





Apa itu ChatGPT Retrieval Plugin
ChatGPT Retrieval Plugin adalah plugin yang memungkinkan pencarian semantik dan pemulihan dokumen pribadi atau organisasi. Pencarian semantik mengacu pada konsep memahami niat dan tujuan pengguna pencarian serta memberikan hasil yang paling relevan yang diinginkan oleh pengguna. Pengguna dapat memulihkan potongan dokumen yang paling relevan yang disimpan dalam Vector DB, yang dapat mencakup file, catatan, surel, dan sumber data lainnya, dengan mengajukan pertanyaan atau menyatakan kebutuhan mereka dalam bahasa alami. Dengan menggunakan plugin ini, mungkin untuk mengembalikan tanggapan yang merujuk pada dokumen internal melalui ChatGPT.
Bagaimana ChatGPT Retrieval Plugin Bekerja
ChatGPT Retrieval Plugin bekerja sebagai berikut:
- Menggunakan model embedding
text-embedding-ada-002dari OpenAI untuk menghasilkan embedding untuk potongan-potongan dokumen. - Menyimpan embedding dalam Vector DB.
- Melakukan kueri terhadap Vector DB.
Vector DB yang Didukung
ChatGPT Retrieval Plugin mendukung berbagai penyedia Vector DB, masing-masing dengan fitur dan karakteristik kinerja yang berbeda. Tergantung pada penyedia yang Anda pilih, Anda mungkin perlu menggunakan Dockerfiles yang berbeda dan mengatur variabel lingkungan yang berbeda.
Berikut ini adalah Vector DB yang didukung oleh ChatGPT Retrieval Plugin:
- Pinecone
- Weaviate
- Zilliz
- Milvus
- Qdrant
- Redis
- LlamaIndex
- Chroma
- Azure Cognitive Search
- Supabase
- Postgres
- AnalyticDB
Juga memungkinkan untuk menggunakan Vector DB yang tidak didukung secara default dengan mengedit kode sumber.
Persiapan
Untuk mengatur dan menjalankan ChatGPT Retrieval Plugin, ikuti langkah-langkah berikut:
-
Pasang Python 3.10 jika belum terpasang.
-
Klona repositori.
$ git clone https://github.com/openai/chatgpt-retrieval-plugin.git
- Buka direktori repositori yang telah diklon.
$ cd /path/to/chatgpt-retrieval-plugin
- Pasang Poetry.
$ pip install poetry
- Buat lingkungan virtual baru menggunakan Python 3.10.
$ poetry env use python3.10
- Aktifkan lingkungan virtual.
$ poetry shell
- Pasang dependensi.
$ poetry install
- Buat Bearer token.
- Atur variabel lingkungan yang diperlukan.
DATASTORE, BEARER_TOKEN, dan OPENAI_API_KEY adalah variabel lingkungan yang wajib. Atur variabel lingkungan untuk penyedia Vector DB yang dipilih dan variabel lain yang diperlukan.
| Nama | Diperlukan | Deskripsi |
|---|---|---|
DATASTORE |
Ya | Menentukan penyedia Vector DB. Anda dapat memilih chroma, pinecone, weaviate, zilliz, milvus, qdrant, redis, azuresearch, supabase, postgres, atau analyticdb untuk menyimpan dan mengkueri embedding. |
BEARER_TOKEN |
Ya | Token rahasia yang diperlukan untuk mengotentikasi permintaan ke API. Anda dapat menghasilkannya menggunakan alat atau metode pilihan Anda, seperti jwt.io. |
OPENAI_API_KEY |
Ya | Kunci API OpenAI yang diperlukan untuk menghasilkan embedding menggunakan model text-embedding-ada-002. Anda dapat memperoleh kunci API dengan membuat akun di OpenAI. |
$ export DATASTORE=<your_datastore>
$ export BEARER_TOKEN=<your_bearer_token>
$ export OPENAI_API_KEY=<your_openai_api_key>
# Optional environment variables used when running Azure OpenAI
$ export OPENAI_API_BASE=https://<AzureOpenAIName>.openai.azure.com/
$ export OPENAI_API_TYPE=azure
$ export OPENAI_EMBEDDINGMODEL_DEPLOYMENTID=<Name of text-embedding-ada-002 model deployment>
$ export OPENAI_METADATA_EXTRACTIONMODEL_DEPLOYMENTID=<Name of deployment of model for metatdata>
$ export OPENAI_COMPLETIONMODEL_DEPLOYMENTID=<Name of general model deployment used for completion>
$ export OPENAI_EMBEDDING_BATCH_SIZE=<Batch size of embedding, for AzureOAI, this value need to be set as 1>
# Add the environment variables for your chosen vector DB.
# Some of these are optional; read the provider's setup docs in /docs/providers for more information.
# Pinecone
$ export PINECONE_API_KEY=<your_pinecone_api_key>
$ export PINECONE_ENVIRONMENT=<your_pinecone_environment>
$ export PINECONE_INDEX=<your_pinecone_index>
# Weaviate
$ export WEAVIATE_URL=<your_weaviate_instance_url>
$ export WEAVIATE_API_KEY=<your_api_key_for_WCS>
$ export WEAVIATE_CLASS=<your_optional_weaviate_class>
# Zilliz
$ export ZILLIZ_COLLECTION=<your_zilliz_collection>
$ export ZILLIZ_URI=<your_zilliz_uri>
$ export ZILLIZ_USER=<your_zilliz_username>
$ export ZILLIZ_PASSWORD=<your_zilliz_password>
# Milvus
$ export MILVUS_COLLECTION=<your_milvus_collection>
$ export MILVUS_HOST=<your_milvus_host>
$ export MILVUS_PORT=<your_milvus_port>
$ export MILVUS_USER=<your_milvus_username>
$ export MILVUS_PASSWORD=<your_milvus_password>
# Qdrant
$ export QDRANT_URL=<your_qdrant_url>
$ export QDRANT_PORT=<your_qdrant_port>
$ export QDRANT_GRPC_PORT=<your_qdrant_grpc_port>
$ export QDRANT_API_KEY=<your_qdrant_api_key>
$ export QDRANT_COLLECTION=<your_qdrant_collection>
# AnalyticDB
$ export PG_HOST=<your_analyticdb_host>
$ export PG_PORT=<your_analyticdb_port>
$ export PG_USER=<your_analyticdb_username>
$ export PG_PASSWORD=<your_analyticdb_password>
$ export PG_DATABASE=<your_analyticdb_database>
$ export PG_COLLECTION=<your_analyticdb_collection>
# Redis
$ export REDIS_HOST=<your_redis_host>
$ export REDIS_PORT=<your_redis_port>
$ export REDIS_PASSWORD=<your_redis_password>
$ export REDIS_INDEX_NAME=<your_redis_index_name>
$ export REDIS_DOC_PREFIX=<your_redis_doc_prefix>
$ export REDIS_DISTANCE_METRIC=<your_redis_distance_metric>
$ export REDIS_INDEX_TYPE=<your_redis_index_type>
# Llama
$ export LLAMA_INDEX_TYPE=<gpt_vector_index_type>
$ export LLAMA_INDEX_JSON_PATH=<path_to_saved_index_json_file>
$ export LLAMA_QUERY_KWARGS_JSON_PATH=<path_to_saved_query_kwargs_json_file>
$ export LLAMA_RESPONSE_MODE=<response_mode_for_query>
# Chroma
$ export CHROMA_COLLECTION=<your_chroma_collection>
$ export CHROMA_IN_MEMORY=<true_or_false>
$ export CHROMA_PERSISTENCE_DIR=<your_chroma_persistence_directory>
$ export CHROMA_HOST=<your_chroma_host>
$ export CHROMA_PORT=<your_chroma_port>
# Azure Cognitive Search
$ export AZURESEARCH_SERVICE=<your_search_service_name>
$ export AZURESEARCH_INDEX=<your_search_index_name>
$ export AZURESEARCH_API_KEY=<your_api_key> (optional, uses key-free managed identity if not set)
# Supabase
$ export SUPABASE_URL=<supabase_project_url>
$ export SUPABASE_ANON_KEY=<supabase_project_api_anon_key>
# Postgres
$ export PG_HOST=<postgres_host>
$ export PG_PORT=<postgres_port>
$ export PG_USER=<postgres_user>
$ export PG_PASSWORD=<postgres_password>
$ export PG_DATABASE=<postgres_database>
- Jalankan API secara lokal.
$ poetry run start
- Akses dokumentasi API di
http://0.0.0.0:8000/docsuntuk menguji endpoint API (jangan lupa menambahkan Bearer token).
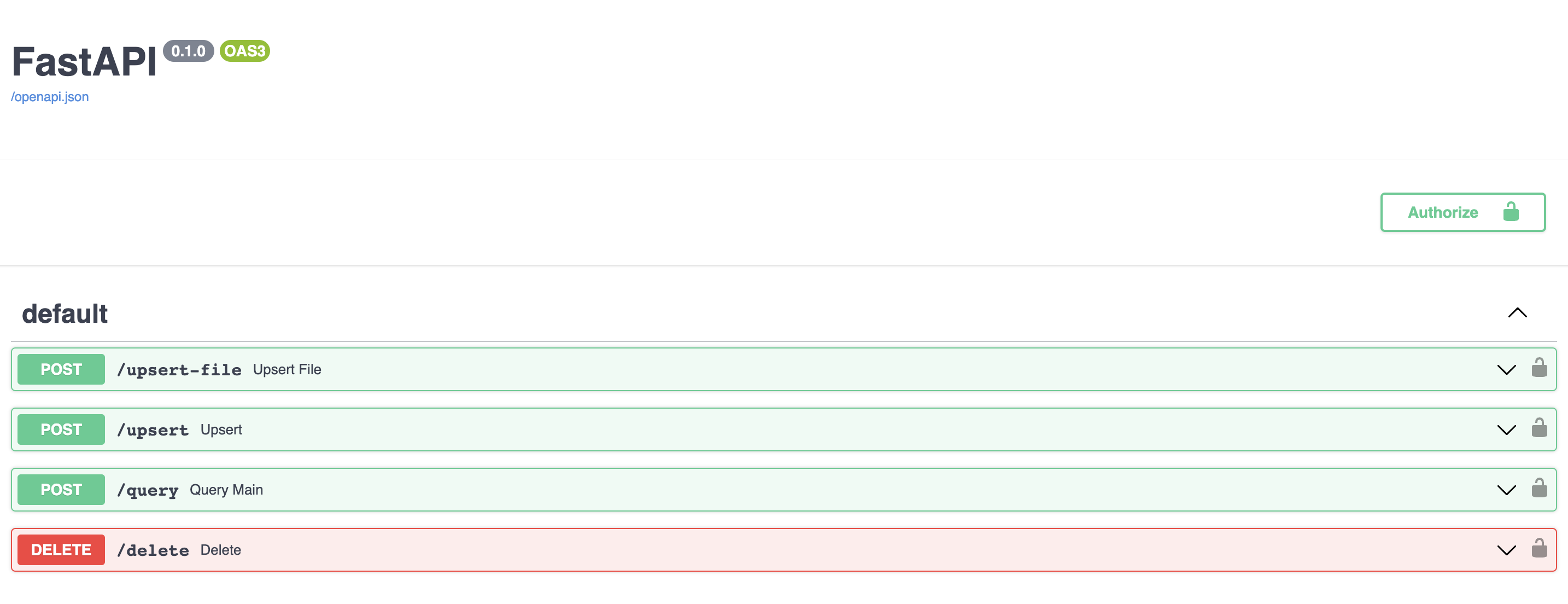
Endpoint API
ChatGPT Retrieval Plugin dibangun menggunakan FastAPI, kerangka kerja web untuk membangun API dengan Python. FastAPI memungkinkan pengembangan, validasi, dan dokumentasi endpoint API dengan mudah.
Plugin ini menyediakan endpoint berikut untuk memasukkan, mengkueri, dan menghapus dokumen dari database vektor. Semua permintaan dan respons dalam format JSON, dan memerlukan bearer token yang valid sebagai header otorisasi.
-
/upsert
Endpoint ini memungkinkan mengunggah satu atau lebih dokumen dan menyimpan teks dan metadata mereka dalam database vektor. Dokumen dibagi menjadi potongan sekitar 200 token, masing-masing dengan ID unik. Endpoint ini mengharapkan daftar dokumen dalam body permintaan, masing-masing dengan bidangtext, dan bidang opsionaliddanmetadata. Bidang metadata dapat berisi sub-bidang opsional berikut:source,source_id,url,created_at, danauthor. Endpoint ini mengembalikan daftar ID dokumen yang dimasukkan (ID akan dihasilkan jika tidak disediakan awalnya). -
/upsert-file
Endpoint ini memungkinkan mengunggah satu file (PDF, TXT, DOCX, PPTX, atau MD) dan menyimpan teks dan metadata-nya dalam database vektor. File akan dikonversi menjadi teks biasa dan dibagi menjadi potongan sekitar 200 token, masing-masing dengan ID unik. Endpoint ini mengembalikan daftar yang berisi ID yang dihasilkan dari file yang dimasukkan. -
/query
Endpoint ini memungkinkan mengkueri database vektor menggunakan satu atau lebih kueri bahasa alami dan filter metadata opsional. Endpoint ini mengharapkan daftar kueri dalam body permintaan, masing-masing dengan bidangquerydan bidang opsionalfilterdantop_k. Bidangfilterharus berisi subset dari sub-bidang berikut:source,source_id,document_id,url,created_at, danauthor. Bidangtop_kmenentukan berapa banyak hasil yang akan dikembalikan untuk setiap kueri, dan nilai defaultnya adalah 3. Endpoint ini mengembalikan daftar objek yang masing-masing berisi daftar potongan dokumen yang paling relevan untuk kueri yang diberikan, bersama dengan teks, metadata, dan skor kesamaannya. -
/delete
Endpoint ini memungkinkan menghapus satu atau lebih dokumen dari database vektor menggunakan ID mereka, filter metadata, atau tandadelete_all. Endpoint ini memerlukan setidaknya satu dari parameter berikut dalam body permintaan:ids,filter, ataudelete_all. Parameteridsharus berupa daftar ID dokumen yang akan dihapus; semua potongan dokumen untuk dokumen dengan ID ini akan dihapus. Parameterfilterharus berisi subset dari sub-bidang berikut:source,source_id,document_id,url,created_at, danauthor. Parameterdelete_allharus berupa boolean yang menunjukkan apakah semua dokumen akan dihapus dari database vektor. Endpoint ini mengembalikan boolean yang menunjukkan apakah penghapusan berhasil.
Referensi













































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS