


Apa itu RNN
RNN adalah singkatan dari Recurrent Neural Network. RNN adalah jenis jaringan saraf untuk memproses urutan data input, seperti data deret waktu atau bahasa alami, yang cocok untuk memproses data input kontinu, seperti data deret waktu atau bahasa alami.
RNN dapat mengambil urutan input, seperti data deret waktu, dan memprosesnya dengan mempertimbangkan ketergantungan temporal; RNN, tidak seperti jaringan saraf tradisional, dapat mempertahankan status untuk input mereka dan menyampaikan status sebelumnya ke langkah berikutnya. Hal ini memungkinkan RNN untuk menyimpan informasi masa lalu.
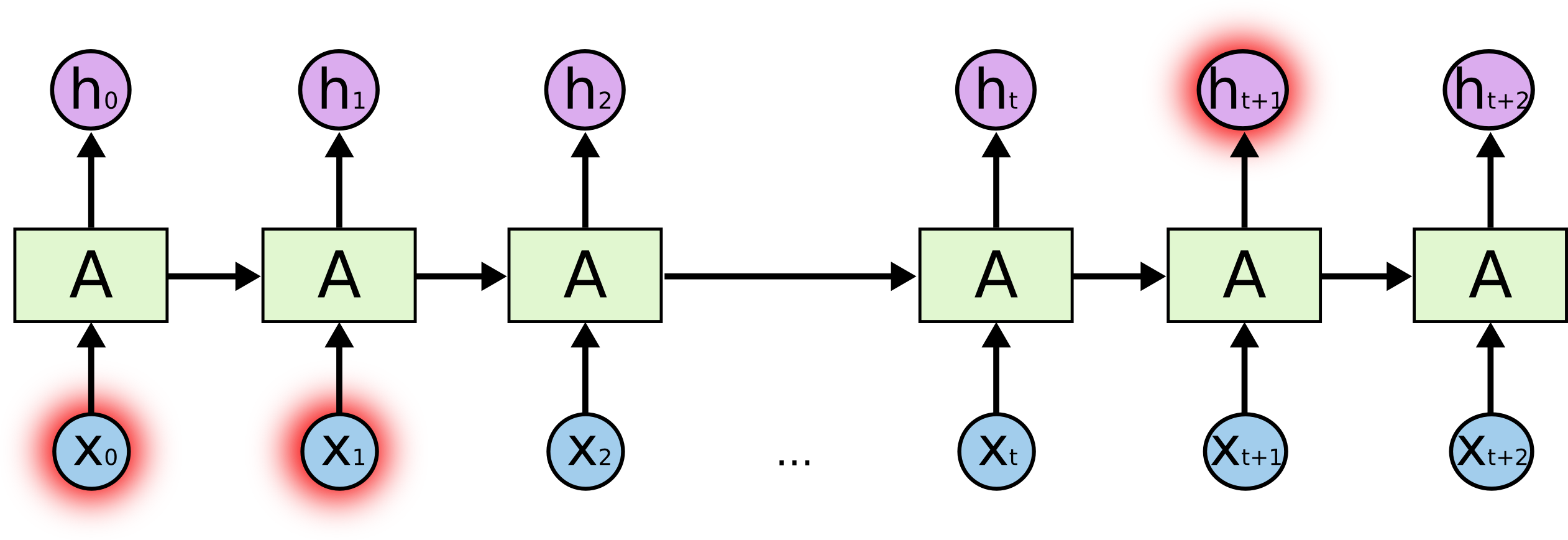
Dalam diagram RNN berikut, bagian dari output neural net pada waktu
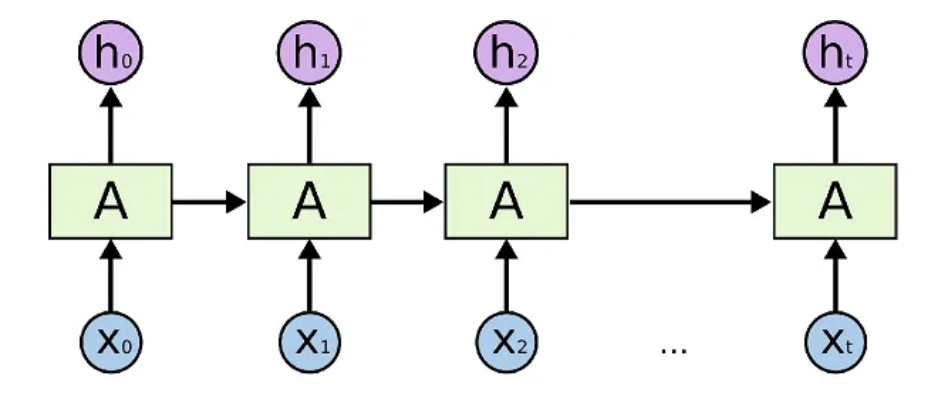
Arsitektur utama RNN meliputi RNN sederhana, LSTM, dan GRU. Arsitektur ini dapat menyimpan data input historis dan menggabungkannya dengan input saat ini untuk menghasilkan output. Arsitektur ini digunakan untuk tugas-tugas seperti prediksi data deret waktu, pemrosesan bahasa alami, pengenalan suara, dan keterangan gambar.
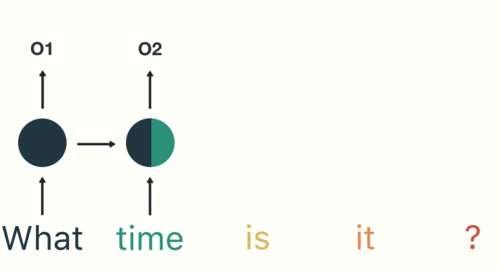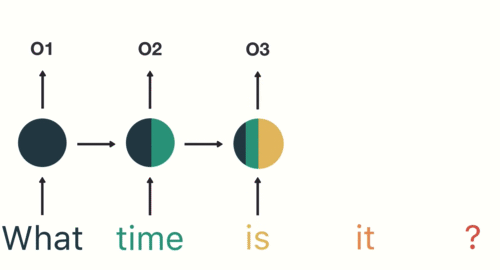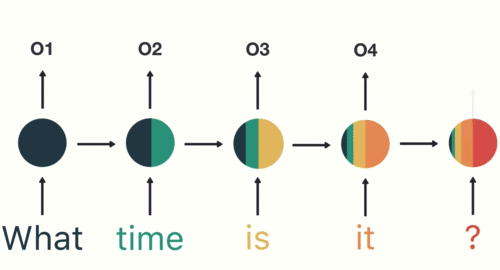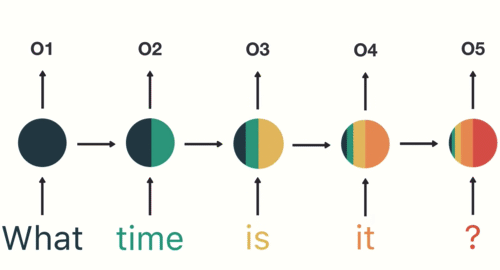
A simple overview of RNN, LSTM and Attention Mechanism
Keadaan tersembunyi
Keadaan tersembunyi adalah istilah yang digunakan dalam bidang-bidang seperti pembelajaran mesin dan pemrosesan bahasa alami untuk merujuk pada keadaan yang tidak teramati yang dipertahankan oleh model secara internal.
Dalam RNN, keadaan tersembunyi dihitung dari input masa lalu dan outputnya sendiri dan digunakan untuk memprediksi dan memproses informasi tentang input berikutnya. RNN mengubah urutan input menjadi vektor tunggal dan memperbarui keadaan tersembunyi berdasarkan vektor tersebut. Kehadiran hidden state membuat model lebih ekspresif untuk masalah yang lebih kompleks dan memungkinkan prediksi yang memperhitungkan konsep deret waktu.
Keadaan tersembunyi pada
Karena output dari neuron berulang pada langkah waktu tertentu
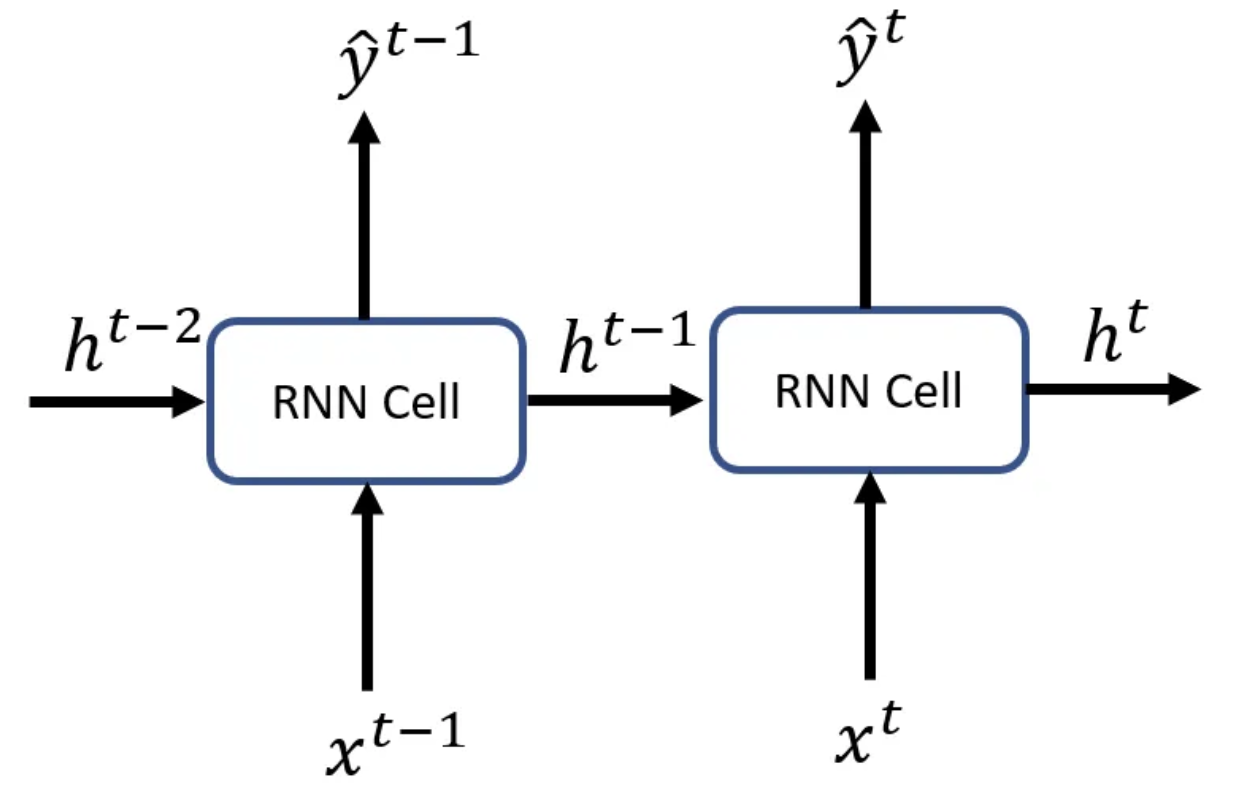
Perbedaan antara lapisan tersembunyi dan keadaan tersembunyi
Hidden state dan hidden layer adalah istilah yang digunakan dalam deep learning yang merupakan konsep yang mirip, tetapi memiliki arti yang sedikit berbeda.
Hidden state adalah istilah yang digunakan dalam model seperti RNN dan LSTM untuk menggambarkan keadaan internal, termasuk output pada waktu sebelumnya. dalam RNN, hidden state digunakan untuk memproses data deret waktu karena hal tersebut mempengaruhi input pada waktu berikutnya. Dalam LSTM, keadaan tersembunyi juga digunakan untuk menyimpan informasi masa lalu. Lapisan tersembunyi digunakan untuk memproses data deret waktu, karena mempengaruhi input pada waktu berikutnya.
Lapisan tersembunyi, di sisi lain, adalah istilah yang digunakan dalam jaringan saraf seperti multilayer perceptron (MLP) untuk merujuk pada lapisan perantara antara lapisan input dan output. Lapisan tersembunyi terdiri dari beberapa neuron, yang masing-masing menerima sinyal dari lapisan sebelumnya, menghitung jumlah tertimbang, dan menghasilkan output melalui fungsi aktivasi. Ketika ada beberapa lapisan tersembunyi, output dari setiap lapisan tersembunyi adalah input ke lapisan tersembunyi berikutnya atau lapisan output.
Dengan kata lain, hidden state dan hidden layer merupakan konsep yang merepresentasikan keadaan internal dalam machine learning, tetapi keduanya digunakan dalam konteks yang berbeda dan untuk tujuan yang berbeda. Hidden state digunakan untuk memproses data deret waktu, sedangkan hidden layer mewakili lapisan tengah dari jaringan saraf tiruan.
Tantangan RNN
Masalah utama yang membuat pelatihan RNN sangat lambat dan tidak efisien adalah masalah menghilangnya gradien Proses untuk jaringan saraf Feed Forward adalah sebagai berikut
- Keluarkan beberapa hasil dalam umpan maju
- gunakan hasil tersebut untuk menghitung nilai kerugian
- gunakan nilai kerugian tersebut untuk merambat balik dan menghitung gradien sehubungan dengan bobot
- menyebarkan kembali gradien ini sehubungan dengan bobot untuk menyempurnakan bobot dan meningkatkan kinerja jaringan
Karena bobot dimanipulasi sesuai dengan lapisan sebelumnya, gradien kecil cenderung menurun secara signifikan dengan setiap perubahan lapisan dan menjadi sangat dekat dengan nol, yang mengakibatkan pembelajaran yang buruk pada lapisan awal dan pembelajaran yang tidak efektif secara keseluruhan.
A simple overview of RNN, LSTM and Attention Mechanism
Thus, if the gradient disappears, the RNN will not be able to learn long-range dependencies across time steps well. In other words, even if the initial input of a sequence is important to the overall context, it will not be important. Therefore, it cannot learn long sequences, resulting in short-term memory.
Implementasi RNN
Berikut adalah beberapa contoh implementasi RNN menggunakan PyTorch dan Keras.
PyTorch
Berikut ini adalah contoh dasar penggunaan PyTorch untuk mendeskripsikan model RNN. Contoh ini menggunakan arsitektur RNN sederhana untuk melakukan tugas mengklasifikasikan kata.
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input):
hidden = torch.zeros(1, 1, self.hidden_size)
output, hidden = self.rnn(input, hidden)
output = self.fc(output[-1, :, :])
return output
Model ini mengambil kata-kata dengan ukuran input_size, melewatkannya melalui RNN dengan ukuran lapisan tersembunyi hidden_size, dan akhirnya menghasilkan keluaran klasifikasi dengan ukuran output_size. Kelas nn.RNN adalah lapisan RNN bawaan dalam PyTorch, dan nn.Linear mewakili lapisan yang terhubung sepenuhnya.
Metode forward melakukan penerusan pada input yang diberikan. Pertama, lapisan tersembunyi diinisialisasi. Kemudian, input dan keadaan tersembunyi saat ini diteruskan ke RNN untuk mendapatkan output dan keadaan tersembunyi yang baru. Akhirnya, hanya output dari langkah terakhir yang diambil dan dilewatkan melalui lapisan yang terhubung sepenuhnya untuk menghasilkan output klasifikasi.
Tautan di bawah ini adalah contoh lain.
Keras
Mari kita implementasikan RNN dengan Keras.
Pertama, buatlah data pelatihan untuk RNN. Buat data dengan menambahkan noise pada fungsi sinus dengan angka acak.
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x_data = np.linspace(-2*np.pi, 2*np.pi) # -2π to 2π
sin_data = np.sin(x_data) + 0.1*np.random.randn(len(x_data)) # add noise to sin func
plt.style.use('ggplot')
plt.figure(figsize=(12, 8))
plt.plot(x_data, sin_data)
plt.show()
n_rnn = 10 # num of time series
n_sample = len(x_data)-n_rnn # num of samples
x = np.zeros((n_sample, n_rnn)) # input
t = np.zeros((n_sample, n_rnn)) # label
for i in range(0, n_sample):
x[i] = sin_data[i:i+n_rnn]
t[i] = sin_data[i+1:i+n_rnn+1]
x = x.reshape(n_sample, n_rnn, 1)
t = t.reshape(n_sample, n_rnn, 1)
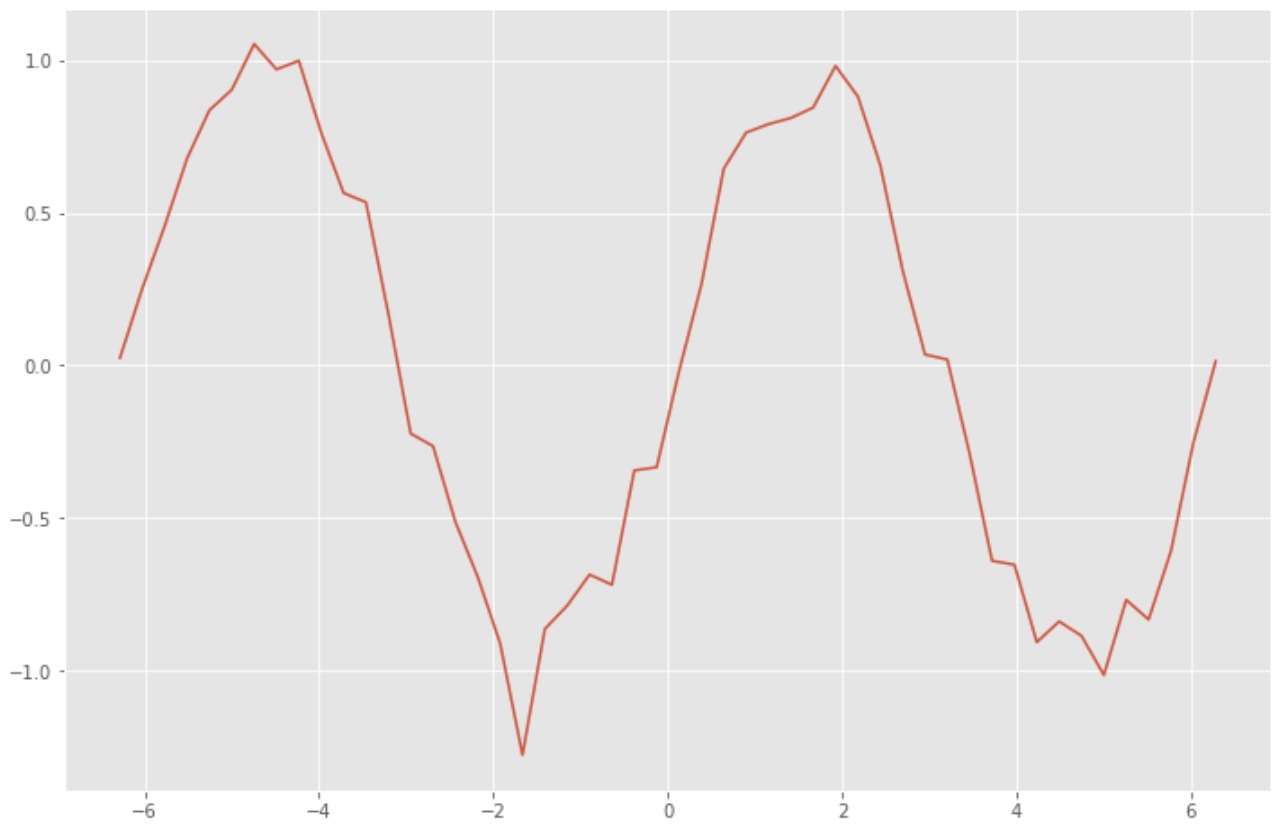
Membangun model RNN untuk memprediksi nilai masa depan dari data deret waktu sebelumnya.
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN
batch_size = 8 # batch size
n_in = 1 # num of neurons in input layer
n_mid = 20 # num of neurons in mid layer
n_out = 1 # num of neurons in output layer
model = Sequential()
model.add(SimpleRNN(n_mid, input_shape=(n_rnn, n_in), return_sequences=True))
model.add(Dense(n_out, activation="linear"))
model.compile(loss="mean_squared_error", optimizer="sgd")
print(model.summary())
>> Model: "sequential"
>> _________________________________________________________________
>> Layer (type) Output Shape Param #
>> =================================================================
>> simple_rnn (SimpleRNN) (None, 10, 20) 440
>>
>> dense (Dense) (None, 10, 1) 21
>>
>> =================================================================
>> Total params: 461
>> Trainable params: 461
>> Non-trainable params: 0
>> _________________________________________________________________
>> None
Pelatihan dilakukan dengan menggunakan model RNN yang telah dibangun.
history = model.fit(x, t, epochs=20, batch_size=batch_size, validation_split=0.1)
>> Epoch 1/20
>> 5/5 [==============================] - 2s 79ms/step - loss: 0.6561 - val_loss: 0.3590
>> Epoch 2/20
>> 5/5 [==============================] - 0s 13ms/step - loss: 0.4701 - val_loss: 0.2707
>> Epoch 3/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.3694 - val_loss: 0.2240
>> Epoch 4/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.3051 - val_loss: 0.1892
>> Epoch 5/20
>> 5/5 [==============================] - 0s 15ms/step - loss: 0.2613 - val_loss: 0.1696
>> Epoch 6/20
>> 5/5 [==============================] - 0s 13ms/step - loss: 0.2289 - val_loss: 0.1593
>> Epoch 7/20
>> 5/5 [==============================] - 0s 12ms/step - loss: 0.2058 - val_loss: 0.1501
>> Epoch 8/20
>> 5/5 [==============================] - 0s 12ms/step - loss: 0.1889 - val_loss: 0.1414
>> Epoch 9/20
>> 5/5 [==============================] - 0s 13ms/step - loss: 0.1750 - val_loss: 0.1345
>> Epoch 10/20
>> 5/5 [==============================] - 0s 14ms/step - loss: 0.1633 - val_loss: 0.1274
>> Epoch 11/20
>> 5/5 [==============================] - 0s 12ms/step - loss: 0.1540 - val_loss: 0.1233
>> Epoch 12/20
>> 5/5 [==============================] - 0s 12ms/step - loss: 0.1456 - val_loss: 0.1188
>> Epoch 13/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.1377 - val_loss: 0.1133
>> Epoch 14/20
>> 5/5 [==============================] - 0s 12ms/step - loss: 0.1317 - val_loss: 0.1097
>> Epoch 15/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.1256 - val_loss: 0.1063
>> Epoch 16/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.1199 - val_loss: 0.1025
>> Epoch 17/20
>> 5/5 [==============================] - 0s 13ms/step - loss: 0.1152 - val_loss: 0.1025
>> Epoch 18/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.1105 - val_loss: 0.0958
>> Epoch 19/20
>> 5/5 [==============================] - 0s 11ms/step - loss: 0.1065 - val_loss: 0.0932
>> Epoch 20/20
>> 5/5 [==============================] - 0s 15ms/step - loss: 0.1025 - val_loss: 0.0897
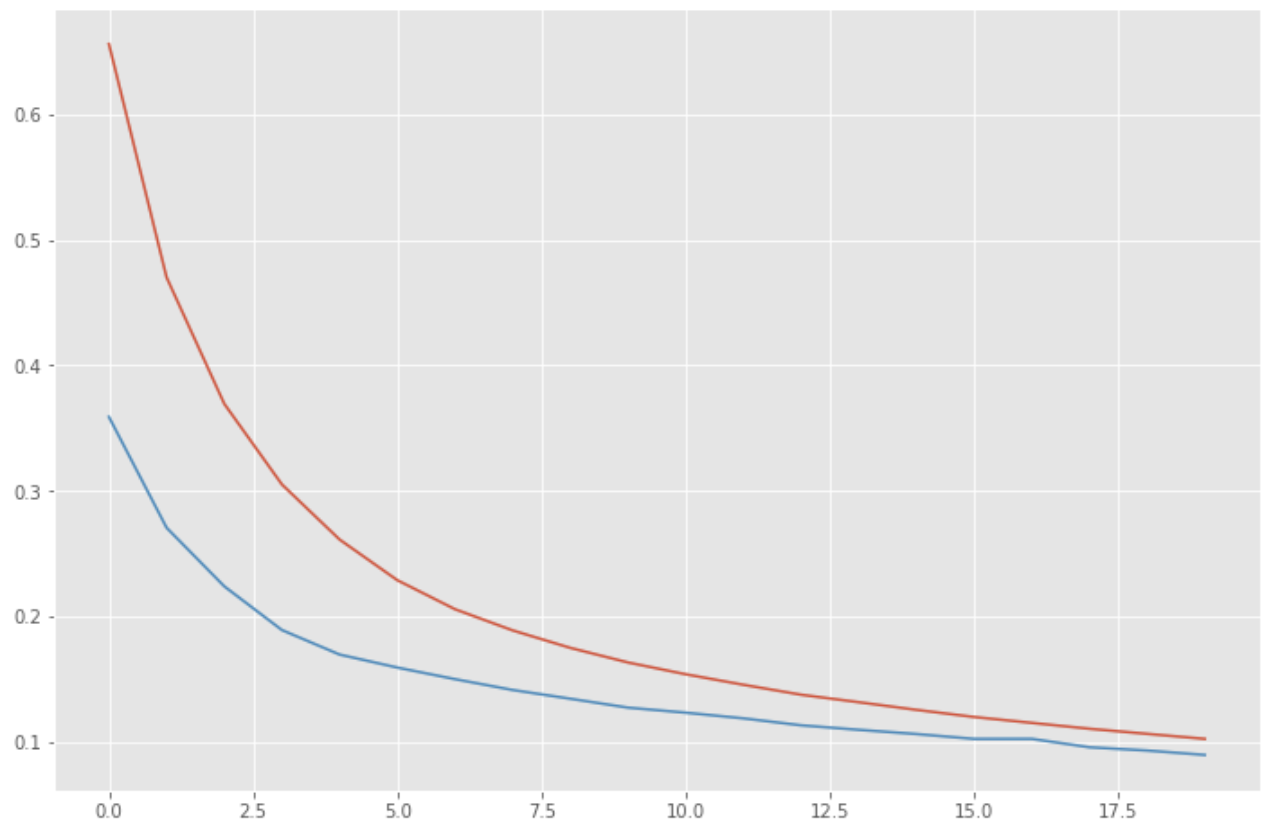
Periksa tren kesalahan.
loss = history.history['loss']
vloss = history.history['val_loss']
plt.figure(figsize=(12, 8))
plt.plot(np.arange(len(loss)), loss)
plt.plot(np.arange(len(vloss)), vloss)
plt.show()
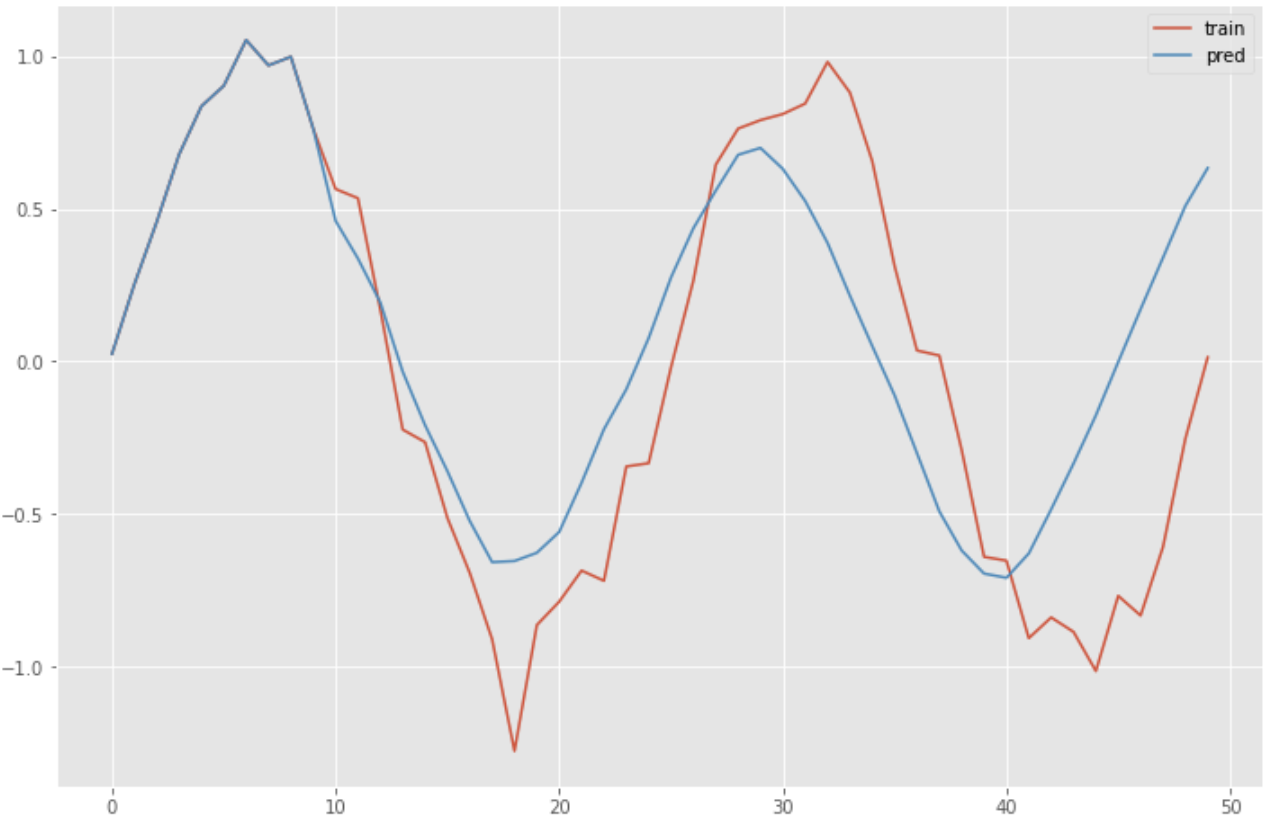
Prediksi dibuat dengan menggunakan model terlatih RNN.
predicted = x[0].reshape(-1)
for i in range(0, n_sample):
y = model.predict(predicted[-n_rnn:].reshape(1, n_rnn, 1))
predicted = np.append(predicted, y[0][n_rnn-1][0])
plt.figure(figsize=(12, 8))
plt.plot(np.arange(len(sin_data)), sin_data, label="training")
plt.plot(np.arange(len(predicted)), predicted, label="predicted")
plt.legend()
plt.show()
Referensi
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS