


Introduction
When several statistical models are created, this article describes the AIC, which is one indicator as to which statistical model can be considered a good model.
Data and Models
In this article, I will use the seed count data and the statistical model for 100 fictitious plants, which were treated in the article Generalized linear model.
The data are as follows: y is the number of seeds per individual, x is the size of the individual, and f is whether the individual has been treated with fertilizer or not (categorical variable).
| y | x | f | |
|---|---|---|---|
| 0 | 6 | 8.31 | C |
| 1 | 6 | 9.44 | C |
| 2 | 6 | 9.50 | C |
| 3 | 12 | 9.07 | C |
| 4 | 10 | 10.16 | C |
| 99 | 9 | 9.97 | T |
From this data, the following Poisson regression models have been constructed:
- Statistical model where the number of seeds depends on the size (x model)
\lambda_i = e^{\beta_1 + \beta_2 x_i}
- Statistical model in which the number of seeds depends on the presence or absence of fertilizer treatments (f model)
\lambda_i = e^{\beta_1 + \beta_3 d_i} d_i
- Statistical model where seed number depends on size and fertilizer treatment (xf model)
\lambda_i = e^{\beta_1 + \beta_2 x_i + \beta_3 d_i} d_i
Deviance
We have searched for parameters that maximize the log-likelihood, which is the goodness of fit to the observed data, when the parameters of the statistical model are estimated by maximum likelihood.
Here, there is a measure called deviance that indicates the poor fit. The deviance
The
A summary of the parameter estimation results for the x model is shown below.
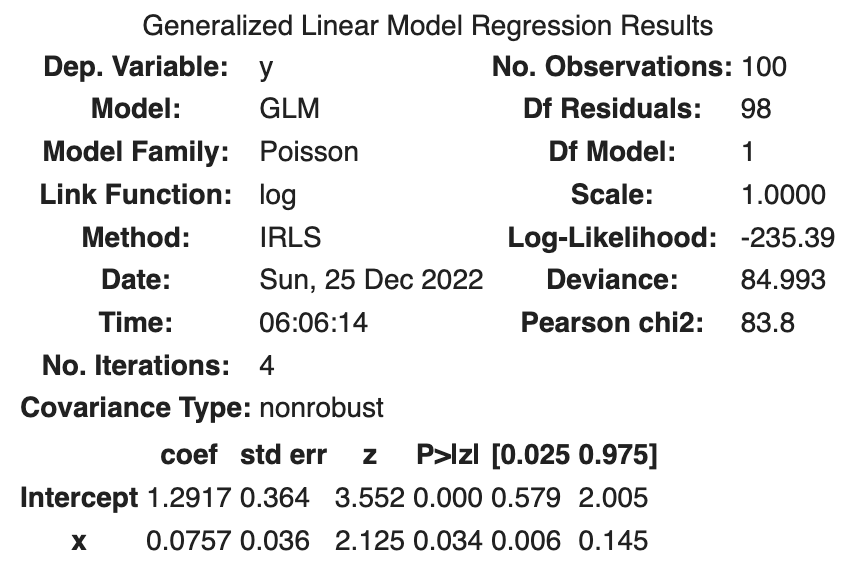
The maximum log likelihood is -235.39, so the deviance Deviance is shown.
The Deviance shown is the residual deviance, which is defined as follows.
The
The residual deviance is the relative value of the poor fit with respect to the deviance of the full model.
Next, we consider the maximum residual deviance. The model with the maximum deviation is the model with the worst fit, i.e., the model with no explanatory variables incorporated. This model is called the Null model.
The Null model can be constructed as follows.
import statsmodels.api as sm
import statsmodels.formula.api as smf
fit_null = smf.glm('y ~ 1', data=df, family=sm.families.Poisson()).fit()
fit_null.summary()

The maximum residual deviance
The following table summarizes the deviations.
| Name | Definition |
|---|---|
| Deviance( |
|
| Minimum deviance( |
D$ when the full model is applied. |
| Residual deviance | |
| Maximum deviance( |
|
| Null deviance |
The following is a summary of each model.
| Model | Number of parameters | Deviance | Residual deviance | |
|---|---|---|---|---|
| Null | 1 | -237.6 | 475.3 | 89.5 |
| f | 2 | -237.6 | 475.3 | 89.5 |
| x | 2 | -235.4 | 470.8 | 85.0 |
| xf | 3 | -235.3 | 470.6 | 84.8 |
| Full | 100 | -192.9 | 385.8 | 0.0 |
It can be seen that the model with a larger number of parameters fits the data better.
AIC
We have seen that increasing the complexity of the model, i.e., increasing the number of parameters in the model, improves the maximum log-likelihood and improves the fit to the observed data. However, it may only be a good fit for the observed data obtained by chance, and may not be a good fit at all for other data. In other words, it may be good for one set of observations, but poor for another set of observations. In machine learning terms, this means that you may be over-training on the training data.
AIC is a measure that emphasizes good prediction rather than goodness of fit.
The AIC is expressed by the following equation:
The AIC is easily output by the following code.
print('null model', fit_null.aic)
print('f model', fit_f.aic)
print('x model', fit_x.aic)
null model 477.2864426185736
f model 479.25451392137364
x model 477.2864426185736
Using AIC as the criterion, the x model is the best model.
| Model | Number of parameters | Deviance | Residual deviance | AIC | |
|---|---|---|---|---|---|
| Null | 1 | -237.6 | 475.3 | 89.5 | 477.3 |
| f | 2 | -237.6 | 475.3 | 89.5 | 479.3 |
| x | 2 | -235.4 | 470.8 | 85.0 | 474.8 |
| xf | 3 | -235.3 | 470.6 | 84.8 | 476.6 |
| Full | 100 | -192.9 | 385.8 | 0.0 | 585.8 |
Notes on model selection by AIC
If there are few observed data, a model with fewer parameters may have a smaller AIC than the true model. A simple model may have better predictive power because the observed data is too small to find a rule of thumb in the data.
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS