
What is MLOps
MLOps adalah istilah yang diciptakan dengan menggabungkan machine learning (ML) dan DevOps, dan merupakan praktik untuk mengelola siklus hidup machine learning, termasuk prapemrosesan data, pengembangan model, penyebaran, dan operasi.
Dalam sistem ML, kode ML menyumbang persentase kecil.
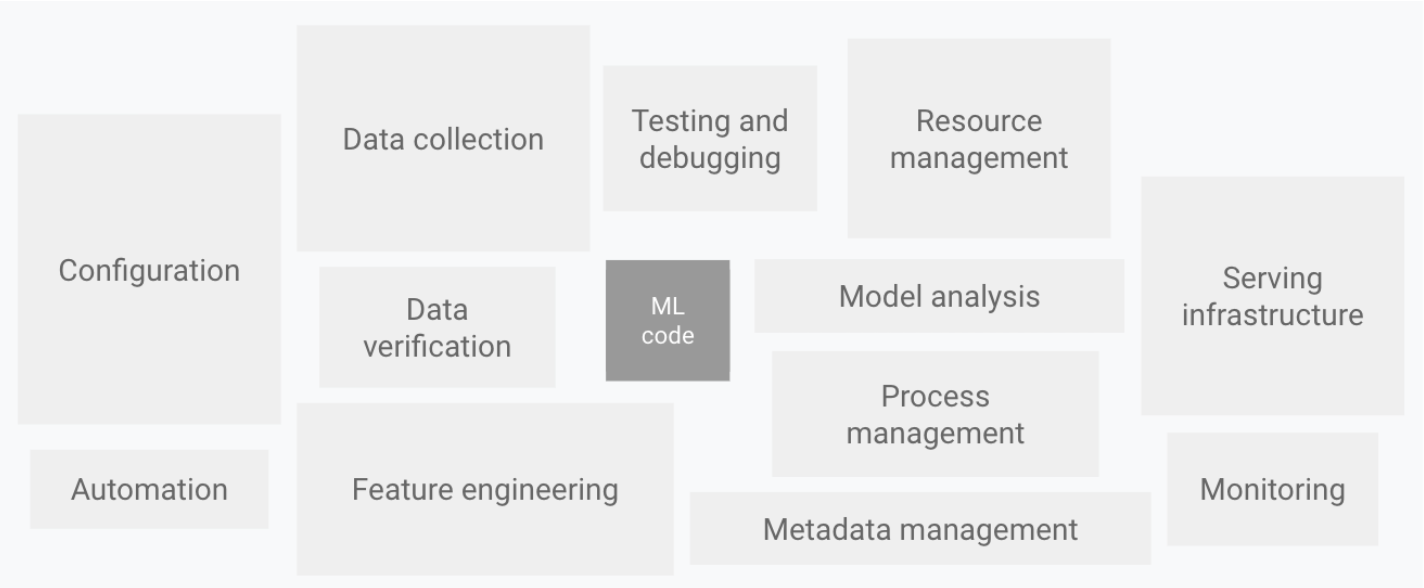
MLOps: Machine Learning Operations
Untuk mewujudkan nilai pembelajaran mesin, sistem ML kompleks yang berisi kode ML harus dioperasikan dalam lingkungan produksi. Istilah MLOps diciptakan untuk mengatasi sistem kompleks ini untuk pengembangan dan operasi yang berkelanjutan.
Tantangan sistem ML
Membangun sistem ML memiliki tantangan unik berikut ini:
-
Lebih banyak jam kerja diperlukan untuk pengembangan selain pembelajaran mesin
Sistem pembelajaran mesin membutuhkan jam kerja untuk pengembangan dan pengoperasian selain pembelajaran mesin, seperti integrasi ke dalam aplikasi dan pembangunan jaringan pipa data. -
Membutuhkan waktu untuk mencapai tingkat praktis
Pembelajaran mesin adalah teknologi yang kompleks dengan banyak aspek ambigu, dan bahkan jika dapat didemonstrasikan dalam lingkungan pengembangan, ada banyak kasus di mana masalah muncul di lingkungan produksi dan sistem berakhir di PoC. -
Reproduksibilitas eksperimen tidak dapat dijamin
Kode yang bekerja dengan baik selama fase pengembangan model mungkin gagal ketika diimplementasikan di lingkungan produksi. Selain itu, bahkan ketika model yang sama dilatih pada data yang sama, hasil yang berbeda dapat dihasilkan. -
Kualitas model sulit dipertahankan
Bahkan jika model berkualitas tinggi ketika dirilis, kualitasnya akan memburuk seiring waktu karena beberapa perubahan yang tidak terduga. Model harus terus diperbarui melalui perbaikan berkelanjutan, bukan hanya dirilis. -
Mudah terjadi konflik antar tim
Sistem pembelajaran mesin melibatkan berbagai ahli, termasuk insinyur data, ilmuwan data, insinyur pembelajaran mesin, dan insinyur sistem. Karena tim terdiri dari individu yang beragam, mudah timbul konflik di dalam tim ketika masalah muncul.
Prinsip-prinsip MLOps
Perubahan pipeline machine learning dari tiga perspektif: data, model machine learning, dan kode.
- Otomatisasi
- Continuous X
- Kontrol versi
- Pelacakan eksperimen
- Pengujian
- Pemantauan
- Reproduksibilitas
Otomatisasi
Tingkat otomatisasi data, model, dan pipeline menentukan kematangan proses ML. Seiring dengan meningkatnya kematangan, begitu pula kecepatan pelatihan model baru, sehingga penting untuk mengotomatiskan penyebaran model ML ke dalam sistem tanpa intervensi manual.
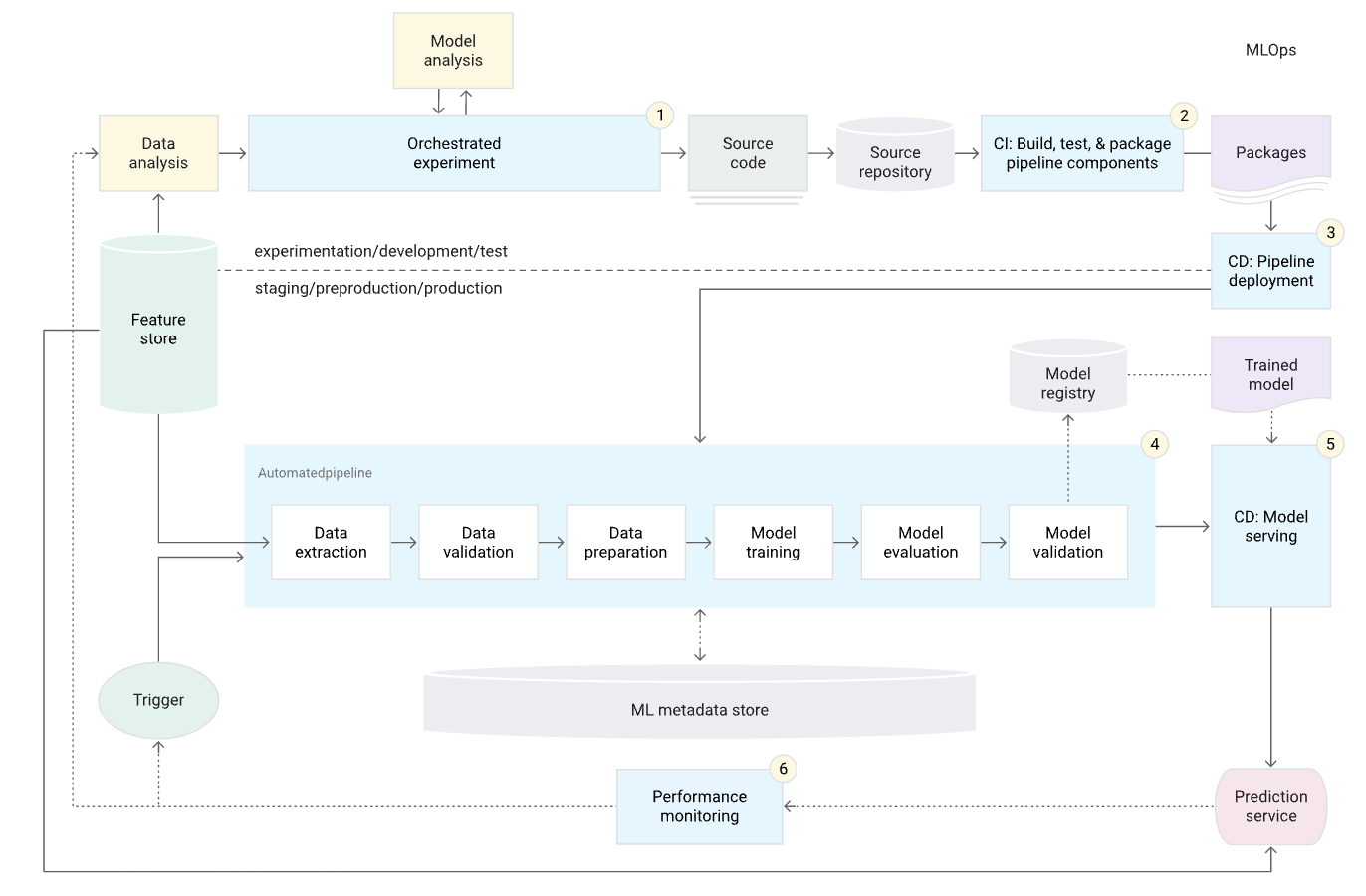
MLOps: Machine Learning Operations
Continuous X
MLOps mencakup praktik-praktik berikut:
-
Continuous Integration (CI)
Pengujian kode, data, dan model -
Continuous Delivery (CD)
Pengiriman pipa pelatihan ML untuk secara otomatis menyebarkan model ML lainnya -
Continuous Training (CT)
Melatih ulang dan menyebarkan ulang model ML secara otomatis. -
Continuous Management (CM)
Memantau data dan kinerja model di lingkungan produksi.
Kontrol versi
Perlakukan skrip, model, dan set data ML sebagai bagian intrinsik dari proses DevOps Karena model dan data ML dapat berubah, maka penting untuk melacaknya dengan sistem kontrol versi Alasan umum mengapa model dan data ML dapat berubah meliputi
- Model dilatih ulang berdasarkan data pelatihan baru
- Model dilatih ulang berdasarkan metode pelatihan baru
- Model menurun seiring waktu
- Model digunakan dalam aplikasi baru
- Model diserang dan perlu direvisi
- Data menghilang karena alasan tertentu
- Kepemilikan data menjadi masalah
- Distribusi statistik perubahan data
Pelacakan eksperimen
Machine learning development is an iterative and research-centric process. In contrast to the traditional software development process, ML development involves running multiple experiments on model learning in parallel before deciding which models should be promoted to production. The content of those experiments must be tracked.
Pengujian
Pipeline pengembangan ML terdiri dari tiga komponen berikut ini
- Jalur pipa data
- Jalur pipa model ML
- Jalur pipa aplikasi
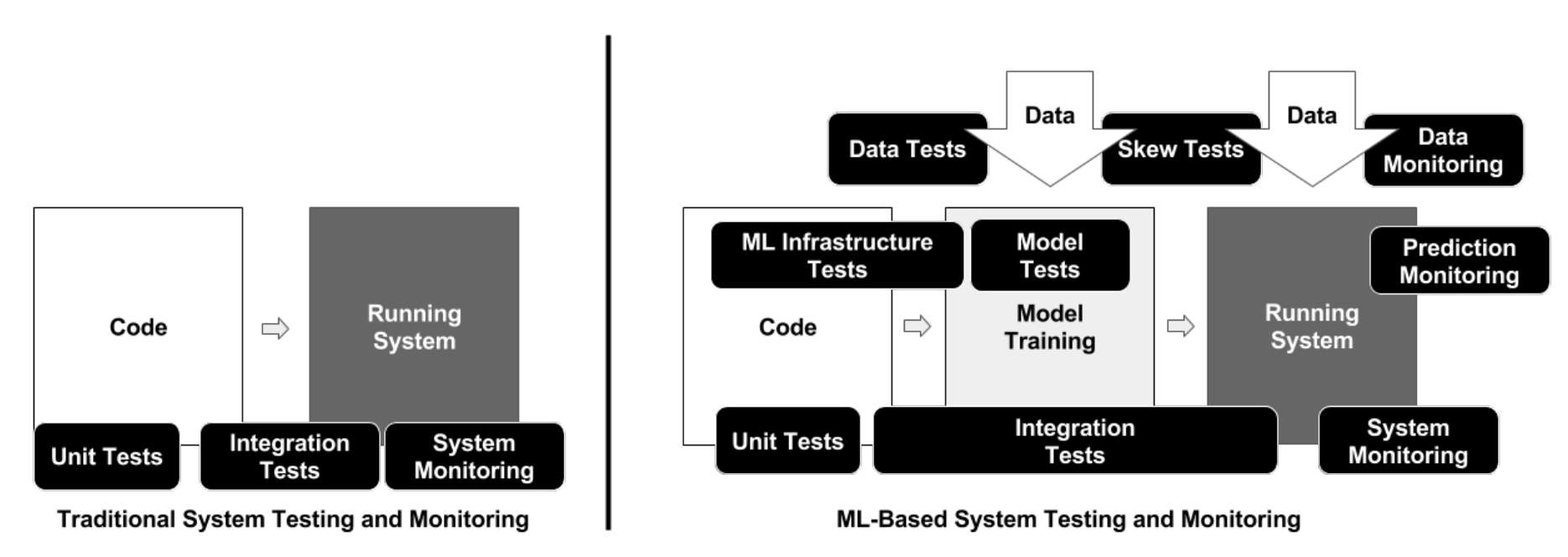
The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
Mengikuti pemisahan ini, pengujian dalam sistem ML dibedakan ke dalam tiga cakupan berikut:
- Pengujian fitur dan data
- Pengujian pengembangan model
- Pengujian infrastruktur ML
Pengujian fitur dan data
-
Pengujian data dan skema fitur secara otomatis
- Untuk membangun skema, hitung statistik dari data pelatihan
-
Melakukan uji kepentingan fitur untuk memahami apakah fitur baru meningkatkan daya prediksi
- Hitung koefisien korelasi untuk kolom fitur
- Latih model dengan satu atau dua fitur
- Ukur ketergantungan data, latensi inferensi, dan penggunaan RAM dari fitur-fitur baru
- Hapus fitur yang tidak digunakan atau tidak digunakan lagi dari infrastruktur dan dokumentasikan
-
Verifikasi bahwa fitur dan jalur pipa data sesuai dengan kebijakan seperti GDPR
-
Unit menguji kode pembuatan fitur
Pengujian pengembangan model
-
Periksa korelasi antara metrik kerugian (misalnya, MSE) dan metrik dampak bisnis (misalnya, pendapatan, keterlibatan pengguna) dari algoritma ML
- Lakukan uji A/B kecil dengan model yang sengaja didegradasi
-
** Melakukan pengujian keusangan pada model**
- Lakukan pengujian A/B dengan model yang sudah usang
-
Validasi kinerja model
- Gunakan set pengujian tambahan yang dipisahkan dari set pelatihan dan validasi
-
** Lakukan pengujian kewajaran dan bias terhadap kinerja model ML**
- Kumpulkan lebih banyak data, termasuk kategori yang berpotensi diremehkan
Pengujian infrastruktur ML
-
Memastikan reprodusibilitas pembelajaran model ML
- Mengidentifikasi bagian non-deterministik dari basis kode pembelajaran model dan berusaha untuk meminimalkan non-determinisme
-
Uji tekanan pada ML API
- Lakukan uji unit untuk menghasilkan data input secara acak dan melatih model
- Lakukan uji kerusakan untuk pelatihan model (uji apakah model ML dapat dipulihkan dari pos pemeriksaan setelah kerusakan di tengah pelatihan)
-
Periksa kebenaran algoritma
- Lakukan pengujian unit untuk memastikan bahwa model ML tidak dilatih sampai selesai, melainkan diiterasi beberapa kali dan kerugian berkurang selama pelatihan
-
Lakukan pengujian integrasi dari seluruh pipeline ML
- Buat pengujian yang sepenuhnya otomatis yang secara berkala memicu seluruh pipeline ML
-
Validasi model ML sebelum disajikan
- Tetapkan ambang batas dan uji untuk degradasi kualitas model yang lambat di banyak versi set validasi
- Tetapkan ambang batas dan uji untuk penurunan kinerja tiba-tiba dalam versi baru model ML
Pemantauan
Pemantauan berikut ini diperlukan untuk memastikan bahwa model ML yang digunakan berfungsi seperti yang diharapkan.
-
Memantau perubahan ketergantungan di seluruh pipeline dan memberi tahu Anda tentang hasilnya
- Perubahan versi data
- Perubahan sistem sumber
- Peningkatan ketergantungan
-
Memantau invarian data dari input pelatihan dan penyajian
- Memberi peringatan ketika data pada penyajian tidak cocok dengan skema yang ditentukan pada pelatihan
-
Memantau apakah fitur-fitur pada pelatihan dan penyajian menghitung nilai yang sama
- Mencatat sampel lalu lintas penayangan
- Hitung statistik deskriptif (minimum, maksimum, rata-rata, nilai, persentase nilai yang hilang, dll.) dari fitur pelatihan dan sampel penyajian dan verifikasi bahwa mereka cocok
-
Memantau seberapa ketinggalan zaman sistem di lingkungan produksi
- Mengidentifikasi elemen-elemen untuk pemantauan dan membuat strategi untuk memantau model sebelum menerapkan ke produksi
-
Memantau kinerja komputasi sistem ML
- Ambang batas peringatan yang telah ditetapkan sebelumnya dan mengukur kinerja kode, data, versi model, dan komponen
- Kumpulkan metrik penggunaan sistem seperti alokasi memori GPU, lalu lintas jaringan, dan penggunaan disk å
-
Memantau proses pembuatan fitur
- Sering menjalankan ulang pembuatan fitur
-
Memantau degradasi dramatis dan bertahap dari kinerja prediktif model ML
- Mengukur bias statistik dari prediksi (rata-rata prediksi atas irisan data)
- Mengukur kualitas prediksi secara real time jika label hadir segera setelah prediksi
Reproduksibilitas
Reproduksibilitas dalam pipeline ML berarti bahwa input yang sama akan menghasilkan hasil yang sama di setiap fase pengembangan model ML. Reproduksibilitas adalah prinsip penting dari MLOps. Berikut ini adalah gambaran umum tentang apa yang harus dilakukan untuk memastikan reproduksibilitas dalam fase-fase berikut
- Fase pengumpulan data
- Fase rekayasa fitur
- Fase pelatihan dan pembuatan model
- Fase penyebaran model
Fase pengumpulan data
Untuk memastikan reproduksibilitas pembuatan data pelatihan, hal-hal berikut harus dilakukan.
- Selalu cadangkan data Anda
- Simpan snapshot dari dataset
- Rancang sumber data dengan cap waktu
- Lakukan pembuatan versi data
Fase rekayasa fitur
Untuk membuat rekayasa fitur dapat direproduksi, lakukan hal berikut.
- Tempatkan kode pembuatan fitur di bawah kontrol versi
Fase pelatihan dan pembuatan model
Untuk memastikan reprodusibilitas pelatihan dan pembangunan model, kita melakukan hal berikut ini
- Memastikan bahwa urutan fitur selalu sama
- Mendokumentasikan dan mengotomatiskan transformasi fitur seperti normalisasi
- Mendokumentasikan dan mengotomatisasi pemilihan hyperparameter
Fase penyebaran model
Untuk memastikan reproduksibilitas penyebaran model, berikut ini akan dilakukan.
- Mencocokkan versi perangkat lunak dan ketergantungan dengan lingkungan produksi
- Gunakan Docker dan dokumentasikan spesifikasinya, termasuk versi gambar
Alat untuk mengaktifkan MLOps
Alat-alat berikut berguna untuk mewujudkan MLOps.
- Kontrol Versi: GitHub, GitLab
- Kontainer: Docker
- Orkestrasi kontainer: Kubernetes, Mesos
- CI: Circle CI, Jenkins, GitHub Actions, Gitlab CI
- Infrastruktur sebagai Kode (IaC): Terraform, Ansible, Pupet
- Pemantauan: Sentry, Datadog, Prometheus, Deequ
- Model penyajian: FastAPI, KFServing, BentoML, Vertex AI, Sagemaker
- Platform pembelajaran mesin: Sagemaker, Vertex AI
- store fitur: Feast, Hopworks, Rasgo, Vertex AI, SageMaker, Databricks, Tecton, Zipline
- Manajemen percobaan: Weights & Biases, MLFlow, Trains, Comet, Neptune, TensorBoard
- Manajemen jalur pipa: Airflow, Argo, Digdag, Metaflow, Kubeflow, Kedro, TFX, Prefect
- Pengoptimalan hyperparameter: Scikit-Optimize, Optuna, Hydra
Referensi


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS