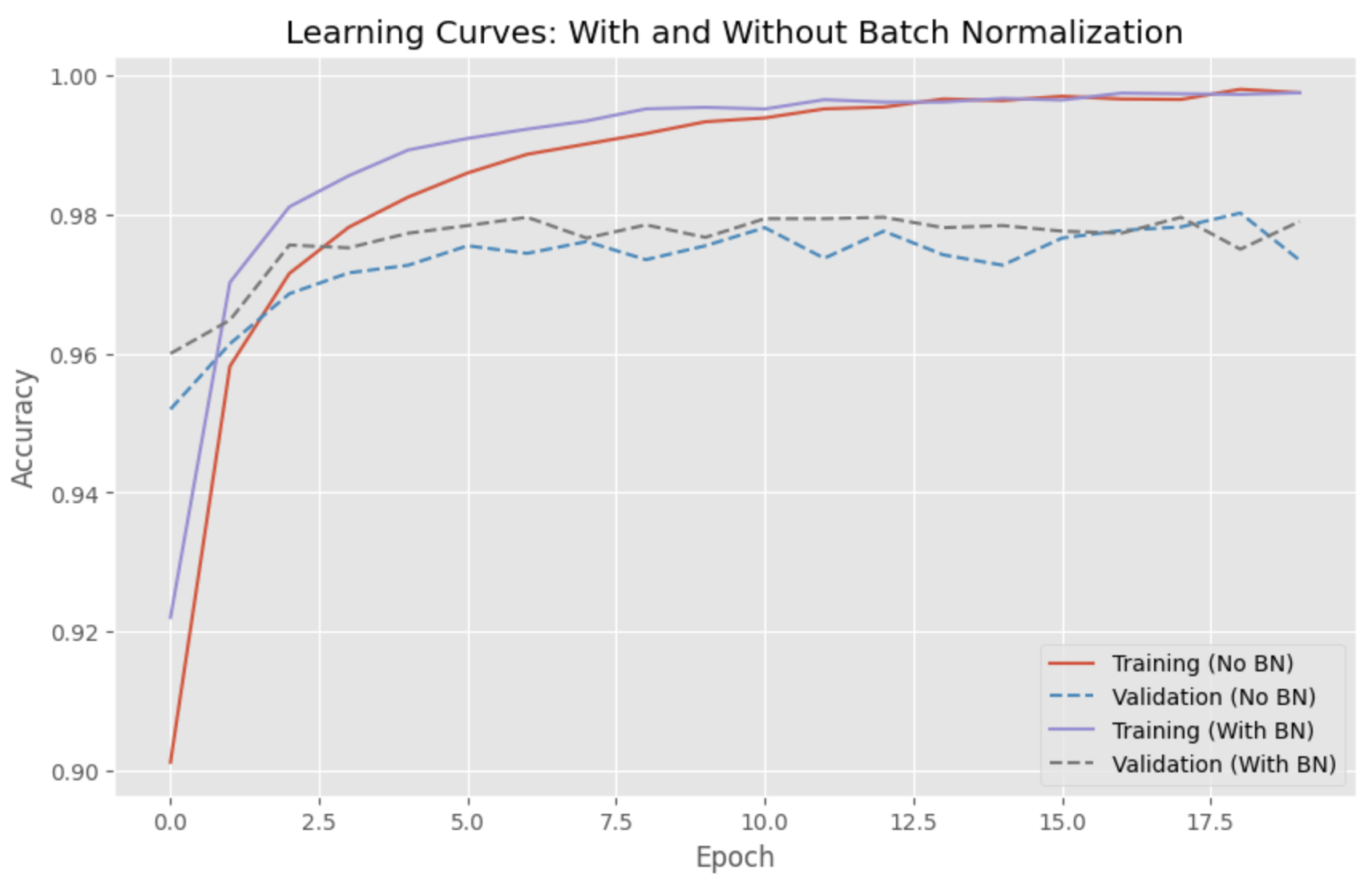
Kurva pembelajaran menunjukkan bahwa model dengan normalisasi batch konvergen lebih cepat dan mencapai akurasi validasi yang lebih tinggi daripada model tanpa normalisasi batch.
Referensi

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS