

Apa itu Attention
Attention adalah nilai yang menunjukkan kata mana dalam sebuah kalimat yang harus diperhatikan dalam NLP. Attention pertama kali diperkenalkan dalam makalah Neural Machine Translation by Jointly Learning to Align and Translate, dan digambarkan sebagai "soft align" atau "soft search" dalam makalah tersebut.
Perhatikan teks bahasa Inggris yang diterjemahkan ke dalam bahasa Jepang berikut ini.
I like apple.
Kalimat bahasa Inggris ini dapat diterjemahkan sebagai berikut.
私はりんごが好きです。
Ketika kita sebagai manusia menerjemahkan "apple" menjadi "りんご", kita berfokus pada kata "apple" dan kata "like" yang ada di depannya.
Dengan cara ini, kita sebagai manusia memperhatikan beberapa kata dalam sebuah kalimat ketika kita menerjemahkan. Attention menerapkan ide ini pada model jaringan saraf.
Memahami Attention
Kita akan mencoba memahami Attention secara visual. Artikel berikut ini sangat mudah dipahami, jadi saya akan merujuk ke artikel ini dan menambahkannya seperlunya.
Model Encoder-Decoder Konvensional
Attention muncul karena keterbatasan model Encoder-Decoder (Seq2seq).
Model Encoder-Decoder terdiri dari dua RNN, Encoder dan Decoder, yang memproses setiap elemen input dan menyusun informasi yang ditangkap menjadi vektor konteks berdimensi tetap. Setelah memproses semua input, Encoder mengirimkan vektor konteks ke Decoder, yang mengambil vektor konteks, keadaan tersembunyi, dan output sebelumnya sebagai input dan mengeluarkan setiap elemen satu per satu.
- Encoder: Mengonversi kata masukan
x c - Decoder: mengeluarkan kata
y_i c h_i y_{i-1}
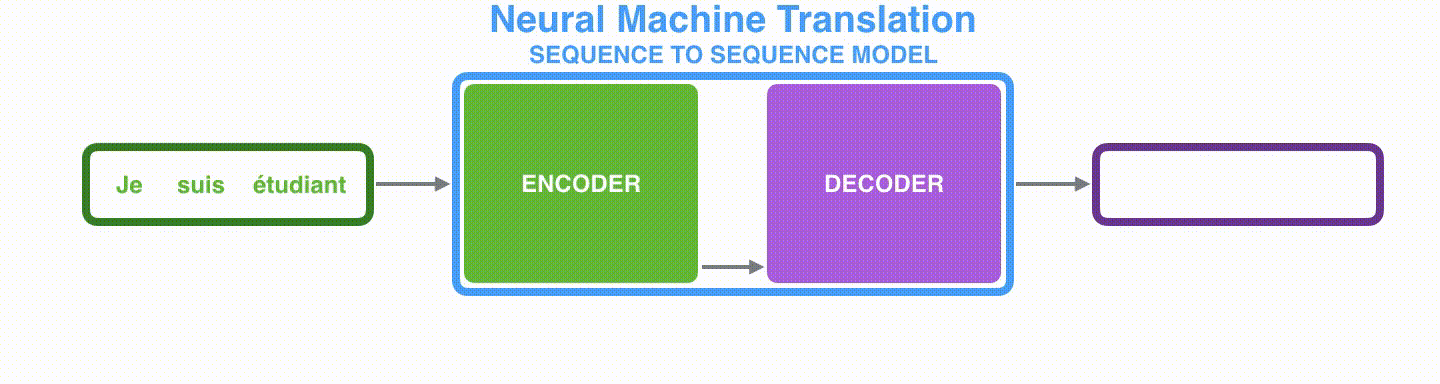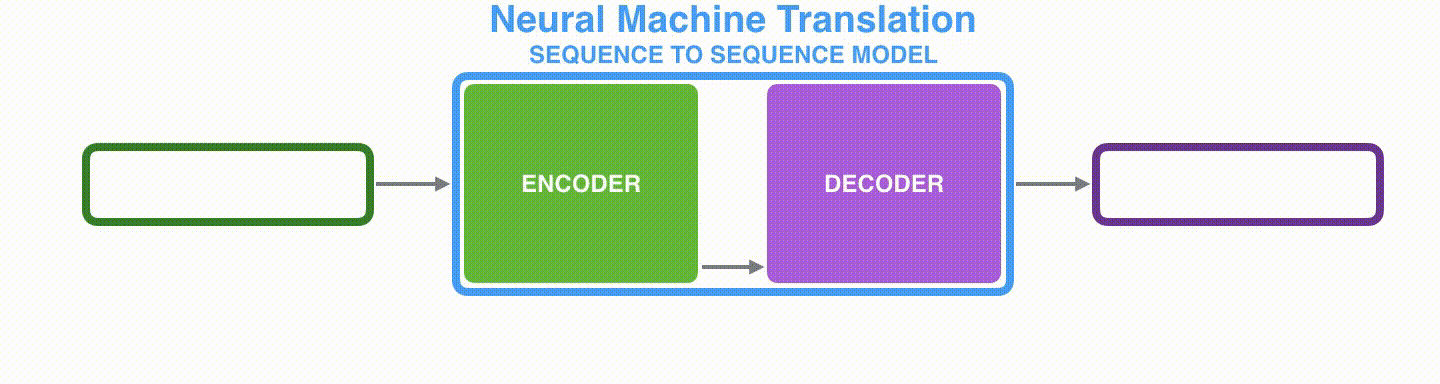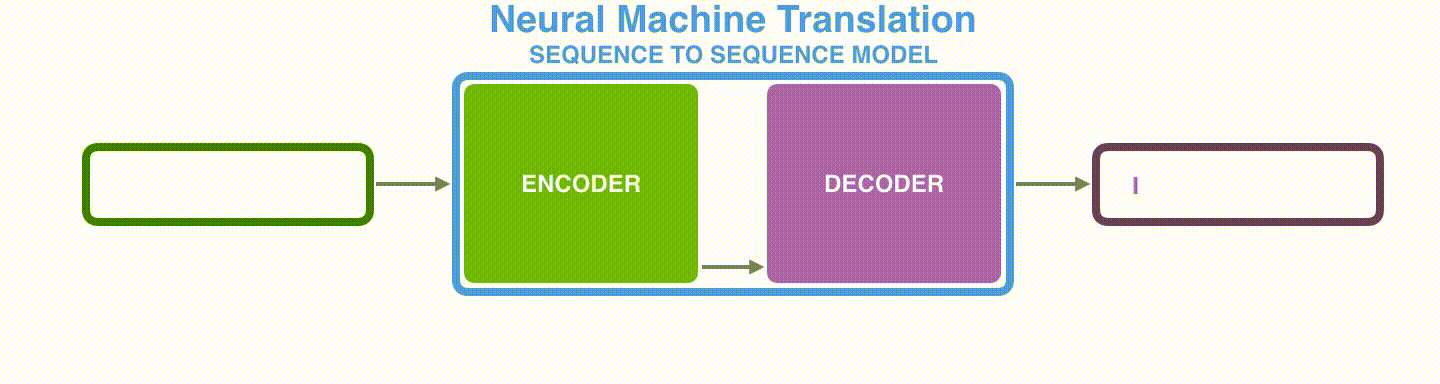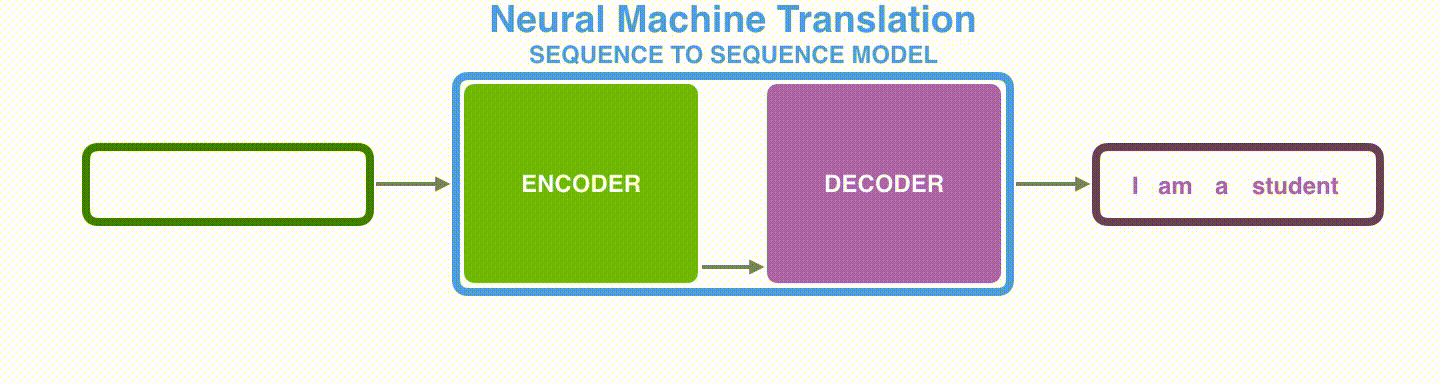
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Ukuran vektor konteks dapat diatur saat merancang model. Pada dasarnya, ukurannya harus sama dengan dimensi lapisan tersembunyi RNN (256, 512, atau 1024 dimensi). Pada gambar di bawah ini, ini diatur ke 4 dimensi.

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
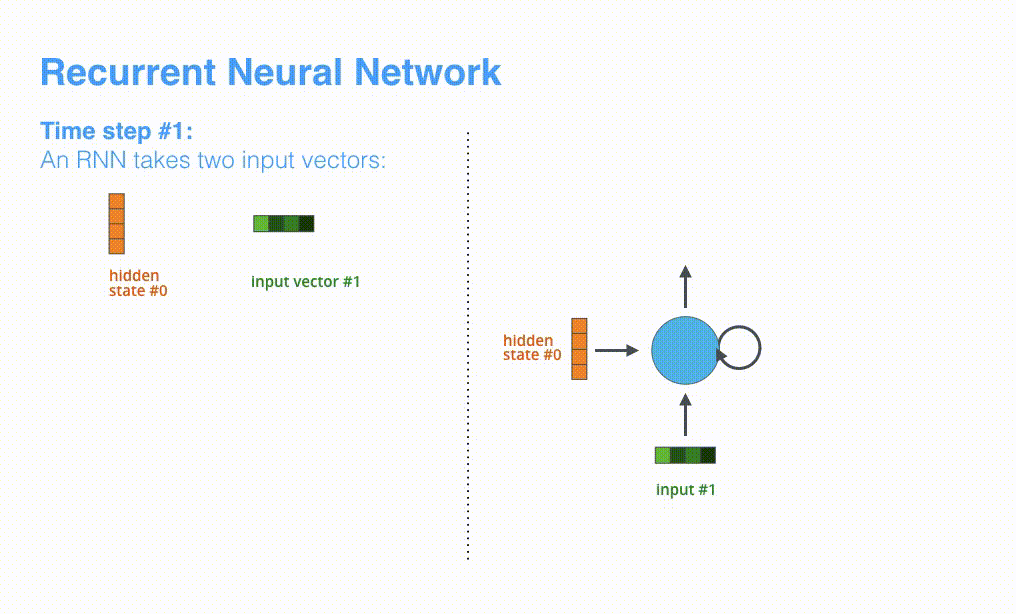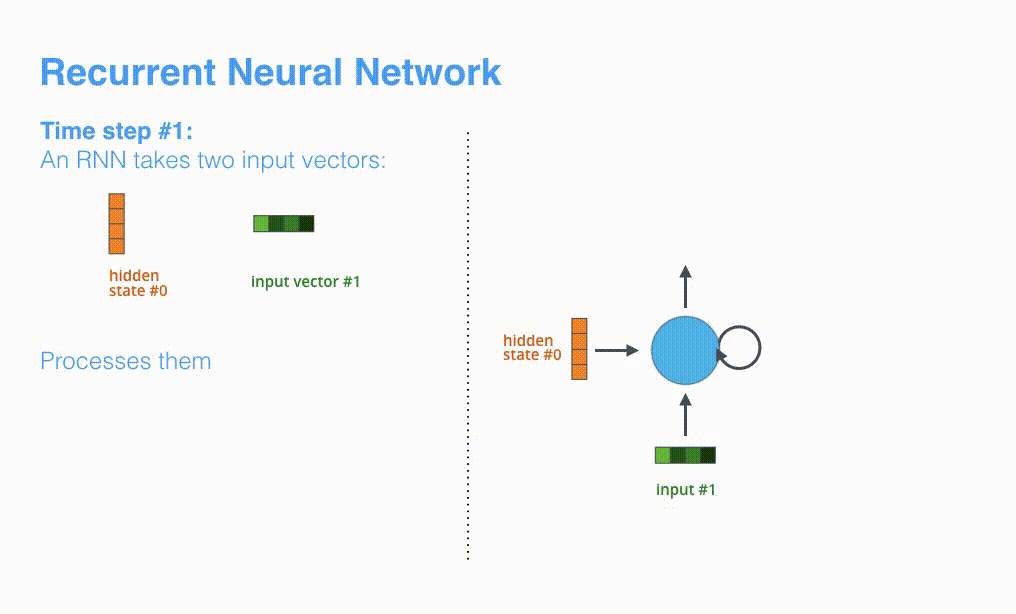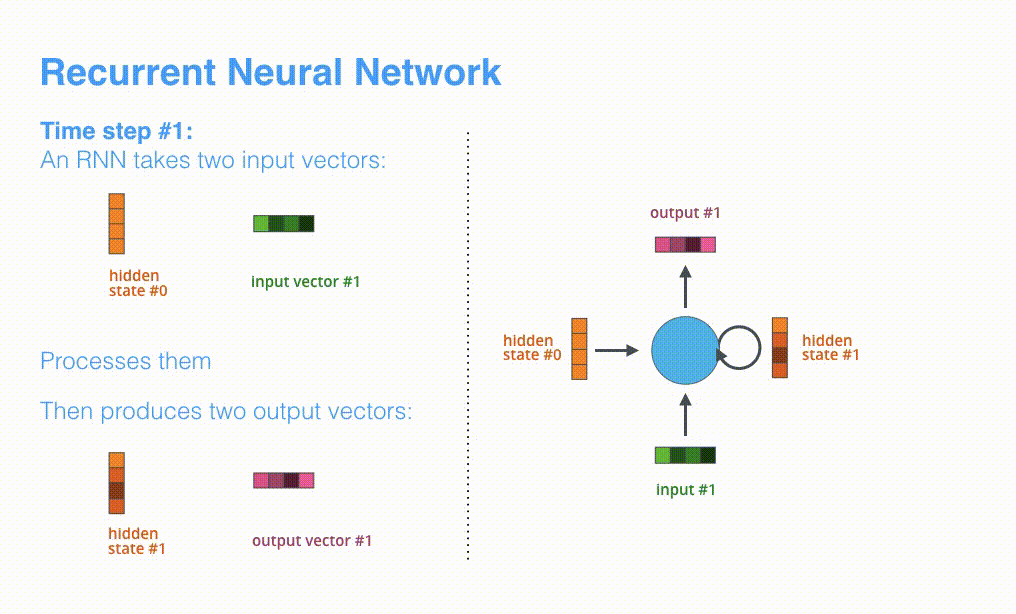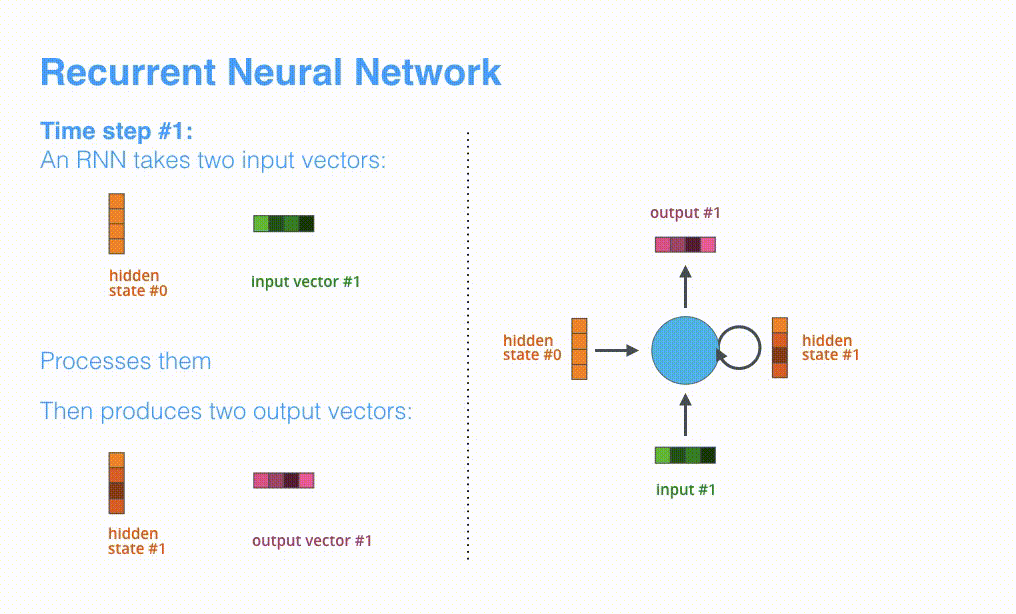
RNN menerima input dan keadaan tersembunyi pada setiap langkah waktu; dalam kasus Encoder, RNN menerima satu kata sebagai input. Kata yang diterima diubah menjadi vektor kata menggunakan algoritma yang disebut penyematan kata. Model penyisipan kata dapat berupa model yang dilatih secara independen atau model yang telah dilatih sebelumnya. Dimensi vektor penyematan biasanya 200 atau 300. Gambar di bawah ini menunjukkan vektor 4 dimensi.

Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
RNN menerima keadaan tersembunyi #0 dan vektor masukan # 1 pada langkah pertama, memprosesnya, dan mengeluarkan keadaan tersembunyi # 1 dan vektor masukan # 2.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Langkah waktu berikutnya menerima masukan #2 dan keadaan tersembunyi #1. Langkah waktu berikutnya menerima masukan #3 dan keadaan tersembunyi #2.
Model Encoder-Decoder RNN berperilaku seperti yang ditunjukkan pada gambar di bawah ini: keadaan tersembunyi terakhir yang diproses oleh Encoder (keadaan tersembunyi #3) diteruskan ke Decoder sebagai vektor konteks.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Decoder juga mempertahankan keadaan tersembunyi untuk setiap langkah waktu dan mengeluarkan kata menggunakan vektor konteks, keadaan tersembunyi, dan satu keluaran sebelumnya sebagai masukan.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Model Encoder-Decoder dengan Attention
Dalam model Encoder-Decoder, vektor konteks memiliki dimensi yang tetap. Artinya, vektor tersebut selalu dikonversi ke representasi vektor dengan panjang yang sama oleh Encoder. Untuk kalimat pendek, representasi vektor yang dikonversi dianggap dapat mempertahankan informasi dengan baik, tetapi semakin panjang kalimat, semakin sedikit informasi yang dapat masuk ke dalam representasi vektor. Oleh karena itu, semakin panjang kalimat, semakin tidak akurat representasi vektornya.
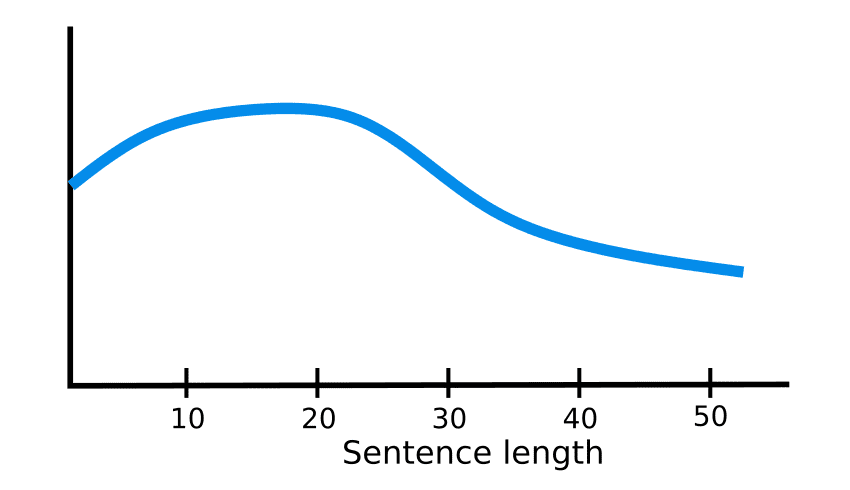
How Attention works in Deep Learning: understanding the attention mechanism in sequence models
Arsitektur Attention diciptakan sebagai solusi untuk masalah ini.
Pada Langkah Waktu 7, Attention memungkinkan Decoder untuk fokus pada pembelajar sebelum menghasilkan terjemahan bahasa Inggris. Melalui mekanisme yang memperkuat informasi dalam input, model dengan tambahan Attention berkinerja lebih baik.
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
Model Encoder-Decoder (seq2seq) dengan Attention berbeda dari model tradisional dalam dua hal berikut
- Encoder meneruskan lebih banyak informasi ke Decoder
- Decoder berfokus pada elemen input yang relevan pada setiap langkah waktu
Perbedaan pertama adalah bahwa Encoder meneruskan semua status tersembunyi ke Decoder, bukan meneruskan status tersembunyi terakhir.
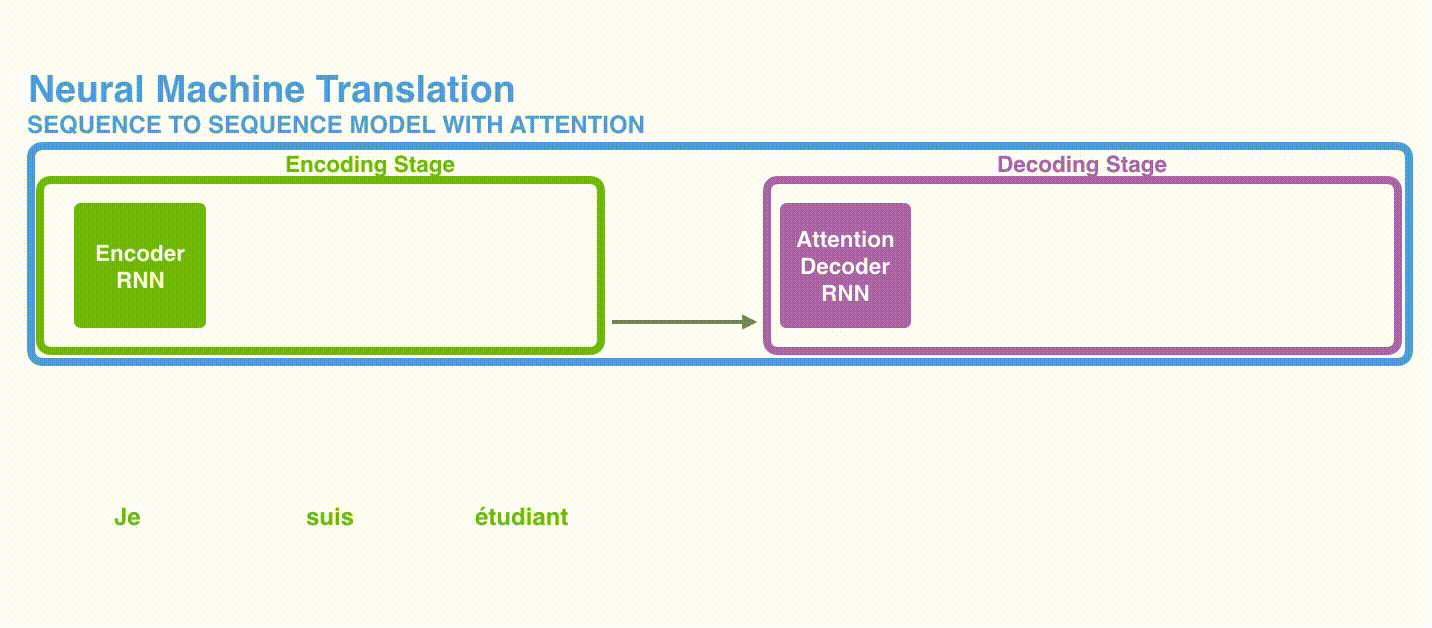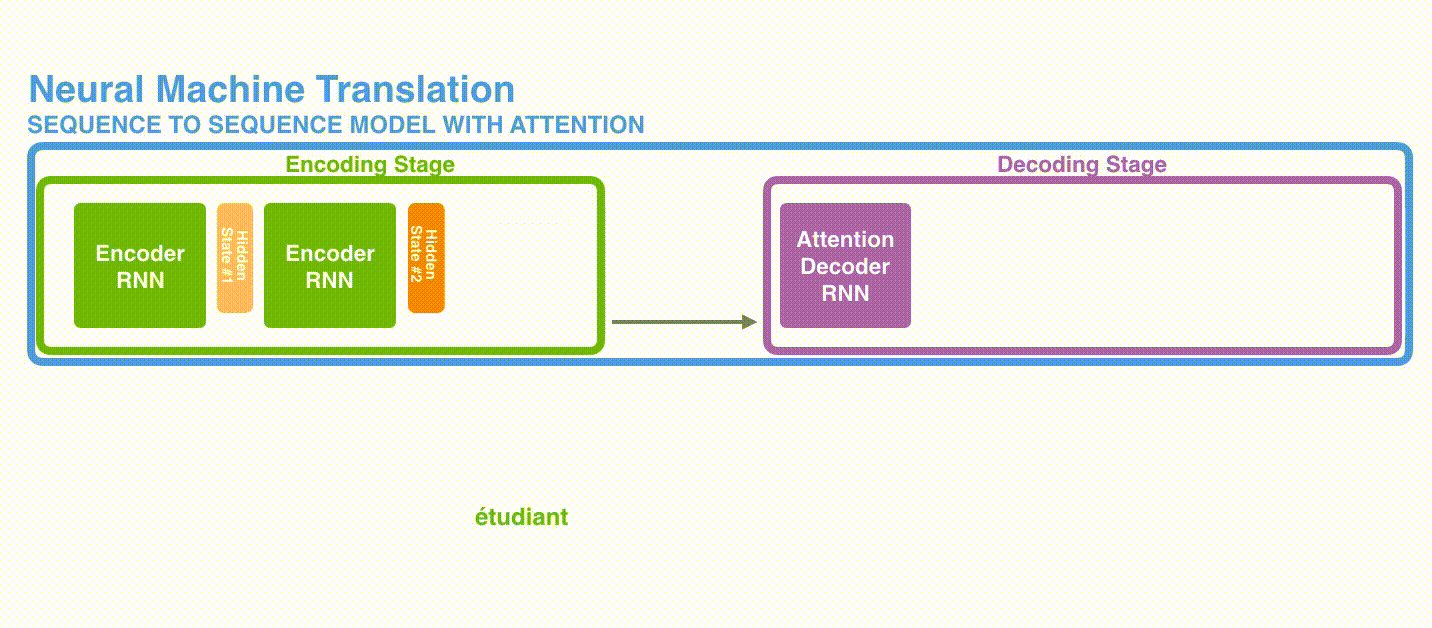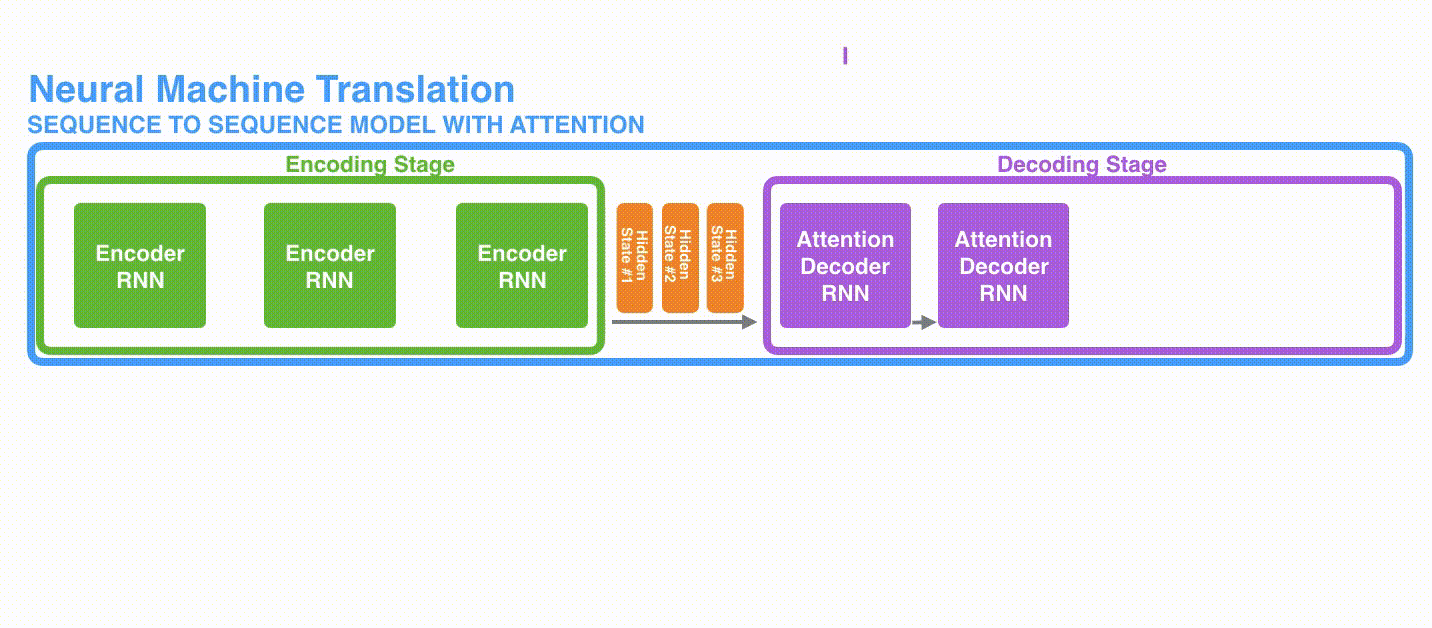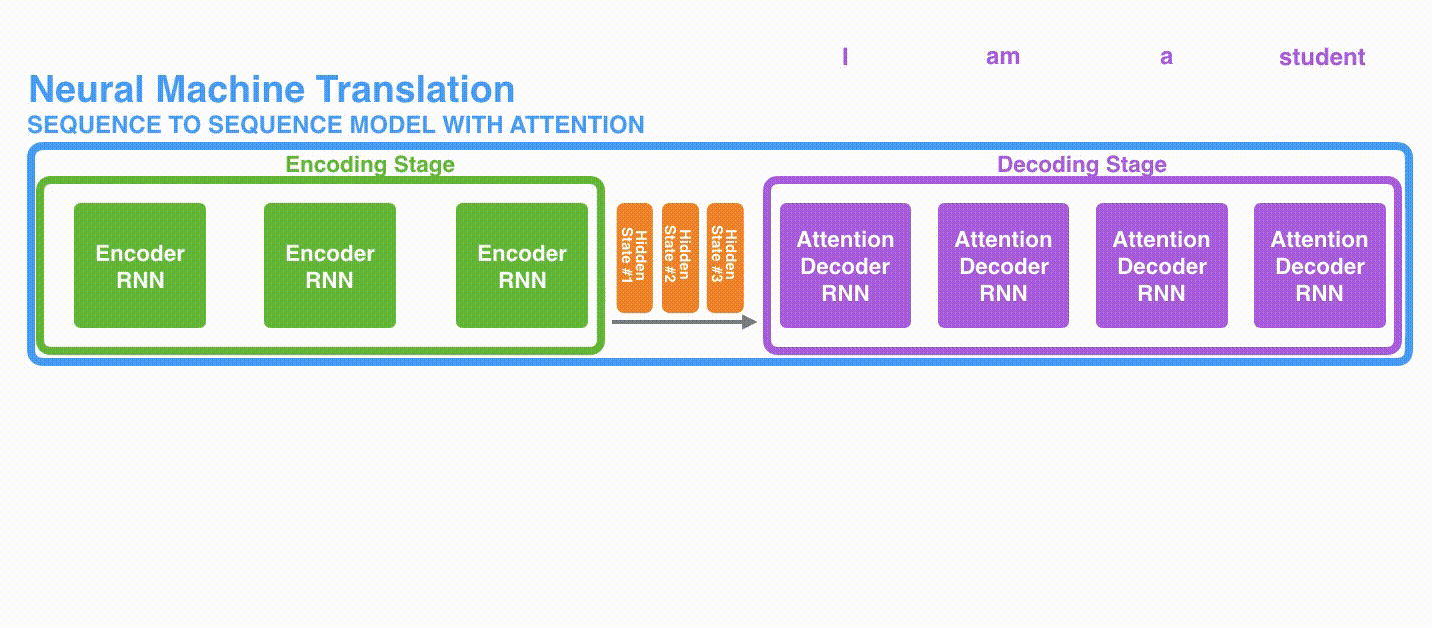
Perbedaan kedua adalah bahwa Decoder dengan Attention melakukan hal berikut pada setiap langkah waktu sebelum menghasilkan output
- melihat semua keadaan tersembunyi dari Encoder yang masuk
- berikan setiap keadaan tersembunyi sebuah skor
- beri bobot pada keadaan tersembunyi dengan mengalikan setiap keadaan tersembunyi dengan skornya melalui softmax (memperkuat keadaan tersembunyi dengan skor tinggi dan menenggelamkan keadaan tersembunyi dengan skor rendah)

Attention bekerja sebagai berikut:
- RNN decoder menerima token
<END>dan nilai awal dari keadaan tersembunyi - RNN menghasilkan keadaan tersembunyi yang baru (h4)
- Attention: Hasilkan vektor konteks (C4) pada setiap langkah waktu menggunakan semua keadaan tersembunyi dari Encoder dan keadaan tersembunyi yang dihasilkan oleh Decoder (h4)
- Gabungkan status tersembunyi Decoder (h4) dengan vektor konteks (C4)
- Melewatkan vektor gabungan melalui lapisan affine
- Keluaran dari lapisan affine adalah keluaran pada setiap langkah waktu
- Ulangi langkah di atas untuk setiap langkah waktu
Berikut ini adalah tampilan pada bagian mana dari input yang difokuskan pada setiap rentang waktu Decoder.
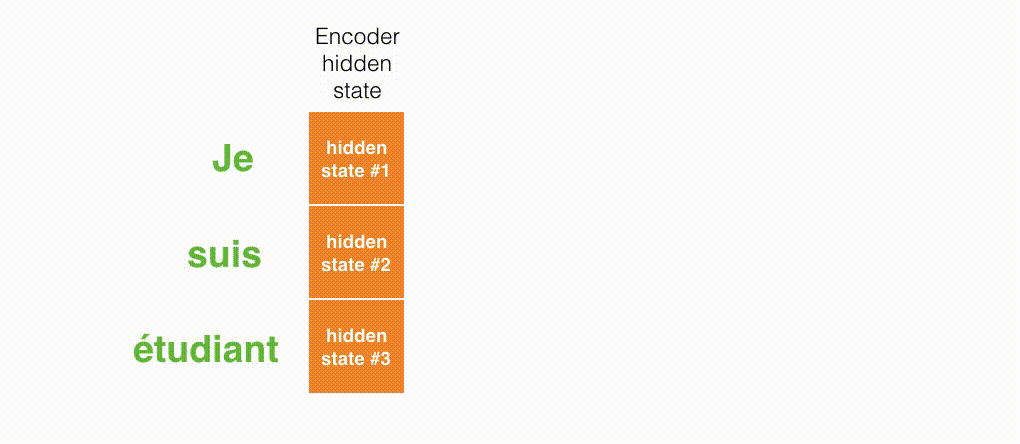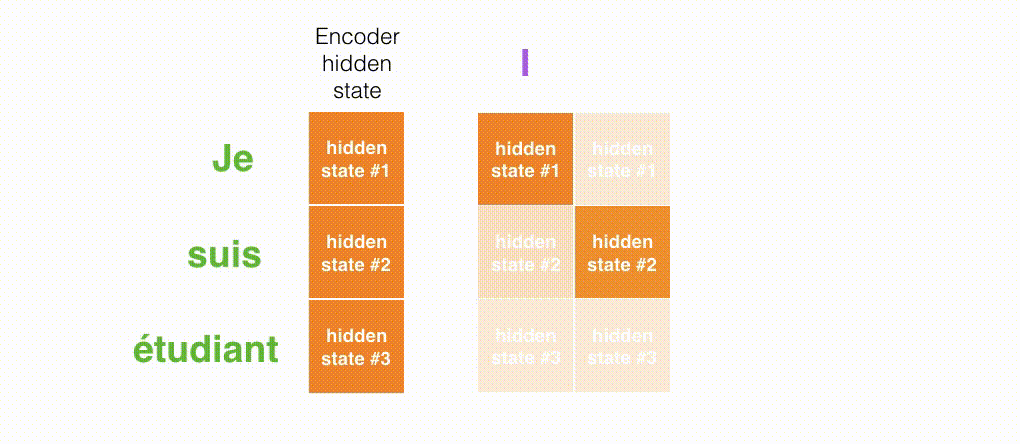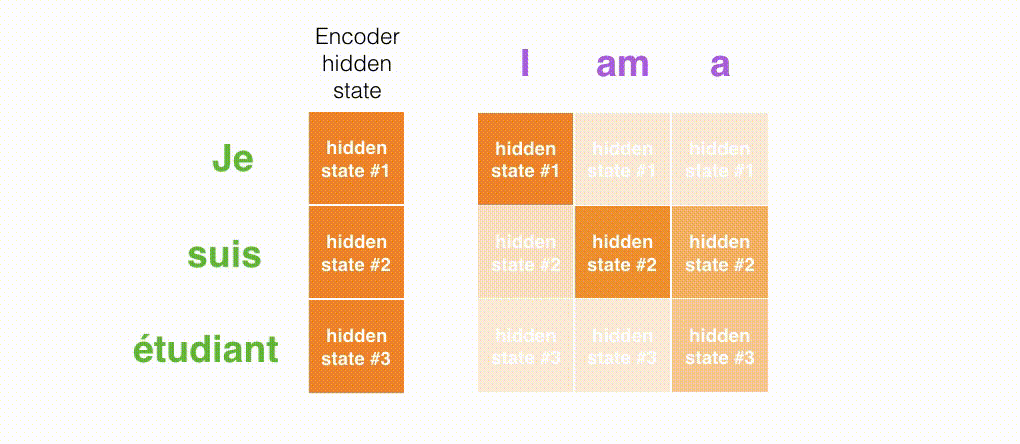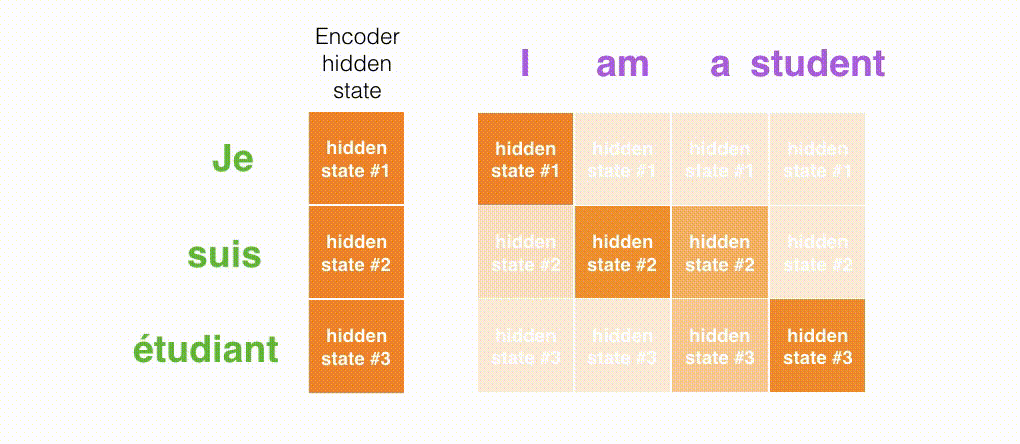
Gambar di bawah ini berasal dari makalah Neural Machine Translation by Jointly Learning to Align and Translate. Semakin putih warnanya, semakin banyak Attention yang difokuskan. Misalnya, saat menghasilkan kata "agreement", jelas bahwa Attention difokuskan pada kata input "accord".

Referenci

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS