



Pengantar
Dalam beberapa tahun terakhir, bidang pembelajaran mesin dan pemrosesan bahasa alami telah mengalami kemajuan pesat. Di antara hal-hal tersebut, Large Language Model (LLM) telah menarik perhatian besar dari para peneliti dan pengembang.
Dengan menyimpan informasi terbaru yang diperoleh dari dokumen internal atau web scraping dalam sebuah database dan mengintegrasikannya dengan LLM, diharapkan sistem dapat memberikan respons yang mencakup informasi terkini.
Dalam artikel ini, saya akan menjelaskan cara membangun sistem LLM menggunakan data properti, dengan memanfaatkan Vector DB.
Arsitektur Sistem
Pengambilan Dokumen
Arsitektur dari banyak sistem pengambilan dokumen dalam sistem LLM menggunakan data properti secara umum adalah sebagai berikut.
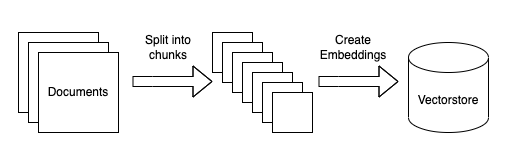
Mengambil Serangkaian Dokumen
Fase awal dalam menyematkan data unik ke dalam sistem LLM melibatkan perolehan dokumen yang diperlukan. Berbagai metode seperti akses API dan web scraping dapat digunakan untuk mencapai hal ini.
Memecah Dokumen menjadi Bagian yang Lebih Kecil
Untuk memastikan sistem LLM dapat memproses data dengan efektif, bermanfaat untuk membagi dokumen yang lebih besar menjadi segmen yang lebih mudah dikelola, seperti paragraf atau kalimat. Proses pemecahan ini memfasilitasi ekstraksi data penting dengan efisien pada tahap selanjutnya.
Membuat Representasi Vektor untuk Setiap Dokumen
Setiap segmen dikonversi menjadi representasi vektor berdimensi tinggi. Vektor-vektor ini disimpan dalam database vektor untuk digunakan dalam pemrosesan kueri di tahap selanjutnya.
Kueri
Kueri pada sistem LLM mengikuti desain arsitektur sebagai berikut.
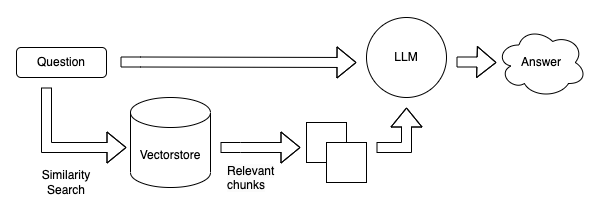
Menghasilkan Vektor untuk Kueri
Ketika pengguna mengirimkan kueri, sistem dengan cepat membuat representasi vektor dari kueri tersebut. Langkah ini memungkinkan perhitungan skor kesamaan antara kueri dan segmen dokumen yang disimpan secara efisien.
Mencari Dokumen yang Paling Mirip di Database Vektor
Dengan memanfaatkan database vektor, sistem mencari vektor dokumen yang paling mirip dengan vektor kueri. Prosedur pencarian ini memungkinkan sistem untuk dengan cepat menemukan dokumen-dokumen yang relevan dengan kueri pengguna.
Memasok Dokumen dan Kueri Asli ke LLM untuk Menghasilkan Respons
Terakhir, dokumen yang dipilih dari database vektor, bersama dengan kueri asli, dimasukkan ke dalam sistem LLM. Sistem ini kemudian menghasilkan respons yang sesuai berdasarkan input yang diberikan dan menyampaikannya kepada pengguna.
Referensi















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS