


What is word embedding
In order for a computer to recognize natural language, it is necessary to quantify words and documents, reflecting their properties and meanings. To quantify words, a word is represented as a vector of fixed length, which is called word embedding.
By representing words as vectors, for example, semantically similar words (such as "boat" and "ship") or semantically related words (such as "boat" and "water") become closer together in vector space. To capture semantic relatedness, documents are used as context; to capture semantic similarity, words are used as context.
The following methods have been proposed to represent words as vectors.
- One-hot vector
- Word2Vec
- fastText
- GloVe
- ELMo
- BERT
One-hot vector
One technique for vectorizing words is the one-hot vector, meaning a vector in which only one of all elements in the vector is 1 and the rest are all 0s.
For example, assign a vector to each word as follows
| Word | One-hot vector |
|---|---|
| I | |
| play | |
| basketball |
While this method can mechanically assign vectors, it has the following challenges:
- The dimension is too large
If there are 1 million words, the dimension is 1 million, which is computationally expensive. - Cannot encode meaning
Although it can determine if they are the same word or not, the vector does not include the meaning of the word.
Word embeddings
Word embedding is a method proposed to solve the problem of the huge dimensionality of vectors. Word embedding is a method of embedding a word in a vector space and viewing it as a single point in that space. Word embedding enables us to represent words as vectors that include their meanings, and to compute vectors between words with different meanings.
The following methods have been proposed for word embedding.
- Word2Vec
- fastText
- GloVe
- ELMo
- BERT
Word2vec
A method that overcomes the challenges of one-hot vectors, such as too large a dimension and the inability to encode meaning, is word2vec. Word2vec was released in 2013 by a research team at Google.
Word2vec is a set of two architectures: Skip-gram and CBOW (Continuous Bag-Of-Words).
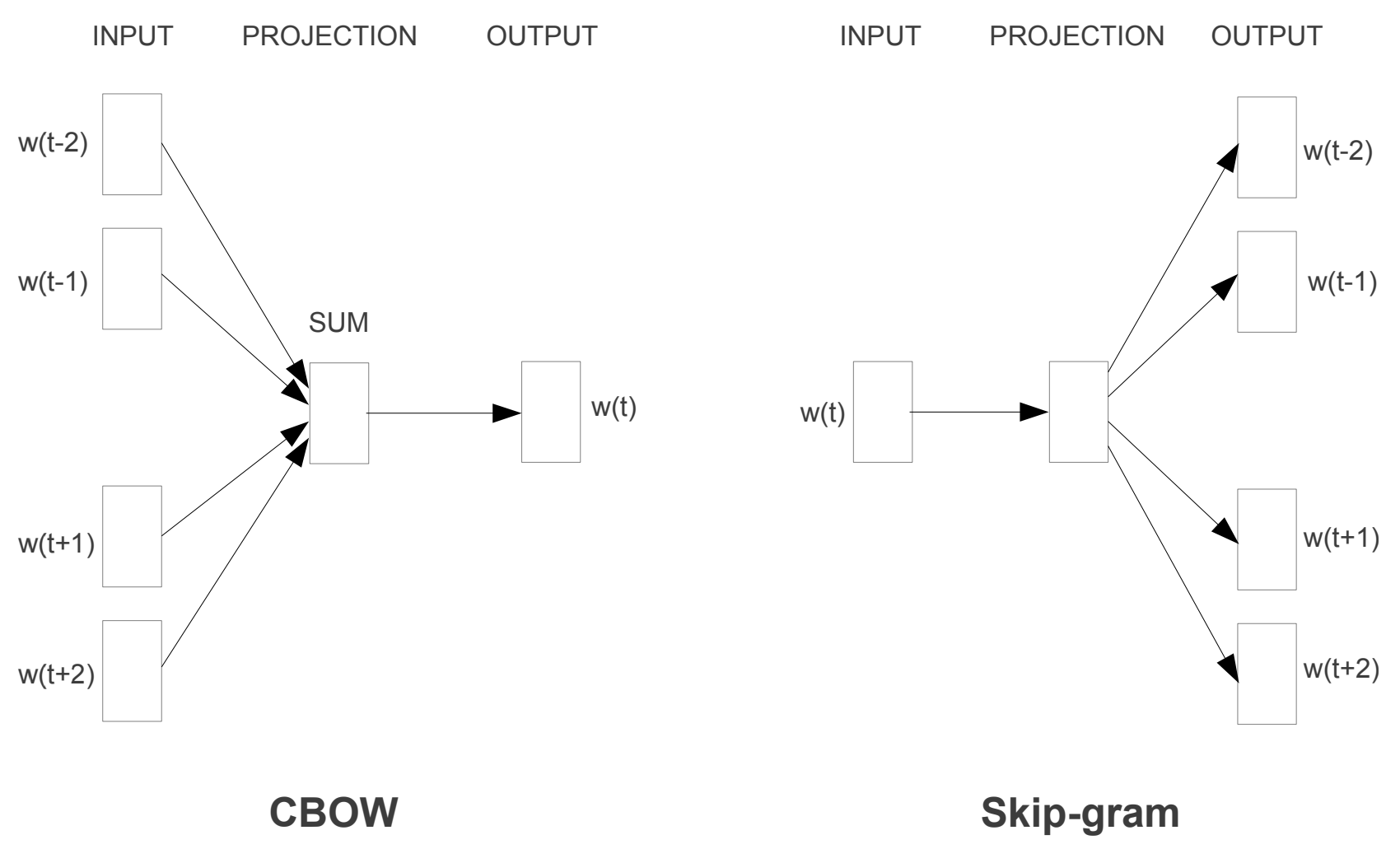
Efficient Estimation of Word Representations in Vector Space
| Architecture | Content |
|---|---|
| Skip-gram | Predicts surrounding words from a word |
| CBOW | Predicts certain words from surrounding words |
Word2vec can be easily implemented using a library called gensim.
import gensim
import gensim.downloader as gendl
corpus = gendl.load("text8")
model = gensim.models.Word2Vec(corpus, size=200, window=5, iter=10, min_count=1)
The word "tea" is represented by the following 200-dimensional vector.
model.wv['tea']
array([ 1.0338242 , -0.5497605 , 0.85095 , -1.9308733 , 0.02577365,
-0.04760092, -0.11763089, -0.88888925, 1.0477808 , -0.8593776 ,
-0.18352145, 0.44907862, 0.7292549 , -0.989956 , -0.31382865,
-0.326568 , 1.0326288 , -1.015825 , 1.1364412 , 2.2554684 ,
-0.46170548, -0.87449044, -0.92171615, 1.3384876 , 0.71479833,
1.5579652 , -0.79532343, -0.01963346, -0.09595346, 0.2980923 ,
-0.77367973, -0.21674974, -0.16363882, 0.7561723 , -0.9837275 ,
0.7700488 , 0.31943208, 1.1382285 , 0.7920231 , 0.4009208 ,
-0.12014329, 0.45739177, -0.8750017 , 0.9846294 , 1.0761734 ,
0.9916462 , -1.9893979 , 0.63205105, 1.6679561 , 0.23037305,
-0.09124516, 0.20652458, 2.5330052 , 0.46803576, -0.52581394,
-0.04794846, -0.8805762 , -0.19912305, 0.4005117 , -0.7323035 ,
1.1342882 , -2.2171109 , 2.2963653 , 0.30365032, 1.0434904 ,
-0.04669679, 0.4062761 , 0.5528872 , 0.47095624, -1.6239247 ,
1.557434 , -0.9619251 , 0.9666863 , -0.2241764 , -0.75970024,
1.8893499 , -1.0962995 , -1.0411807 , 0.4480955 , 0.5210397 ,
1.6454376 , 0.65203476, -0.04012801, -0.40056226, 2.852509 ,
-0.32553425, -0.20229222, 0.7245843 , -1.9557822 , -0.12104818,
0.28175735, -0.895713 , 0.58786476, 1.3742826 , -0.41480052,
0.07302658, 0.09337772, -0.34411722, -0.00724911, -0.9056035 ,
0.12258726, -0.15003532, 0.04658122, -2.2854378 , 0.28233293,
0.77172595, 1.3786261 , -1.2632967 , -1.426814 , -0.51365477,
-1.2197368 , 0.04790526, 0.62031317, 1.1224078 , -0.1804243 ,
0.49400517, -0.02745727, -1.0031232 , -0.10298221, 0.91482383,
0.98645395, 0.2342329 , 0.02064842, -0.33413368, -1.1859212 ,
1.1475669 , -1.0501987 , -0.7069197 , -0.12736289, 1.7058631 ,
-0.74710023, 0.48769948, -0.7129323 , 0.49225873, -1.3105804 ,
-2.1176062 , 0.5835398 , -0.01676613, 0.40714362, 1.6942219 ,
0.8474393 , -0.7914968 , 1.8470286 , 0.4587502 , -1.2789383 ,
0.48545036, -0.50352156, -0.04223507, -0.35754788, -0.60754126,
0.05735195, 0.32261458, -0.09268601, 0.702604 , 1.1815772 ,
0.17023656, -0.46019134, -1.0920937 , 0.26714015, -0.06735314,
-0.16602936, 0.6498549 , -0.35616133, 0.20689702, 0.7797428 ,
0.14901382, -0.71886814, 1.2617997 , 0.43995163, 1.0300183 ,
-0.81545556, -0.06593582, -0.23527797, -1.3182799 , 0.41896763,
1.8256154 , -0.04706338, -1.106722 , -0.47043508, -0.30877873,
0.27309516, -0.5845974 , 0.12854019, 0.44951373, 0.46647298,
-0.30743253, -0.7417909 , 1.0234478 , -1.4167138 , -0.6474553 ,
0.9093568 , 0.17825471, -1.3186976 , -1.7007768 , -1.4912218 ,
0.02761938, -1.5523437 , -0.30878946, -0.5883677 , 0.35952488],
dtype=float32)
len(model.wv['tea'])
200
Thus, Word2vec is able to reduce the vector representation of a word from millions of dimensions to 200 dimensions.
Words similar to the word "tea" are as follows.
model.wv.most_similar("tea")
[('coffee', 0.7221519947052002),
('beef', 0.6720874309539795),
('roast', 0.6600600481033325),
('spices', 0.653677225112915),
('drinks', 0.6486484408378601),
('sweets', 0.6478144526481628),
('cheese', 0.6444395780563354),
('pork', 0.6424828767776489),
('sausage', 0.6399528980255127),
('vegetables', 0.6373381614685059)]
Thus, Word2vec is able to understand the meaning of words.
See what happens when we combine the following words.
queen + man - woman
```python
model.wv.most_similar(positive=['queen', 'man'], negative=['woman'])
[('king', 0.5715309977531433),
('lord', 0.5021377801895142),
('crown', 0.4470388889312744),
('wight', 0.43937280774116516),
('prince', 0.43743711709976196),
('duke', 0.43583834171295166),
('regent', 0.4239676296710968),
('valdemar', 0.4121330976486206),
('scotland', 0.4113471210002899),
('vii', 0.3981912136077881)]
The result came back "king".
GloVe
Both architectures of Word2Vec are predictive and ignore the fact that words in some contexts occur more often than others. They also consider only local context and cannot capture global context.
GloVe (Global Vectors for Word Representation) uses global statistics on word co-occurrence to learn vector representations of words.
Below is sample code for a GloVe implementation.
!wget http://nlp.stanford.edu/data/glove.6B.zip
!unzip glove*.zip
import numpy as np
embeddings_dict = {}
with open("glove.6B.50d.txt", 'r') as f:
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], "float32")
embeddings_dict[word] = vector
embeddings_dict['water']
array([ 0.53507 , 0.5761 , -0.054351, -0.208 , -0.7882 , -0.17592 ,
-0.21255 , -0.14388 , 1.0344 , -0.079253, 0.27696 , 0.37951 ,
1.2139 , -0.34032 , -0.18118 , 0.72968 , 0.89373 , 0.82912 ,
-0.88932 , -1.4071 , 0.55571 , -0.017453, 1.2524 , -0.57916 ,
0.43 , -0.77935 , 0.4977 , 1.2746 , 1.0448 , 0.36433 ,
3.7921 , 0.083653, -0.45044 , -0.063996, -0.19866 , 0.75252 ,
-0.27811 , 0.42783 , 1.4755 , 0.37735 , 0.079519, 0.024462,
0.5013 , 0.33565 , 0.051406, 0.39879 , -0.35603 , -0.78654 ,
0.61563 , -0.95478 ], dtype=float32)
fastText
Word2Vec and GloVe had the challenge of not being able to encode unknown or non-lexical words. To address this challenge, Facebook proposed a model called fastText.
While Word2Vec learns a vector of individual words, fastText learns a word by dividing it into several subwords (n-grams).
For example, if we consider the word "what," using tri-grams (
"wh", "wha", "hat", "at"
Based on this concept, FastText can generate embedded vectors for words not included in the training text using their character embeddings. For example, an unknown word "googling" can now be split into "google" and "ing" to create a vector representation.
The following is sample code for a fastText implementation.
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip
!unzip wiki-news-300d-1M.vec.zip
import io
def load_vectors(word):
fin = io.open('wiki-news-300d-1M.vec', 'r', encoding='utf-8', newline='\n', errors='ignore')
for line in fin:
tokens = line.rstrip().split(' ')
if target_word == tokens[0]:
return [float(s) for s in tokens[1:]]
load_vectors('googling')
[-0.1151,
0.2652,
-0.13,
.
.
.
0.123,
0.2461,
0.0373]
ELMo
Word2vec, GloVe, and fastText all convert one word into one vector. Therefore, they cannot express polysemous words. For example, the word "bank" can refer not only to a financial institution but also to a river bank.
Therefore, a model was developed to address the contextual dependence of the meaning of a given word, ELMo.
ELMo does not generate a fixed vector representation for a single word. Instead, ELMo considers the entire sentence before generating an embedding for each word in the sentence. This context-sensitive embedding framework generates a vector representation of a word that takes into account the context in which the word is actually used.
ELMo uses a deep bi-directional LSTM language model, which allows for better understanding of previous words as well as the next word.
Below is a sample code of an ELMo implementation.
!pip install allennlp
from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json"
weight_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5"
elmo = Elmo(options_file, weight_file, 2, dropout=0)
sentences = ['By working faithfully eight hours a day, you may eventually get to be a boss and work twelve hours a day.'.split(' ')]
character_ids = batch_to_ids(sentences)
embeddings = elmo(character_ids)
print(embeddings['elmo_representations'])
[tensor([[[ 0.2935, 0.2494, -0.4810, ..., -0.2546, -0.2394, 0.2540],
[ 0.2875, 0.2179, -0.2757, ..., 0.0597, -0.1851, -0.2132],
[-0.4081, 0.1770, 0.5752, ..., -0.3343, 0.4417, 0.6988],
...,
[ 0.2734, 0.0159, -0.1510, ..., -0.0459, -0.0769, 0.8115],
[ 0.0628, -0.0689, -0.3339, ..., -0.1212, -0.0101, 0.0247],
[-0.0577, 0.8521, -0.3685, ..., 0.0323, -0.1151, 0.2783]]],
grad_fn=<CopySlices>), tensor([[[ 0.2935, 0.2494, -0.4810, ..., -0.2546, -0.2394, 0.2540],
[ 0.2875, 0.2179, -0.2757, ..., 0.0597, -0.1851, -0.2132],
[-0.4081, 0.1770, 0.5752, ..., -0.3343, 0.4417, 0.6988],
...,
[ 0.2734, 0.0159, -0.1510, ..., -0.0459, -0.0769, 0.8115],
[ 0.0628, -0.0689, -0.3339, ..., -0.1212, -0.0101, 0.0247],
[-0.0577, 0.8521, -0.3685, ..., 0.0323, -0.1151, 0.2783]]],
grad_fn=<CopySlices>)]
BERT
BERT is an MLP model published by Google on October 11, 2018. BERT is not only an algorithm for solving translation and classification problems, but also a word as a distributed representation of words. Specifically, within BERT there is a Masked Language Model (MLM), which estimates masked words, and within which the distributed representation of words is learned.
While ELMo learns words independently in the forward and reverse directions, BERT's MLM learns words simultaneously in the forward and reverse directions. Therefore, theoretically, BERT's distributed representation is more accurate than ELMo's.
Below is sample code for a BERT implementation.
!pip install transformers
import torch
from transformers import BertTokenizer, BertModel
model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
input_ids = torch.tensor(tokenizer.encode('The optimist sees the doughnut, the pessimist sees the hole.', add_special_tokens=True)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
print(last_hidden_states)
tensor([[[-0.4030, 0.3356, -0.0636, ..., -0.6573, 0.6247, 0.6181],
[-0.6247, 0.1251, -0.3543, ..., 0.0818, 1.1095, 0.0013],
[-0.1742, -0.0781, 0.4559, ..., -0.3268, 0.2127, 0.1130],
...,
[ 0.3077, 0.2755, -0.1591, ..., 0.3503, 0.3849, 0.6388],
[ 0.6037, 0.0777, -0.2810, ..., 0.1952, -0.3510, -0.3897],
[ 0.7766, 0.1315, -0.1458, ..., 0.1757, -0.4855, -0.3783]]],
grad_fn=<NativeLayerNormBackward0>)
Summary
The following table summarizes the methods of word vector representation.
| Method (Major category) | Method (Minor category) | Meaning understanding | Context understanding | Number of dimensions |
|---|---|---|---|---|
| One-hot representation | One-hot vector | × | × | 1M |
| Word embedding without taking context into account | Word2vec Glove fastText |
● | × | 100~300 |
| Word embedding wit taking context into account | ELMo BERT |
● | ● | 100~1000 |
References
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS