
What is Ensemble Learning
Ensemble learning is a machine learning approach that combines multiple learning algorithms to improve predictive performance. By leveraging the strengths of different base models and minimizing their individual weaknesses, ensemble methods create robust and accurate predictors. The three main techniques in ensemble learning are Bagging, Boosting, and Stacking.
By understanding and implementing the three main ensemble learning techniques, Bagging, Boosting, and Stacking, you can create accurate, and stable machine learning models that can tackle complex real-world problems with ease.
Bias and Variance in Models
Bias and variance are essential concepts in machine learning, as they help us understand the trade-off between underfitting and overfitting. By understanding how bias and variance affect model performance, we can choose the most suitable models and ensemble learning techniques for different tasks.
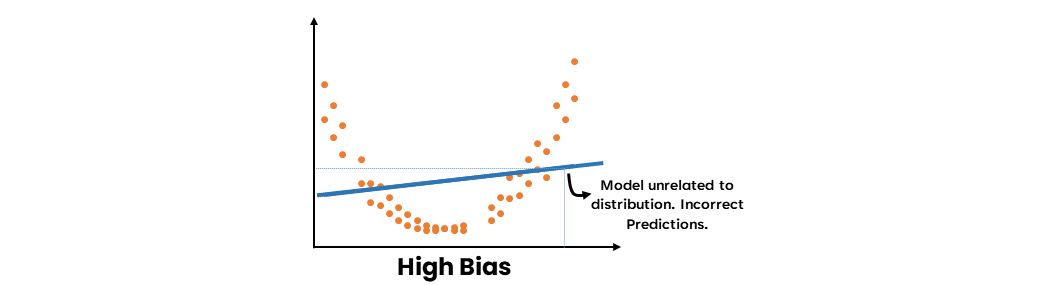
- High Bias
High bias refers to a model's inability to capture the underlying patterns in the data, leading to a poor fit. This can result from the model's simplicity or the use of inappropriate assumptions. When a model exhibits high bias, it tends to underfit the data, meaning that it does not capture the relationships between the input features and the target variable well enough.
Ensemble Learning Methods: Bagging, Boosting and Stacking
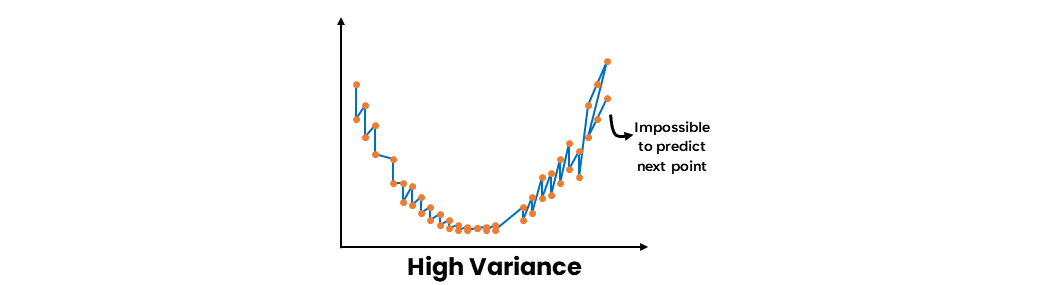
- High Variance
High variance refers to a model's sensitivity to small fluctuations in the training data, leading to overfitting. An overfit model performs well on the training data but fails to generalize to new, unseen data. When a model exhibits high variance, it captures not only the underlying patterns in the data but also the noise, which can negatively impact its performance on the test dataset.
Ensemble Learning Methods: Bagging, Boosting and Stacking
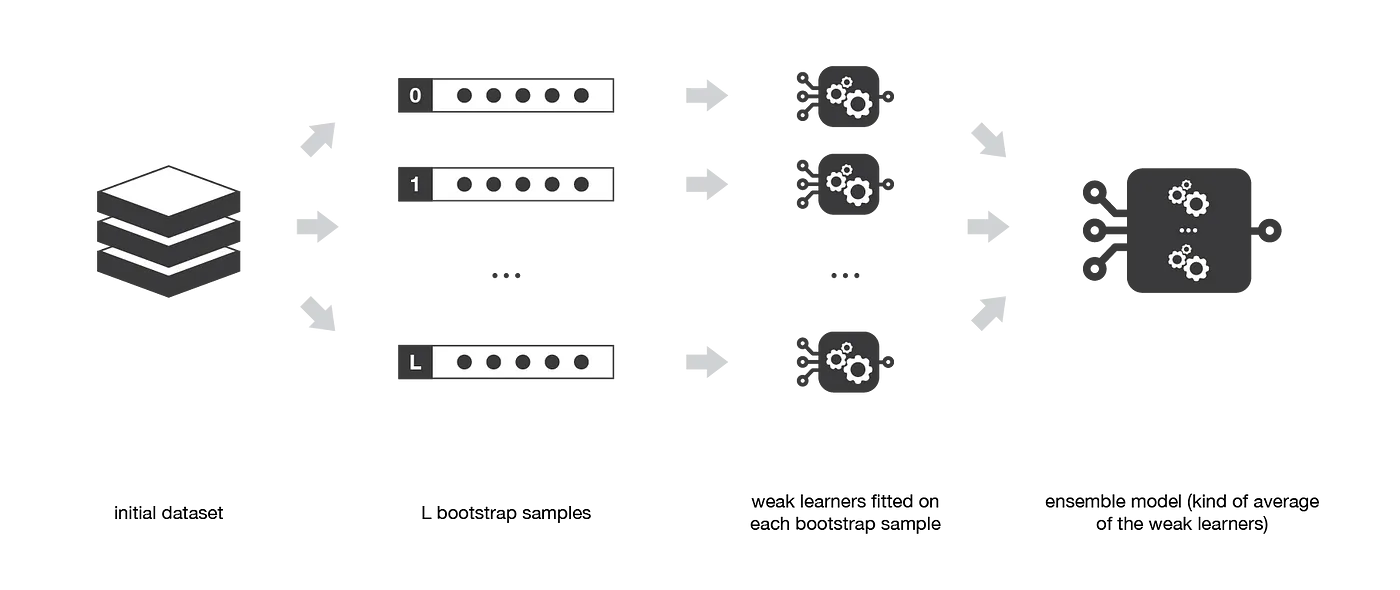
Bagging: Bootstrap Aggregating
Bagging, which stands for Bootstrap Aggregating, is an ensemble learning technique that aims to improve the performance of machine learning models by reducing the variance in their predictions. It works by training multiple base models independently on different subsets of the original dataset and aggregating their predictions through a majority vote (for classification) or averaging (for regression).
Ensemble methods: bagging, boosting and stacking
Bootstrap Samples
A bootstrap sample is a randomly selected subset of the original dataset obtained by sampling with replacement. In Bagging, each base learner is trained on a different bootstrap sample, which means that some data points may be included more than once, while others might not be included at all. This process introduces diversity among the base learners, which ultimately helps reduce the variance of the ensemble's predictions.

Ensemble Learning: Bagging, Boosting & Stacking
Algorithm and Implementation
The Bagging algorithm consists of the following steps:
- Create
nbootstrap samples of the original dataset by randomly sampling with replacement. - Train a base learner on each bootstrap sample independently.
- Aggregate the predictions from all base learners.
Here's an implementation of the Bagging algorithm:
- Initialize the number of base learners and the type of base learner (e.g., decision tree, logistic regression, etc.).
- For each base learner, create a bootstrap sample of the original dataset by sampling with replacement.
- Train the base learner on the corresponding bootstrap sample.
- Repeat steps 2-3 for all base learners.
- Obtain predictions from each base learner for the test dataset.
- Aggregate the predictions using majority vote (classification) or averaging (regression) to obtain the final prediction.
Advantages
- Bagging reduces overfitting by averaging the predictions of multiple base learners, leading to more accurate and stable models.
- It is effective in improving the performance of unstable learners like decision trees.
- Bagging can be easily parallelized, as each base learner is trained independently.
Limitations
- The choice of the base learner and the number of base learners can significantly impact the performance of the ensemble.
- Bagging might not be effective in reducing bias, as it primarily focuses on reducing variance.
- It can be computationally expensive, especially when working with large datasets or complex base learners.
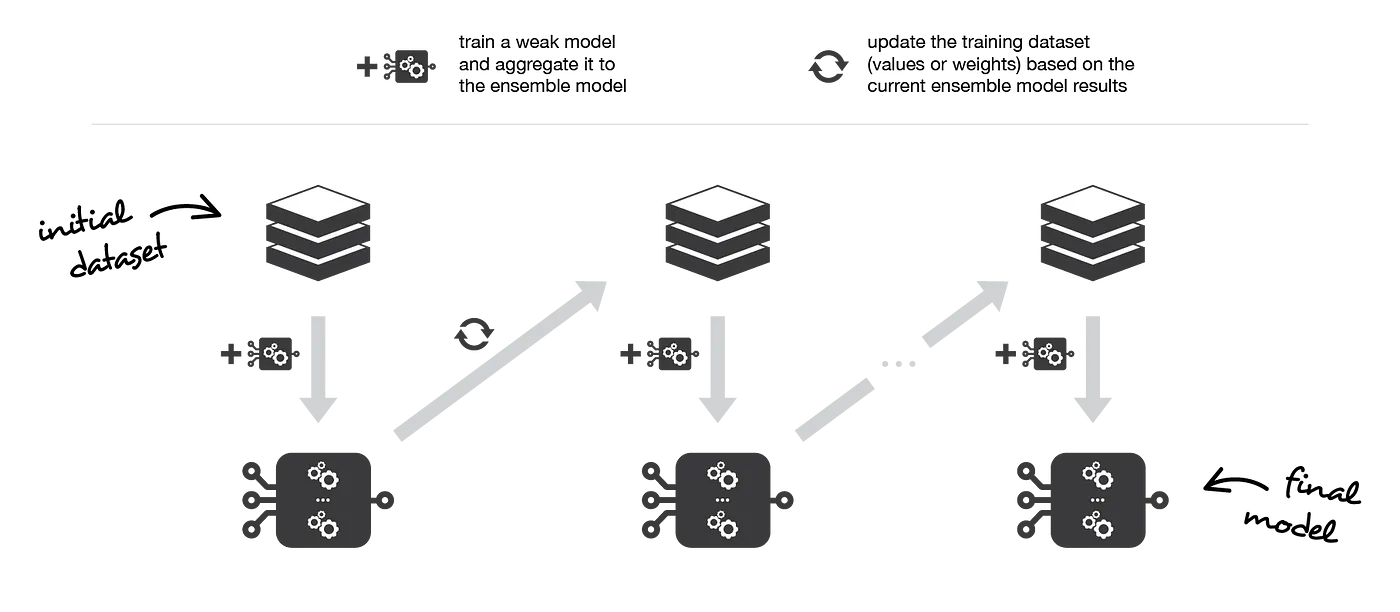
Boosting: Adaptive Ensemble Learning
Boosting is an ensemble learning technique that focuses on improving the accuracy of predictions by training a series of weak learners sequentially. Each learner in the sequence aims to correct the errors made by its predecessor, ultimately creating a strong model by combining their predictions. Boosting is particularly suitable for scenarios where base learners exhibit high bias or low accuracy, as it aims to increase predictive power by reducing bias.
Ensemble methods: bagging, boosting and stacking
Weak Learner
A weak learner is a relatively simple machine learning model that can generate predictions with an accuracy slightly better than random chance, but not as good as more sophisticated models. Weak learners are typically computationally efficient and easy to train but may have limited predictive power due to their simplicity. Examples of weak learners include decision stumps (single-level decision trees) or shallow decision trees.
In the context of ensemble learning techniques, such as boosting, weak learners are combined to form a strong learner, which can provide more accurate and reliable predictions. The ensemble approach leverages the strengths of multiple weak learners, compensating for their individual limitations, and ultimately enhancing the overall predictive performance of the combined model.
Key Algorithms: AdaBoost and Gradient Boosting
Two popular algorithms in the Boosting family are AdaBoost (Adaptive Boosting) and Gradient Boosting. Both algorithms share the common goal of improving the performance of weak learners; however, they differ in their approach to achieving this goal.
-
AdaBoost
AdaBoost is an iterative algorithm that updates the weights of training samples based on the errors made by the previous weak learner. At each iteration, a new weak learner is trained on the updated sample weights, focusing on the misclassified samples from the previous learner. -
Gradient Boosting
Gradient Boosting extends the concept of boosting by optimizing a loss function using gradient descent. At each iteration, a new weak learner is added to the ensemble, and the weights of this learner are adjusted to minimize the overall loss function.
Algorithm and Implementation
Here's an overview of the Boosting algorithm:
- Initialize the weights of training samples uniformly.
- Train a weak learner on the weighted dataset.
- Update the sample weights based on the errors made by the weak learner.
- Repeat steps 2-3 for the desired number of iterations.
- Combine the weak learners' predictions with a weighted sum or majority vote.
To implement the Boosting algorithm:
- Choose the number of weak learners and the type of base learner (e.g., decision tree, logistic regression, etc.).
- Initialize the sample weights uniformly.
- For each weak learner:
- Train the base learner on the weighted dataset.
- Calculate the error rate of the base learner.
- Update the sample weights based on the error rate.
- Normalize the sample weights.
- Obtain predictions from each weak learner for the test dataset.
- Combine the predictions using a weighted sum (regression) or majority vote (classification) to obtain the final prediction.
Advantages
- Boosting can significantly improve the accuracy of weak learners by focusing on the difficult samples and reducing bias.
- It is less prone to overfitting than Bagging, as it trains weak learners sequentially rather than in parallel.
- Boosting can be applied to various base learner types, making it a versatile ensemble learning technique.
Limitations
- Boosting can be sensitive to noise and outliers, as it tends to focus on difficult samples.
- It can be computationally expensive, particularly when using a large number of weak learners or complex base learners.
- The choice of the number of weak learners and the type of base learner can significantly impact the performance of the ensemble.
Stacking: Combining Learners to Improve Predictions
Stacking, also known as Stacked Generalization, is an ensemble learning technique that combines multiple base learners by training a meta-model on their predictions. The objective is to exploit the strengths of each base learner while mitigating their weaknesses. By learning from the predictions of multiple base learners, the meta-model can often achieve higher predictive accuracy than any individual model alone.
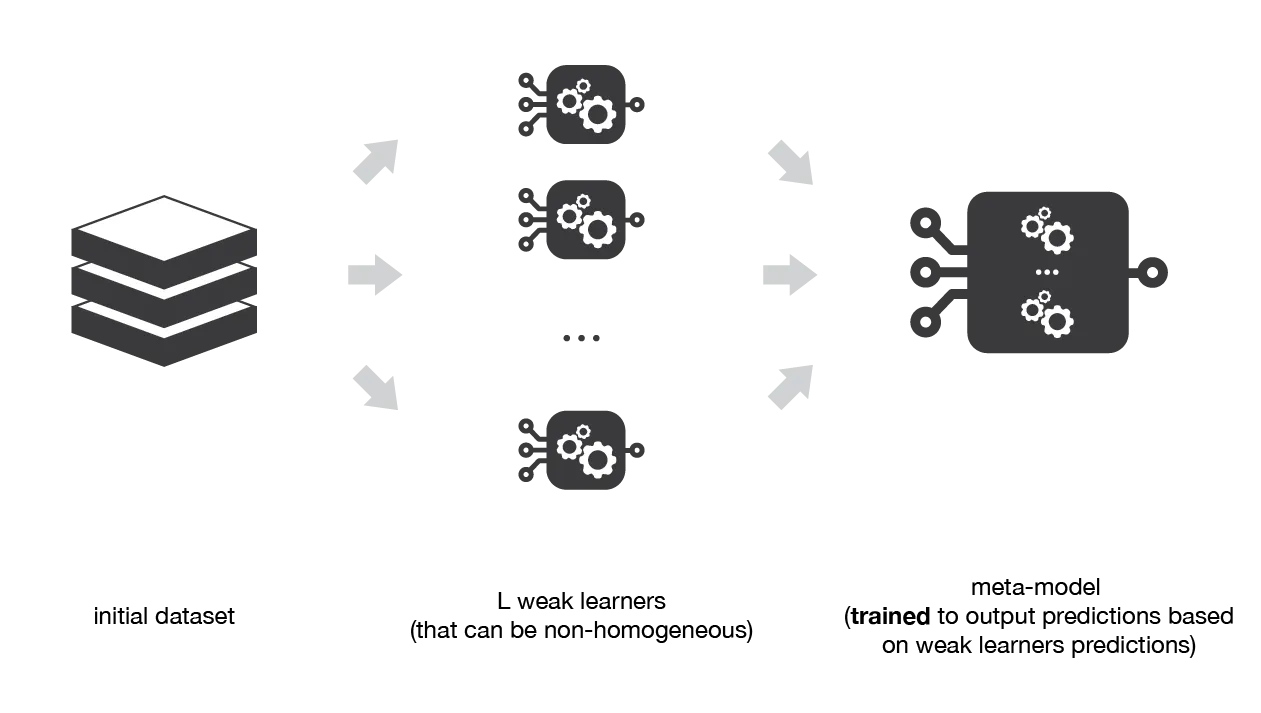
Ensemble methods: bagging, boosting and stacking
Algorithm and Implementation
The Stacking algorithm can be broken down into the following steps:
- Split the dataset into a training set and a validation set.
- Train base learners on the training set.
- Obtain predictions from each base learner on the validation set.
- Use the predictions from step 3 as features to train a meta-model.
- Obtain predictions from the base learners and the meta-model on the test dataset.
Here's an implementation of the Stacking algorithm:
- Choose the number of base learners, the type of base learners, and the meta-model (e.g., logistic regression, decision tree, etc.).
- Split the dataset into a training set and a validation set.
- Train each base learner on the training set.
- Obtain predictions from each base learner on the validation set.
- Use the predictions from step 4 as features to train the meta-model.
- Obtain predictions from each base learner on the test dataset.
- Use the predictions from step 6 as features to obtain the final prediction from the meta-model.
Advantages
- Stacking can exploit the strengths of different base learners, often achieving higher predictive accuracy than any individual model.
- It can be applied to various base learner types and meta-models, making it a versatile ensemble learning technique.
- Stacking can help mitigate the weaknesses of individual base learners, leading to more robust and reliable predictions.
Limitations
- Stacking can be computationally expensive, particularly when using multiple base learners and complex meta-models.
- The choice of base learners, meta-model, and the number of base learners can significantly impact the performance of the ensemble.
- It can be prone to overfitting, especially when using complex meta-models or insufficient validation data for training the meta-model.
Comparing Techniques: Bagging vs. Boosting vs. Stacking
Performance Metrics
When comparing ensemble learning techniques, it's essential to consider various performance metrics to assess their effectiveness. Common metrics include:
-
Accuracy
The proportion of correct predictions over the total number of predictions. -
Precision, Recall, and F1-score
These metrics provide a more comprehensive view of classification performance, particularly in imbalanced datasets. -
Mean Squared Error (MSE) or Root Mean Squared Error (RMSE)
These metrics measure the difference between predicted and actual values in regression tasks. -
Area Under the ROC Curve (AUC-ROC)
A metric that measures the trade-off between true positive rate and false positive rate.
Suitability for Different Tasks
Each ensemble learning technique has its unique characteristics, making them suitable for different tasks:
-
Bagging
Bagging is most effective for reducing overfitting and improving the stability of unstable learners, like decision trees. It is well-suited for tasks where base learners tend to have high variance. -
Boosting
Boosting is designed to improve the accuracy of weak learners by reducing bias. It is suitable for tasks where base learners exhibit high bias or low accuracy. -
Stacking
Stacking is suitable for tasks where leveraging the strengths of multiple base learners can lead to better predictions. It is a versatile technique that can be applied to various base learner types and meta-models.
Computational Complexity
The computational complexity of ensemble learning techniques varies depending on the number of base learners, the type of base learners, and the meta-model (in the case of Stacking):
-
Bagging
Bagging can be easily parallelized, as each base learner is trained independently. However, it can be computationally expensive when using a large number of base learners or complex base learners. -
Boosting
Boosting can be computationally expensive, as it trains base learners sequentially. The complexity increases with the number of weak learners and the complexity of the base learners. -
Stacking
Stacking can be computationally expensive, particularly when using multiple base learners and complex meta-models. Additionally, it requires splitting the dataset into training and validation sets, which may further increase the computational cost.
References


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS