



What is Support Vector Regression (SVR)
Support Vector Regression (SVR) is a powerful and versatile machine learning algorithm derived from the well-known Support Vector Machines (SVM) for classification. The primary goal of SVR is to predict a continuous target variable, given a set of input features.
Key Concepts in SVR
SVR aims to find a function that approximates the relationship between input features and the target variable, with the objective of minimizing the prediction error within a specified tolerance margin. The main concepts in SVR include:
- Support vectors
These are the data points that lie on or outside the specified margin around the approximating function. Support vectors play a crucial role in defining the SVR model, as they determine the optimal parameters.
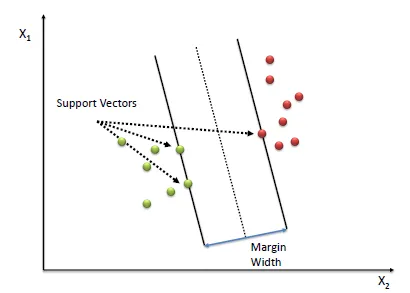
Machine Learning: Support Vector Regression (SVR)
- Hyperplane
A hyperplane is a flat subspace of one dimension less than the ambient space. In the context of SVR, the hyperplane is used to approximate the relationship between input features and the target variable. For linear SVR, the hyperplane represents a linear function, while for nonlinear SVR, the hyperplane exists in a higher-dimensional space obtained through kernel transformation.
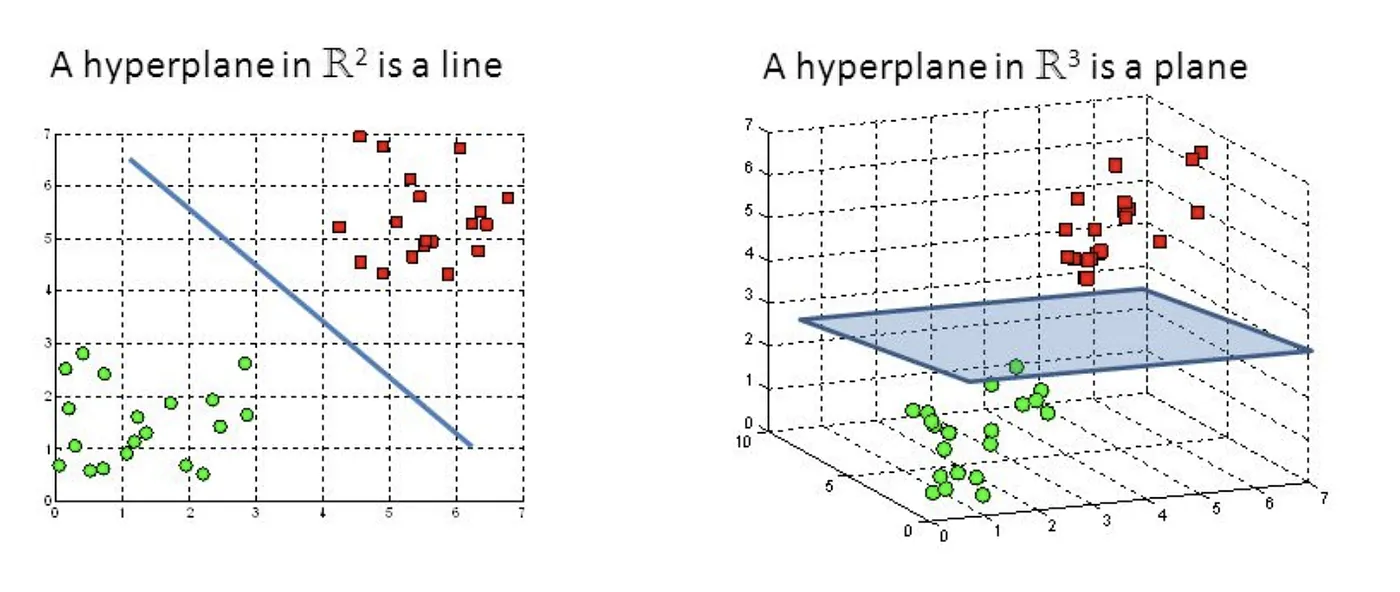
Machine Learning: Support Vector Regression (SVR)
- Margin
The margin is a tolerance zone around the approximating function (hyperplane) within which errors are considered acceptable. SVR aims to maximize the margin while keeping the prediction error within the specified tolerance. The width of the margin is determined by the parameter\epsilon
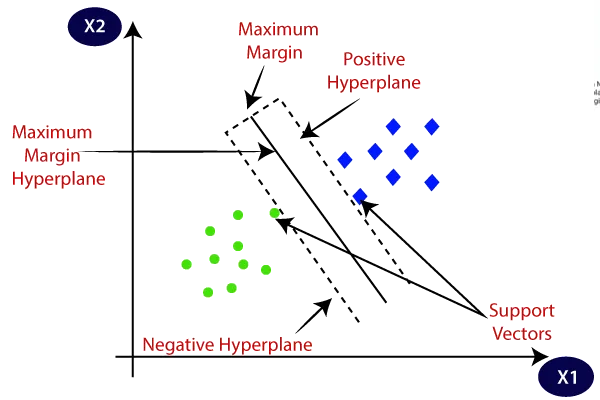
Machine Learning: Support Vector Regression (SVR)
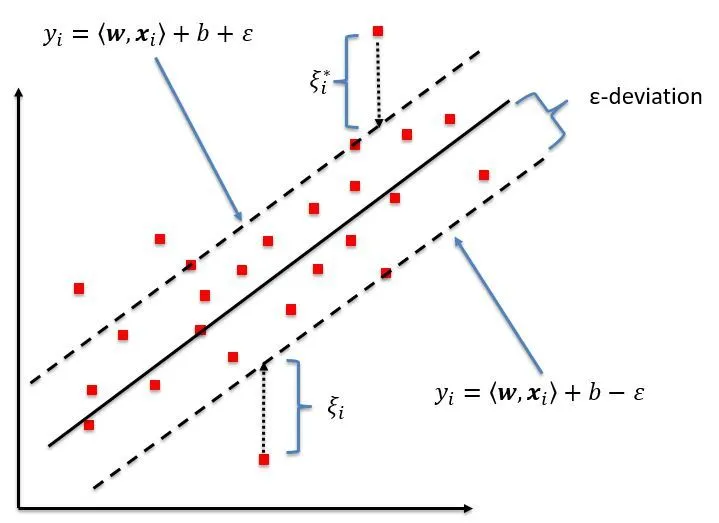
Machine Learning: Support Vector Regression (SVR)
- Kernel Trick
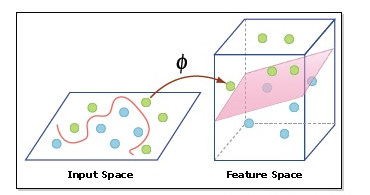
The kernel trick is a technique used in nonlinear SVR to find a nonlinear function that best approximates the relationship between input features and the target variable, while keeping the prediction error within the specified tolerance margin. The kernel trick involves mapping the input data to a higher-dimensional space using a kernel function, where a linear function can be used to approximate the nonlinear relationship. This allows SVR to solve nonlinear problems without explicitly transforming the input data, thus reducing computational complexity.
Support Vector Regression Tutorial for Machine Learning
Mathematical Foundations of SVR
Linear Regression vs. SVR
In linear regression, we try to find the best-fitting line by minimizing the squared error between the predicted values and the actual values. The linear function is given by:
Where
Optimization Problem
SVR aims to find the optimal weight vector
Objective Function
Where
Constraints
The constraints for the optimization problem are defined as follows:
Where
Loss Functions
SVR uses the
The
Dual Formulation
The dual formulation of the SVR problem is obtained by applying the Karush-Kuhn-Tucker (KKT) conditions to the Lagrangian function. This reformulation allows us to solve the optimization problem more efficiently and to incorporate nonlinear kernels.
Lagrange Multipliers
To derive the dual problem, we introduce Lagrange multipliers
Karush-Kuhn-Tucker (KKT) Conditions
Applying the KKT conditions to the Lagrangian function results in the dual problem, which involves maximizing the following dual objective function with respect to the Lagrange multipliers
Subject to the following constraints:
The dual formulation enables us to solve the SVR problem more efficiently, especially when using nonlinear kernels. By replacing the inner product
Kernel Trick
Kernel Functions
In nonlinear SVR, we use the kernel trick to map the input data to a higher-dimensional space, where a linear function can be used to approximate the nonlinear relationship. A kernel function is a similarity measure that computes the inner product between two input feature vectors in the transformed space:
Where
Popular Kernels in SVR
Some popular kernel functions used in SVR include:
- Linear kernel
- Polynomial kernel
- Radial basis function (RBF) kernel
- Sigmoid kernel
By replacing the inner product
Implementing SVR in Python
In this chapter, I will implement SVR using Python and the scikit-learn library. We will use the Iris dataset and visualize the support vectors with various kernel functions.
First, let's load the Iris dataset and prepare it for regression.
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris.data[:, :2] # Use the first two features.
y = iris.data[:, 2] # Use the third feature as the target.
# Split the dataset into a training set and a test set.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Now let's train the SVR model with various kernel functions.
from sklearn.svm import SVR
# Initialize SVR models with different kernels.
svr_linear = SVR(kernel='linear', C=1)
svr_poly = SVR(kernel='poly', C=1, degree=3)
svr_rbf = SVR(kernel='rbf', C=1, gamma='auto')
# Train the SVR models.
svr_linear.fit(X_train, y_train)
svr_poly.fit(X_train, y_train)
svr_rbf.fit(X_train, y_train)
To visualize the support vectors, we'll create a scatter plot of the data points and highlight the support vectors.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set(style="darkgrid")
def plot_support_vectors(svr_model, X, y, title, ax):
h = .02 # step size in the mesh
# Create a mesh to plot in.
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# Predict target values for the mesh.
Z = svr_model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour of the predictions.
ax.contourf(xx, yy, Z, alpha=0.8)
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', s=50)
ax.set_title(title)
ax.legend(*scatter.legend_elements())
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
plot_support_vectors(svr_linear, X_train, y_train, 'SVR with Linear Kernel', axes[0])
plot_support_vectors(svr_poly, X_train, y_train, 'SVR with Polynomial Kernel', axes[1])
plot_support_vectors(svr_rbf, X_train, y_train, 'SVR with RBF Kernel', axes[2])
plt.show()
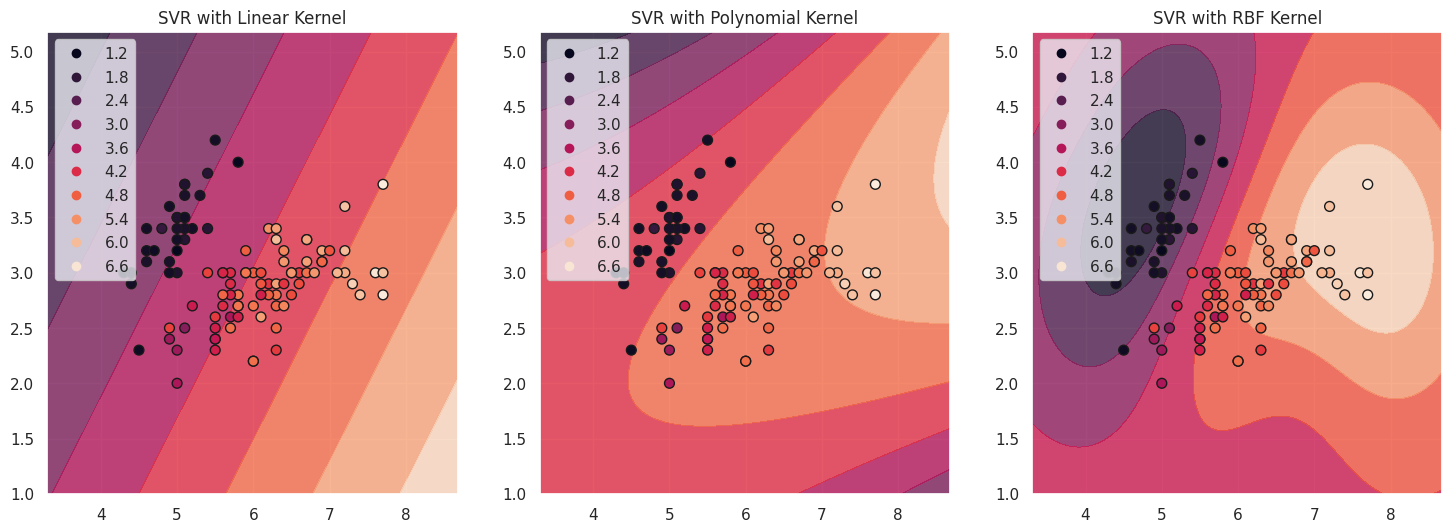
The support vectors are the data points that lie within or on the boundary of the margin. They are critical in determining the position of the hyperplane and have a significant influence on the model's predictions. In the plots above, the support vectors are represented by the points on the contour lines of the approximating functions for each kernel. These points play a key role in determining the shape of the decision boundary and the overall performance of the SVR model.
To evaluate the performance of our SVR models with different kernels, we can calculate their mean squared error (MSE) and R-squared scores on the test set.
from sklearn.metrics import mean_squared_error, r2_score
def evaluate_model(svr_model, X_test, y_test):
y_pred = svr_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
return mse, r2
mse_linear, r2_linear = evaluate_model(svr_linear, X_test, y_test)
mse_poly, r2_poly = evaluate_model(svr_poly, X_test, y_test)
mse_rbf, r2_rbf = evaluate_model(svr_rbf, X_test, y_test)
print("Linear kernel: MSE = {:.2f}, R^2 = {:.2f}".format(mse_linear, r2_linear))
print("Polynomial kernel: MSE = {:.2f}, R^2 = {:.2f}".format(mse_poly, r2_poly))
print("RBF kernel: MSE = {:.2f}, R^2 = {:.2f}".format(mse_rbf, r2_rbf))
Linear kernel: MSE = 0.31, R^2 = 0.91
Polynomial kernel: MSE = 0.54, R^2 = 0.84
RBF kernel: MSE = 0.30, R^2 = 0.91
This will output the mean squared error and R-squared scores for each of the SVR models. By comparing these metrics, we can determine which kernel provides the best fit for our data.
References















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS