


Pendahuluan
XGBoost adalah sebuah perpustakaan perangkat lunak sumber terbuka yang menyediakan implementasi algoritma gradient boosting yang efisien dan mudah digunakan. Dirancang untuk berskala besar dan memiliki performa tinggi, XGBoost dengan cepat mendapatkan popularitas di kalangan ilmuwan data dan praktisi machine learning karena kemampuannya untuk memberikan hasil terbaik pada berbagai jenis masalah machine learning.
Artikel ini akan memandu Anda melalui proses instalasi dan pengaturan XGBoost, memperkenalkan alur kerjanya yang dasar dan API-nya, serta menjelajahi tentang Feature Importance dalam model XGBoost.
Instalasi dan Pengaturan
Sebelum menginstal XGBoost, pastikan bahwa perangkat lunak berikut sudah terinstal pada sistem Anda:
- Python 3.6 atau versi yang lebih baru
- NumPy
- SciPy
- scikit-learn
Untuk menginstal XGBoost, cukup jalankan perintah berikut di terminal atau command prompt Anda:
$ pip install xgboost
Alur Kerja Dasar XGBoost
Pada bab ini, saya akan membahas alur kerja dasar XGBoost, yang meliputi memuat kumpulan data publik, memproses data, membuat pembagian data train dan test, mendefinisikan dan melatih model, serta mengevaluasi kinerjanya.
Memuat Kumpulan Data Publik
Untuk implementasi XGBoost kita, kita akan menggunakan kumpulan data Iris yang terkenal, yang tersedia di scikit-learn. Kumpulan data ini berisi 150 sampel bunga iris, masing-masing dengan empat fitur (panjang sepal, lebar sepal, panjang kelopak, dan lebar kelopak) dan label kelas yang sesuai (setosa, versicolor, atau virginica).
Pertama, mari impor pustaka yang diperlukan dan muat kumpulan data:
import numpy as np
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
Memproses Data
Sebelum melanjutkan dengan model XGBoost, penting untuk memproses data. Dalam hal ini, kita hanya akan melakukan label encoding pada variabel target (label kelas) untuk mengubahnya menjadi nilai integer.
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
y_encoded = encoder.fit_transform(y)
Membuat Pembagian Data Train dan Test
Untuk mengevaluasi kinerja model XGBoost kita, kita perlu membagi kumpulan data menjadi data pelatihan dan pengujian. Kita akan menggunakan 80% dari data untuk pelatihan dan 20% sisanya untuk pengujian.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
Mendefinisikan dan Melatih Model
Sekarang bahwa data kita siap, kita dapat mendefinisikan model XGBoost kita. Karena ini adalah masalah klasifikasi, kita akan menggunakan kelas XGBClassifier.
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
Evaluasi dan Prediksi Model
Setelah model XGBoost kita dilatih, kita dapat mengevaluasi kinerjanya pada kumpulan data pengujian dan membuat prediksi. Kita akan menggunakan akurasi sebagai metrik evaluasi.
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model accuracy: {accuracy:.2f}")
Model accuracy: 1.00
Menjelajahi API XGBoost
Pada bab ini, saya akan menjelajahi lebih dalam tentang API XGBoost dan mengeksplorasi beberapa fitur kuatnya, seperti kelas XGBClassifier dan XGBRegressor, struktur data DMatrix, cross-validation, early stopping, dan metrik evaluasi kustom.
Kelas XGBClassifier dan XGBRegressor
XGBoost menyediakan dua kelas utama untuk mengimplementasikan model gradient boosting: XGBClassifier untuk masalah klasifikasi dan XGBRegressor untuk masalah regresi. Kedua kelas ini menawarkan beberapa hiperparameter untuk menyesuaikan kinerja model, seperti:
n_estimators: Jumlah putaran boosting (default: 100).learning_rate: Ukuran langkah shrinkage yang digunakan dalam pembaruan untuk mencegah overfitting (default: 0.3).max_depth: Kedalaman maksimum pohon (default: 6).subsample: Fraksi sampel yang akan digunakan untuk pelatihan base learner individual (default: 1).colsample_bytree: Fraksi fitur yang akan dipilih untuk setiap putaran boosting (default: 1).
Struktur Data DMatrix
XGBoost menggunakan struktur data kustom yang disebut DMatrix untuk menyimpan kumpulan data secara internal. Format DMatrix dioptimalkan untuk efisiensi memori dan kecepatan pelatihan. Untuk membuat DMatrix, Anda dapat menggunakan kode berikut:
import xgboost as xgb
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
Saat menggunakan format DMatrix, Anda dapat menggunakan API asli XGBoost untuk pelatihan dan prediksi:
params = {'objective': 'multi:softmax', 'num_class': 3}
model = xgb.train(params, dtrain, num_boost_round=100)
y_pred = model.predict(dtest)
Cross-validation dengan XGBoost
XGBoost menyediakan fungsi bawaan untuk melakukan cross-validation k-fold, yang dapat membantu Anda menyesuaikan hiperparameter model dan menilai kinerjanya. Untuk melakukan cross-validation, gunakan fungsi cv:
cv_results = xgb.cv(params, dtrain, num_boost_round=100, nfold=5, metrics='merror', early_stopping_rounds=10)
Di sini, nfold menentukan jumlah lipatan untuk cross-validation, metrics adalah metrik evaluasi yang digunakan, dan early_stopping_rounds akan menghentikan pelatihan jika kinerja tidak membaik selama jumlah putaran yang ditentukan.
Early Stopping dan Metrik Evaluasi Kustom
Early stopping adalah teknik yang berguna untuk mencegah overfitting dengan menghentikan proses pelatihan jika kinerja model pada set validasi tidak membaik selama jumlah putaran yang ditentukan. Anda dapat menggunakan early stopping dalam XGBoost dengan menyediakan set validasi dan menentukan parameter early_stopping_rounds selama pelatihan:
model = xgb.train(params, dtrain, num_boost_round=100, evals=[(dtest, 'validation')], early_stopping_rounds=10)
XGBoost juga memungkinkan Anda untuk mendefinisikan metrik evaluasi kustom. Untuk mengimplementasikan metrik kustom, Anda perlu membuat fungsi Python yang mengambil dua argumen: nilai prediksi dan objek DMatrix yang berisi label asli. Fungsi harus mengembalikan tuple yang berisi nama metrik dan nilai metrik. Misalnya, Anda dapat membuat metrik akurasi kustom seperti berikut:
def accuracy_metric(preds, dmatrix):
labels = dmatrix.get_label()
return 'accuracy', accuracy_score(labels, preds)
model = xgb.train(params, dtrain, num_boost_round=100, evals=[(dtest, 'validation')], feval=accuracy_metric, early_stopping_rounds=10)
Potongan kode ini menunjukkan bagaimana menggunakan metrik kustom accuracy_metric selama pelatihan dengan melewatinya sebagai parameter feval. Model sekarang akan dievaluasi menggunakan metrik akurasi kustom, dan early stopping akan diterapkan berdasarkan kinerjanya.
Feature Importance dalam XGBoost
Feature Importance adalah teknik yang digunakan untuk mengidentifikasi dan menempatkan peringkat fitur yang paling penting dalam kumpulan data berdasarkan kontribusinya terhadap prediksi model. Memahami Feature Importance dapat membantu Anda memperoleh wawasan tentang hubungan antara fitur dan variabel target, serta meningkatkan interpretabilitas model. Pada bab ini, saya akan menjelajahi berbagai jenis Feature Importance dalam XGBoost dan belajar cara memplot dan menginterpretasi hasilnya.
Jenis Feature Importance
XGBoost menyediakan beberapa jenis pentingnya yang dapat digunakan untuk menempatkan peringkat fitur berdasarkan kriteria yang berbeda. Jenis pentingnya yang paling umum adalah:
weight: Jumlah kali fitur muncul dalam pohon di semua putaran boosting.gain: Kenaikan rata-rata (perbaikan pada kriteria pemisahan) dari fitur ketika digunakan dalam pohon.cover: Cakupan rata-rata dari fitur ketika digunakan dalam pohon.
Memplot Feature Importance
Misalnya, untuk memplot Feature Importance berdasarkan gain untuk kumpulan data Iris, Anda dapat menggunakan kode berikut:
import seaborn as sns
import xgboost as xgb
# Set Seaborn's plotting style and color palette
sns.set_style("whitegrid")
sns.set_palette("husl")
# Obtain feature importance values
importance_df = pd.DataFrame(model.get_booster().get_score(importance_type='gain').items(),
columns=['Feature', 'Importance'])
# Sort dataframe by importance values
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# Plot the feature importance using Seaborn's barplot
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Gain-based Feature Importance for Iris Dataset', fontsize=18)
plt.xlabel('Importance (F score)', fontsize=14)
plt.ylabel('Feature', fontsize=14)
plt.show()
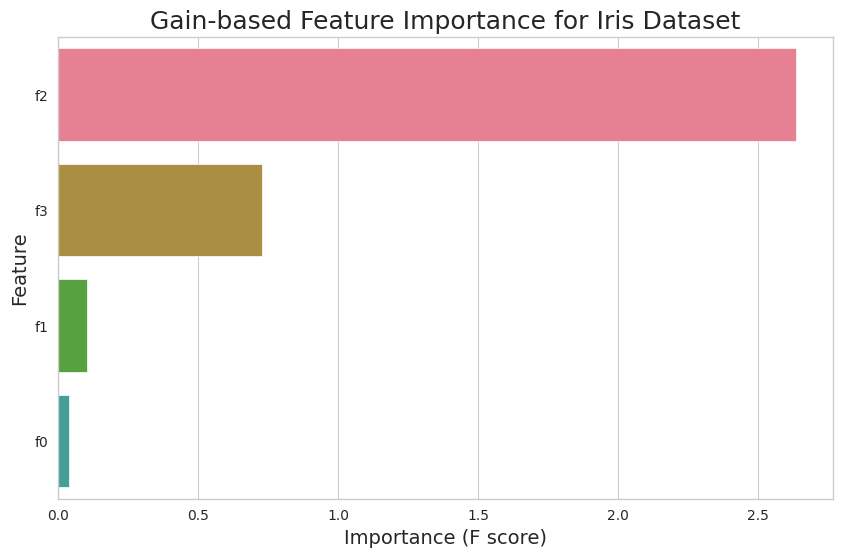
Potongan kode ini akan menghasilkan diagram batang yang menunjukkan Feature Importance berdasarkan gain untuk setiap fitur dalam kumpulan data Iris. Anda dapat mengganti 'gain' dengan 'weight' atau 'cover' untuk memplot jenis pentingnya yang sesuai.
Menginterpretasi Hasil
Plot Feature Importance memberikan wawasan yang berharga tentang hubungan antara fitur dan variabel target. Fitur dengan nilai penting yang lebih tinggi memiliki pengaruh yang lebih besar pada prediksi model, sedangkan fitur dengan nilai penting yang lebih rendah memberikan kontribusi yang lebih kecil.
References
















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS