

Apa itu Masalah Gradien Hilang
Masalah gradien hilang adalah masalah yang terkenal dalam pembelajaran jaringan saraf dalam kedalaman. Masalah ini terjadi ketika gradien yang digunakan untuk memperbarui parameter jaringan menjadi sangat kecil saat menyebar ke belakang melalui lapisan jaringan. Hal ini dapat menyebabkan lapisan awal dalam jaringan hampir tidak menerima pembaruan selama pembelajaran, yang mengakibatkan konvergensi yang lambat dan kinerja yang buruk.
Untuk memahami masalah gradien hilang, penting untuk mempertimbangkan algoritma backpropagation yang digunakan untuk melatih jaringan saraf dalam kedalaman. Selama pembelajaran, algoritma backpropagation menghitung gradien dari fungsi kerugian terhadap parameter jaringan. Gradien ini kemudian digunakan untuk memperbarui parameter, memungkinkan jaringan untuk belajar dari data pelatihan.
Namun, dalam jaringan saraf dalam kedalaman, gradien dapat menjadi sangat kecil saat menyebar ke belakang melalui lapisan jaringan. Ini terjadi karena gradien dikalikan dengan matriks bobot pada setiap lapisan, dan hasil kali dari banyak angka kecil dapat menjadi sangat kecil. Akibatnya, lapisan awal dalam jaringan hampir tidak menerima pembaruan selama pembelajaran, yang mengakibatkan konvergensi yang lambat dan kinerja yang buruk.
Penyebab Masalah Gradien Hilang
Pilihan Fungsi Aktivasi
Faktor signifikan yang berkontribusi pada masalah gradien hilang adalah pilihan fungsi aktivasi. Fungsi aktivasi seperti fungsi sigmoid dan tangen hiperbolik rentan terhadap saturasi, di mana output menjadi tidak sensitif terhadap perubahan kecil pada input. Saturasi ini dapat menyebabkan gradien menjadi sangat kecil, terutama pada jaringan dalam kedalaman yang banyak. Akibatnya, lapisan awal dalam jaringan hampir tidak menerima pembaruan selama pembelajaran, yang mengakibatkan konvergensi yang lambat dan kinerja yang buruk.
Untuk mengatasi masalah ini, para peneliti telah mengusulkan alternatif fungsi aktivasi yang kurang rentan terhadap saturasi, seperti fungsi Rectified Linear Unit (ReLU). Fungsi ReLU memiliki bentuk sederhana dan mudah dihitung, sehingga populer dalam banyak aplikasi pembelajaran dalam kedalaman. Selain itu, penelitian terbaru telah menjelajahi fungsi aktivasi yang lebih kompleks seperti fungsi Swish, yang telah terbukti meningkatkan kinerja jaringan saraf dalam kedalaman.
Kedalaman Jaringan
Faktor lain yang dapat berkontribusi pada masalah gradien hilang adalah kedalaman jaringan. Ketika jumlah lapisan dalam jaringan meningkat, gradien harus menyebar melalui lebih banyak lapisan, yang meningkatkan kemungkinan gradien menjadi sangat kecil. Hal ini dapat membuat pelatihan jaringan dalam kedalaman menjadi sulit, karena gradien mungkin menjadi terlalu kecil untuk berguna.
Untuk mengatasi masalah ini, para peneliti telah mengusulkan teknik seperti koneksi melompat (skip connections), di mana output dari satu lapisan ditambahkan ke input dari lapisan selanjutnya. Koneksi melompat dapat membantu mengurangi masalah gradien hilang dengan memungkinkan gradien menyebar lebih mudah melalui jaringan. Selain itu, teknik normalisasi seperti normalisasi batch dapat membantu menstabilkan gradien, memungkinkan gradien menyebar lebih mudah melalui jaringan.
Inisialisasi Bobot
Terakhir, inisialisasi bobot dalam jaringan juga dapat berkontribusi pada masalah gradien hilang. Jika bobot diinisialisasi dengan nilai besar, gradien dapat menjadi sangat kecil saat menyebar melalui lapisan. Hal ini karena hasil kali dari angka besar dapat dengan cepat menjadi terlalu besar atau terlalu kecil, tergantung pada tanda dari bobot.
Untuk mengatasi masalah ini, para peneliti telah mengusulkan strategi inisialisasi bobot yang cermat seperti inisialisasi Xavier. Inisialisasi Xavier mengatur bobot awal setiap lapisan untuk sebanding dengan akar kuadrat dari jumlah input ke lapisan. Ini memastikan bahwa gradien awal memiliki magnitudo yang sesuai, memungkinkan gradien menyebar lebih mudah melalui jaringan.
Efek Masalah Gradien Hilang
Konvergensi yang Lambat Selama Pelatihan
Efek signifikan dari masalah gradien hilang adalah konvergensi yang lambat selama pelatihan. Ketika gradien menjadi sangat kecil saat menyebar ke belakang melalui jaringan, lapisan awal dalam jaringan hampir tidak menerima pembaruan selama pelatihan. Hal ini dapat mengakibatkan konvergensi yang lambat dan membuat sulit untuk melatih jaringan secara efektif. Dalam beberapa kasus, jaringan mungkin tidak konvergen sama sekali, sehingga tidak dapat belajar dari data pelatihan.
Potensi Solusi Suboptimal
Efek lain dari masalah gradien hilang adalah potensi jaringan terjebak pada solusi suboptimal. Ketika gradien menjadi sangat kecil, jaringan mungkin tidak dapat mengeksplorasi seluruh ruang solusi yang mungkin secara efektif. Akibatnya, jaringan mungkin konvergen ke solusi suboptimal yang tidak sebaik solusi optimal. Hal ini dapat mengakibatkan kinerja yang buruk pada data uji dan membatasi efektivitas jaringan.
Overfitting Karena Gradien Hilang
Akhirnya, masalah gradien hilang juga dapat berkontribusi pada overfitting, di mana jaringan mempelajari data pelatihan terlalu baik dan gagal untuk mengeneralisasi pada data baru. Ketika gradien menjadi sangat kecil, jaringan mungkin mulai overfit pada data pelatihan, menghafal data daripada belajar untuk mengeneralisasi pada data baru. Hal ini dapat mengakibatkan kinerja yang buruk pada data uji dan membatasi kegunaan jaringan dalam aplikasi dunia nyata.
Menunjukkan Masalah Gradien Hilang
Pada bab ini, saya akan menunjukkan masalah gradien hilang dengan menunjukkan distribusi aktivasi.
Kita akan menggunakan perpustakaan PyTorch untuk mengimplementasikan arsitektur jaringan saraf dalam kedalaman dan dataset MNIST, yang merupakan dataset publik yang banyak digunakan untuk digit tulisan tangan. Tujuan kita adalah untuk melatih jaringan saraf dalam kedalaman untuk mengklasifikasikan digit dengan benar. Kita akan menggunakan arsitektur jaringan saraf dalam kedalaman dengan beberapa lapisan tersembunyi, masing-masing menggunakan fungsi aktivasi sigmoid.
Kita akan pertama-tama melatih jaringan menggunakan pendekatan standar, tanpa teknik apa pun untuk mengatasi masalah gradien hilang. Kita kemudian akan menunjukkan distribusi aktivasi pada setiap lapisan jaringan untuk menunjukkan dampak masalah gradien hilang.
Berikut adalah kode PyTorch untuk mendefinisikan arsitektur jaringan saraf dalam kedalaman dan melatih jaringan:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# Load MNIST dataset
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True, num_workers=2)
# Define deep network with sigmoid activation
class DeepSigmoidNet(nn.Module):
def __init__(self):
super(DeepSigmoidNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 1000)
self.fc2 = nn.Linear(1000, 1000)
self.fc3 = nn.Linear(1000, 1000)
self.fc4 = nn.Linear(1000, 1000)
self.fc5 = nn.Linear(1000, 1000)
self.fc6 = nn.Linear(1000, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.sigmoid(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
x = torch.sigmoid(self.fc3(x))
x = torch.sigmoid(self.fc4(x))
x = torch.sigmoid(self.fc5(x))
x = self.fc6(x)
return x
# Instantiate the network, loss function, and optimizer
net = DeepSigmoidNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
# Train the network
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# Print average loss per epoch
print(f"Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}")
# Collect gradients for histogram
gradients = []
for p in net.parameters():
if p.grad is not None:
gradients.append(p.grad.view(-1).cpu().numpy())
Mari kita gambarkan distribusi nilai gradien.
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
# Create a histogram of the gradients
plt.hist(gradients, bins=100, range=(-1, 1), log=True, color='blue', alpha=0.5)
plt.xlabel('Gradient Values')
plt.ylabel('Frequency')
plt.title('Histogram of Gradient Values in Deep Sigmoid Network')
plt.show()
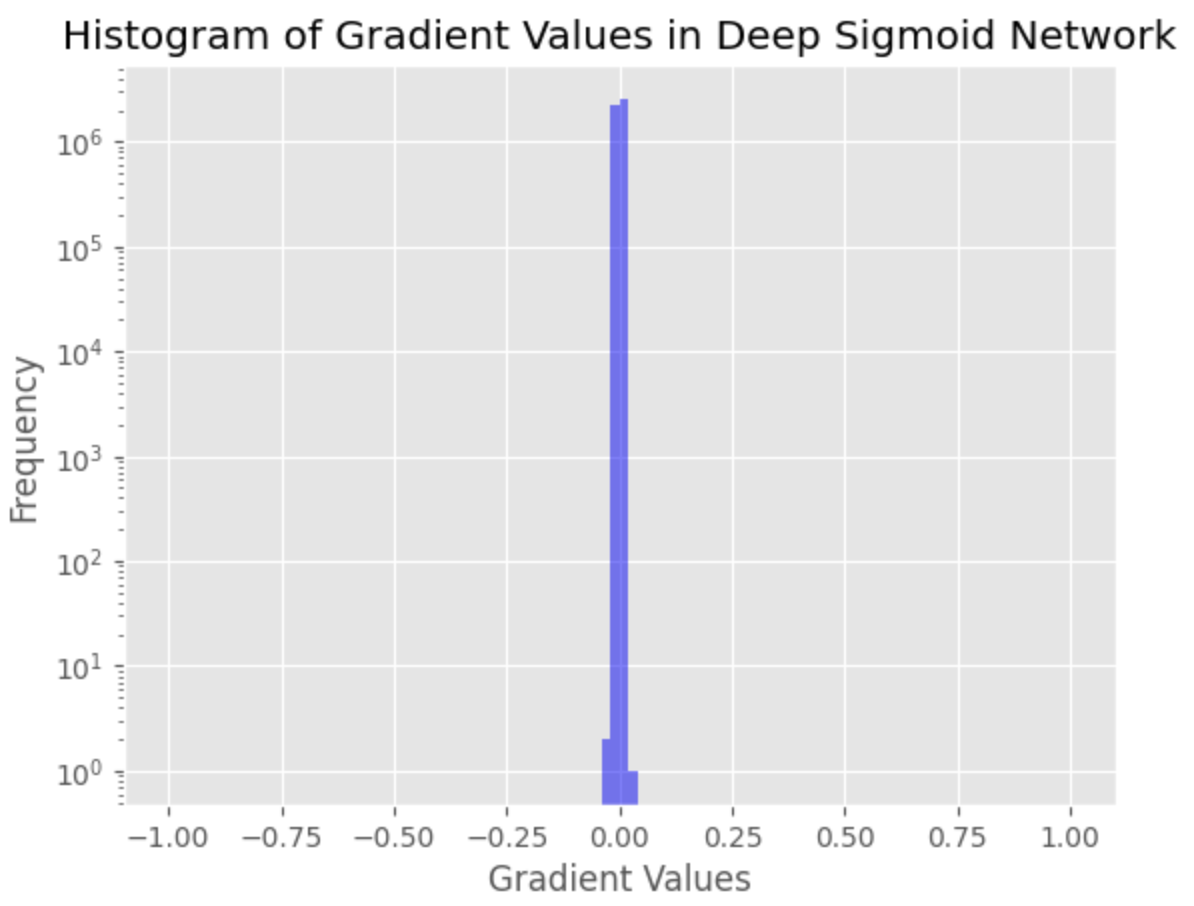
Masalah gradien hilang ditemukan sebagai sejumlah besar nilai gradien yang sangat kecil, menunjukkan bahwa gradien untuk lapisan awal dalam jaringan hampir hilang. Hal ini dapat mengakibatkan konvergensi yang buruk dan kesulitan dalam melatih jaringan.

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS