

Introduction
The Tokyo Institute of Technology has created and maintains a collection of exercises on NLP called "NLP 100 Exercise".
In this article, I will find sample answers to "Chapter 5: Dependency parsing".
Environment settings
A file ai.ja.zip contains text extracted from an article on "Artificial Intelligence" on Japanese Wikipedia. Perform a dependency analysis on this text using tools such as CaboCha or KNP, and save the results in the file ai.ja.txt.parsed. Read this file and implement a program to answer the following questions.
!apt install -y curl file git libmecab-dev make mecab mecab-ipadic-utf8 swig xz-utils
!pip install mecab-python3
import os
filename_crfpp = 'crfpp.tar.gz'
!wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" \
-O $filename_crfpp
!tar zxvf $filename_crfpp
%cd CRF++-0.58
!./configure
!make
!make install
%cd ..
os.environ['LD_LIBRARY_PATH'] += ':/usr/local/lib'
FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU"
FILE_NAME = "cabocha.tar.bz2"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=\
$(wget --quiet --save-cookies /tmp/cookies.txt \
--keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- \
| sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
!tar -xvf cabocha.tar.bz2
%cd cabocha-0.69
!./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
!make
!make check
!make install
%cd ..
%cd cabocha-0.69/python
!python setup.py build_ext
!python setup.py install
!ldconfig
%cd ../
%cd cabocha-0.69
!make
!make check
!make install
%cd ../
!wget https://nlp100.github.io/data/ai.ja.zip
!unzip ai.ja.zip
!cabocha -f1 -o ai.ja.txt.parsed ai.ja.txt
!wc -l ./ai.ja.txt.parsed
>> 11744 ./ai.ja.txt.parsed
!head -15 ./ai.ja.txt.parsed
>> * 0 -1D 1/1 0.000000
>> 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
>> 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
>> EOS
>> EOS
>> * 0 17D 1/1 0.388993
>> 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
>> 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
>> * 1 17D 2/3 0.613549
>> ( 記号,括弧開,*,*,*,*,(,(,(
>> じん 名詞,一般,*,*,*,*,じん,ジン,ジン
>> こうち 名詞,一般,*,*,*,*,こうち,コウチ,コーチ
>> のう 助詞,終助詞,*,*,*,*,のう,ノウ,ノー
>> 、 記号,読点,*,*,*,*,、,、,、
>> 、 記号,読点,*,*,*,*,、,、,、
40. Read the parse result (words)
Implement Morph, a class that represents a morpheme. The class should have as member variables the surface form (
surface), the base form (base), the part-of-speech (pos), and the part-of-speech subdivision 1 (pos1). In addition, read the result of the dependency parsing (ai.en.txt.parsed), represent each sentence as a list ofMorphobjects, and display the morphological sequence of the first sentence of the description.
class Morph:
def __init__(self, line):
surface, attr = line.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[-3]
self.pos = attr[0]
self.pos1 = attr[1]
sentences = []
morphs = []
with open("./ai.ja.txt.parsed") as f:
for line in f:
if line[0] == "*":
continue
elif line != "EOS\n":
morphs.append(Morph(line))
else:
sentences.append(morphs)
morphs = []
for i in sentences[0]:
print(vars(i))
{'surface': '人工', 'base': '人工', 'pos': '名詞', 'pos1': '一般'}
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'}
41. Read the parse result (dependency)
40 plus implement the class
Chunk, which represents a phrase. The class shall have as member variables a list of morphemes (morphsobjects), a list of the destination phrase index numbers (dst), and a list of the source phrase index numbers (srcs). In addition, read the results of the dependency parsing of the input text, represent a single sentence as a list ofChunkobjects, and print the string of the opening explanatory phrase and its disengagement. Use the program you have created for the remaining problems in this chapter.
class Chunk:
def __init__(self, morphs, dst, chunk_id):
self.morphs = morphs
self.dst = dst
self.srcs = []
self.chunk_id = chunk_id
class Sentence:
def __init__(self, chunks):
self.chunks = chunks
for i, chunk in enumerate(self.chunks):
if chunk.dst not in [None, -1]:
self.chunks[chunk.dst].srcs.append(i)
class Morph:
def __init__(self, line):
surface, attr = line.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[-3]
self.pos = attr[0]
self.pos1 = attr[1]
sentences = []
chunks = []
morphs = []
chunk_id = 0
with open("./ai.ja.txt.parsed") as f:
for line in f:
if line[0] == "*":
if morphs:
chunks.append(Chunk(morphs, dst, chunk_id))
chunk_id += 1
morphs = []
dst = int(line.split()[2].replace("D", ""))
elif line != "EOS\n":
morphs.append(Morph(line))
else:
chunks.append(Chunk(morphs, dst, chunk_id))
sentences.append(Sentence(chunks))
morphs = []
chunks = []
dst = None
chunk_id = 0
for chunk in sentences[2].chunks:
print(f'chunk str: {"".join([morph.surface for morph in chunk.morphs])}\ndst: {chunk.dst}\nsrcs: {chunk.srcs}\n')
chunk str: 人工知能
dst: 17
srcs: []
chunk str: (じんこうちのう、、
dst: 17
srcs: []
chunk str: AI
dst: 3
srcs: []
chunk str: 〈エーアイ〉)とは、
dst: 17
srcs: [2]
.
.
.
42. Show root words
Extract all the text of the source and destination clauses in tab-delimited format. However, do not output punctuation marks.
sentence = sentences[2]
for chunk in sentence.chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentence.chunks[int(chunk.dst)].morphs if morph.pos != "記号"])
print(surf_org, surf_dst, sep='\t')
人工知能 語
じんこうちのう 語
AI エーアイとは
エーアイとは 語
計算 という
という 道具を
概念と 道具を
コンピュータ という
という 道具を
道具を 用いて
.
.
.
43. Show verb governors and noun dependents
When a clause containing a noun is related to a clause containing a verb, extract them in tab-delimited format. However, do not output punctuation marks.
sentence = sentences[2]
for chunk in sentence.chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"])
pos_noun = [morph.surface for morph in chunk.morphs if morph.pos == "名詞"]
pos_verb = [morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos == "動詞"]
if pos_noun and pos_verb:
print(surf_org, surf_dst, sep='\t')
道具を 用いて
知能を 研究する
一分野を 指す
知的行動を 代わって
人間に 代わって
コンピューターに 行わせる
研究分野とも される
44. Visualize dependency trees
Visualize the dependency tree of the given sentence as a directed graph. You can use Graphviz or similar software for visualization.
!apt install fonts-ipafont-gothic
!pip install pydot
import pydot_ng as pydot
from IPython.display import Image,display_png
edges = []
for chunk in sentences[2].chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"]) #文節のリストに係り先番号をindexに指定。その文節の形態素リストを取得
edges.append((surf_org, surf_dst))
img = pydot.Dot()
img.set_node_defaults(fontname="IPAGothic")
for s, t in edges:
img.add_edge(pydot.Edge(s, t))
img.write_png("./result44.png")
display_png(Image('./result44.png'))
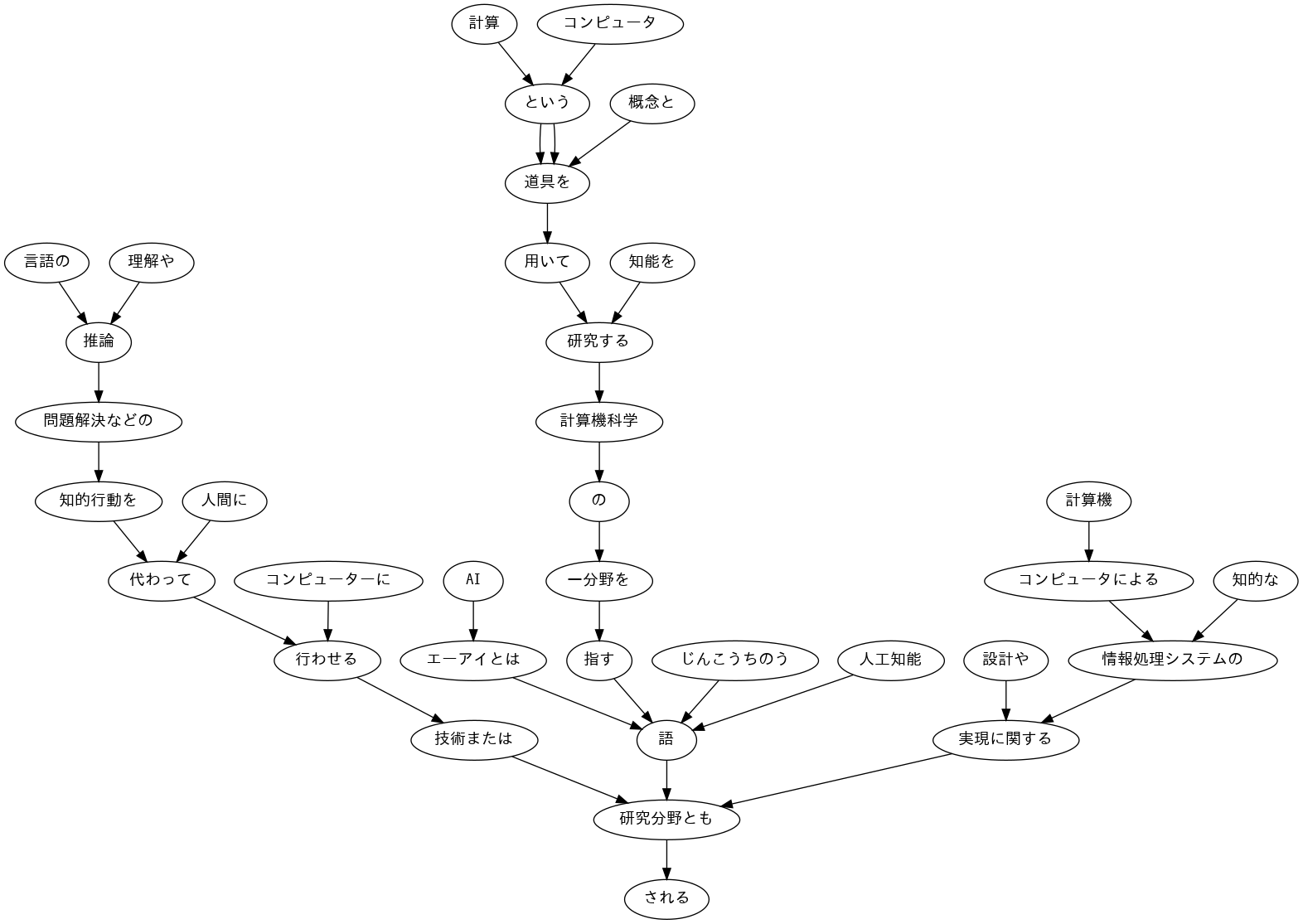
45. Triple with subject, verb, and direct object
We would like to investigate the possible cases of Japanese predicates, considering the sentences used in this study as a corpus. Consider a verb as a predicate and a case as a particle of the clause related to the verb, and output the predicate and case in tab-delimited format. However, the output should satisfy the following specifications.
In a clause containing a verb, take the left-most verb base form as the predicate.
The case of the particle of the predicate is the case of the predicate
If there is more than one particle (clause) associated with the predicate, list all particles in lexicographic order, separated by spaces
Save the output of this program to a file and check the following using UNIX commands.
Predicates and case patterns that occur frequently in the corpus
case patterns of the verbs "行う", "なる", and "与える" (in order of frequency of occurrence in the corpus)
with open("./result45.txt", "w") as f:
for i in range(len(sentences)):
for chunk in sentences[i].chunks:
for morph in chunk.morphs:
if morph.pos == "動詞":
particles = []
for src in chunk.srcs:
particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"]
if len(particles) > 0:
particles = sorted(list(set(particles)))
print(f"{morph.base}\t{' '.join(particles)}", file=f)
!cat ./result45.txt | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "行う" | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "なる" | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "与える" | sort | uniq -c | sort -nr | head -n 5
>> 49 する を
>> 19 する が
>> 15 する に
>> 15 する と
>> 12 する は を
>> 8 行う を
>> 1 行う まで を
>> 1 行う は を をめぐって
>> 1 行う は を
>> 1 行う に を
>> 4 なる に は
>> 3 なる が と
>> 2 なる に
>> 2 なる と
>> 1 異なる も
>> 1 与える に は を
>> 1 与える が に
>> 1 与える が など に
46. Expanding subjects and objects
Modify the program in 45 to output the predicate and case pattern followed by the term (the clause itself that is involved in the predicate) in tab-delimited format.
- The term should be a sequence of words from the clause that is involved in the predicate (no need to remove the trailing particle).
- If there are multiple clauses related to the predicate, they should be space-separated in the same order and with the same criteria as the particles.
with open("./result46.txt", "w") as f:
for i in range(len(sentences)):
for chunk in sentences[i].chunks:
for morph in chunk.morphs:
if morph.pos == "動詞":
particles = []
items = []
for src in chunk.srcs:
particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"]
items += ["".join([morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos != "記号"])]
if len(particles) > 0:
if len(items) > 0:
particles_form = " ".join(sorted(set(particles)))
items_form = " ".join(sorted(set(items)))
print(f"{morph.base}\t{particles_form}\t{items_form}", file=f)
!head -n 10 result46.txt
>> 用いる を 道具を
>> する て を 用いて 知能を
>> 指す を 一分野を
>> 代わる に を 人間に 知的行動を
>> 行う て に コンピューターに 代わって
>> せる て に コンピューターに 代わって
>> する と も 研究分野とも
>> れる と も 研究分野とも
>> 述べる で に の は 佐藤理史は 次のように 解説で
>> いる で に の は 佐藤理史は 次のように 解説で
47. Triple from the passive sentence
We want to focus only on cases where the verb wo case contains a subjunctive conjunction. 46 Modify the program to meet the following specifications.
- We only want to focus on cases where a clause consisting of "サ変接続名詞+を(助詞)" is related to a verb.
- Predicates should be "サ変接続名詞+を+ base form of 動詞", and if there is more than one verb in the clause, the left-most verb should be used.
- If there are multiple particles (clauses) related to the predicate, all particles are separated by spaces and arranged in lexical order.
- If there is more than one clause for the predicate, space-separate all terms (align with the order of particles)
with open('./result47.txt', 'w') as f:
for sentence in sentences:
for chunk in sentence.chunks:
for morph in chunk.morphs:
if morph.pos == '動詞':
for i, src in enumerate(chunk.srcs):
if len(sentence.chunks[src].morphs) == 2 and sentence.chunks[src].morphs[0].pos1 == 'サ変接続' and sentence.chunks[src].morphs[1].surface == 'を':
predicate = ''.join([sentence.chunks[src].morphs[0].surface, sentence.chunks[src].morphs[1].surface, morph.base])
particles = []
items = []
for src_r in chunk.srcs[:i] + chunk.srcs[i + 1:]:
case = [morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos == '助詞']
if len(case) > 0:
particles = particles + case
items.append(''.join(morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos != '記号'))
if len(particles) > 0:
particles = sorted(list(set(particles)))
line = '{}\t{}\t{}'.format(predicate, ' '.join(particles), ' '.join(items))
print(line, file=f)
break
!head -n 10 result47.txt
>> 注目を集める が を ある その後 サポートベクターマシンが
>> 経験を行う に を 元に 学習を
>> 学習を行う に を 元に 経験を
>> 進化を見せる て において は を 加えて 敵対的生成ネットワークは 活躍している 特に 生成技術において
>> 進化をいる て において は を 加えて 敵対的生成ネットワークは 活躍している 特に 生成技術において
>> 開発を行う は を エイダ・ラブレスは 製作した
>> 命令をする で を 機構で 直接
>> 運転をする に を 元に 増やし
>> 特許をする が に まで を 2018年までに 日本が
>> 特許をいる が に まで を 2018年までに 日本が
48. Extract paths from the root to nouns
For every clause containing all nouns in a sentence, extract the path from that clause to the root of the parse tree. However, the paths on the parse tree must satisfy the following specification.
- Each clause is represented by a morpheme sequence (in surface form).
- Each phrase of the path, from the start to the end of the path, is connected by "->".
sentence = sentences[2]
for chunk in sentence.chunks:
if "名詞" in [morph.pos for morph in chunk.morphs]:
path = ["".join(morph.surface for morph in chunk.morphs if morph.pos != "記号")]
while chunk.dst != -1:
path.append(''.join(morph.surface for morph in sentence.chunks[chunk.dst].morphs if morph.pos != "記号"))
chunk = sentence.chunks[chunk.dst]
print(" -> ".join(path))
人工知能 -> 語 -> 研究分野とも -> される
じんこうちのう -> 語 -> 研究分野とも -> される
AI -> エーアイとは -> 語 -> 研究分野とも -> される
エーアイとは -> 語 -> 研究分野とも -> される
計算 -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
概念と -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
コンピュータ -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
知能を -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
.
.
.
49. Extract the shortest path between two nouns
Extract the shortest disjunctive path connecting all noun-phrase pairs in a sentence. However, if the clause numbers of the noun phrase pairs are
and i ( j ), the disjunction paths must satisfy the following specification. i<j
As in problem 48, the path is a representation of each phrase (morpheme sequence in surface form) from the start clause to the end clause, joined by "->"
Noun phrases in clauses
and i are replaced by X and Y, respectively j Noun phrases in clauses
and i are replaced by X and Y, respectively > - The shape of the dependency path can be one of the following two ways. j If clause
is on the path from clause j to the root of the parse tree: display the path from clause i to clause i . j If other than the above, there is a common clause
on the path from clause k and clause i to the root of the parse tree: the path from clause j to clause i , the path from clause k to clause j , and the content of clause k are displayed by " | ". concatenated with " | ". k
from itertools import combinations
import re
sentence = sentences[2]
nouns = []
for i, chunk in enumerate(sentence.chunks):
if [morph for morph in chunk.morphs if morph.pos == "名詞"]:
nouns.append(i)
for i, j in combinations(nouns, 2):
path_i = []
path_j = []
while i != j:
if i < j:
path_i.append(i)
i = sentence.chunks[i].dst
else:
path_j.append(j)
j = sentence.chunks[j].dst
if len(path_j) == 0:
X = "X" + "".join([morph.surface for morph in sentence.chunks[path_i[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
Y = "Y" + "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "名詞" and morph.pos != "記号"])
chunk_X = re.sub("X+", "X", X)
chunk_Y = re.sub("Y+", "Y", Y)
path_XtoY = [chunk_X] + ["".join(morph.surface for n in path_i[1:] for morph in sentence.chunks[n].morphs)] + [chunk_Y]
print(" -> ".join(path_XtoY))
else:
X = "X" + "".join([morph.surface for morph in sentence.chunks[path_i[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
Y = "Y" + "".join([morph.surface for morph in sentence.chunks[path_j[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
chunk_X = re.sub("X+", "X", X)
chunk_Y = re.sub("Y+", "Y", Y)
chunk_k = "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "記号"])
path_X = [chunk_X] + ["".join(morph.surface for n in path_i[1:] for morph in sentence.chunks[n].morphs if morph.pos != "記号")]
path_Y = [chunk_Y] + ["".join(morph.surface for n in path_j[1: ]for morph in sentence.chunks[n].morphs if morph.pos != "記号")]
print(" | ".join([" -> ".join(path_X), " -> ".join(path_Y), chunk_k]))
X -> | Yのう -> | 語
X -> | Y -> エーアイとは | 語
X -> | Yとは -> | 語
X -> | Y -> という道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Yと -> 道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Y -> という道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Yを -> 用いて研究する計算機科学の一分野を指す | 語
X -> | Yを -> 研究する計算機科学の一分野を指す | 語
X -> | Yする -> 計算機科学の一分野を指す | 語
X -> | Y -> の一分野を指す | 語
X -> | Yを -> 指す | 語
.
.
.
References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS