

Apa itu EDA
EDA adalah singkatan dari Explanatory Data Analysis, yang merupakan proses memahami karakteristik, struktur, dan pola data dengan memvisualisasikan data dan menghitung statistik. Melakukan EDA dengan baik, memahami data dengan benar, dan merumuskan hipotesis sangat penting untuk membangun model pembelajaran mesin yang sangat akurat. Sering dikatakan bahwa sebagian besar waktu yang dihabiskan untuk mengembangkan model pembelajaran mesin dihabiskan untuk EDA, prapemrosesan data, dan rekayasa fitur.
EDA melibatkan analisis hal-hal berikut
- Berapa banyak data?
- Apa statistiknya (rata-rata, varians, dll.)?
- Bagaimana distribusinya?
- Apakah ada nilai yang hilang?
- Apakah ada pencilan?
- Apakah data berkorelasi?
- Variabel kategorikal atau numerik?
- Variabel kategorikal
- Berapa kardinalitasnya (jumlah label unik)?
- Apakah label-label diurutkan atau diurutkan?
- Apakah label yang langka disertakan?
- Variabel numerik
- Apakah ada rangkaian waktu data, seperti tanggal, tahun, waktu, dll.?
- Apakah nilainya diskrit atau kontinu?
- Variabel kategorikal
Dalam artikel ini, saya akan melakukan EDA sederhana menggunakan dataset Kaggle.
Dataset
Dalam artikel ini, saya akan menggunakan dataset kompetisi Kaggle House Prices Kompetisi ini adalah untuk memprediksi harga (SalePrice) dari setiap rumah di Ames, Iowa.
Unduh file berikut:
train.csv
Impor pustaka yang diperlukan.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
Muat dataset dan periksa data.
df = pd.read_csv('train.csv')
pd.set_option('display.max_rows', None)
display(df.head())

Buang kolom Id karena tidak diperlukan.
df.drop('Id', axis=1, inplace=True)
df.shape
(1460, 80)
Dataset ini terdiri dari 1.460 sampel dan 80 kolom. 80 kolom juga berisi variabel objektif SalePrice dan 79 variabel penjelas.
Distribusi variabel tujuan
Pertama, kita periksa distribusi variabel objektif.
df['SalePrice'].hist(bins=50, density=True)
plt.ylabel('Number of houses')
plt.xlabel('SalePrice')
plt.show()
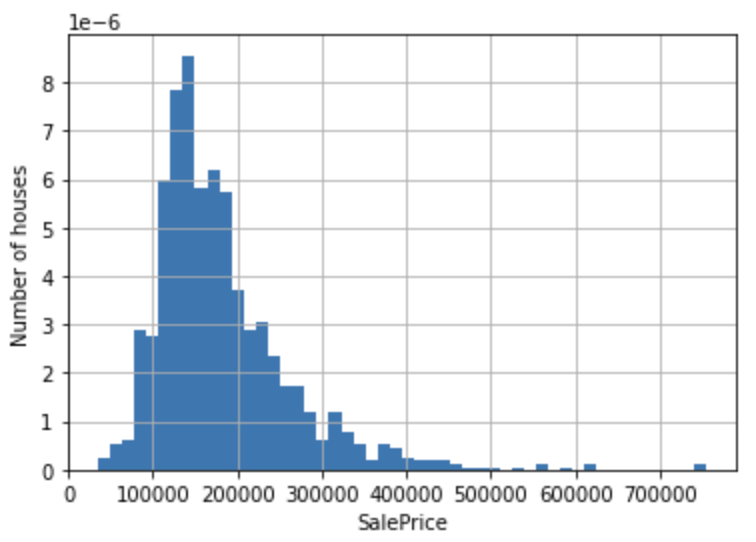
Kita melihat bahwa distribusi variabel objektif SalePrice condong ke kanan. Kita memperbaiki distorsi ini dengan mengambil log.
np.log(df['SalePrice']).hist(bins=50, density=True)
plt.ylabel('Number of houses')
plt.xlabel('Log of SalePrice')
plt.show()
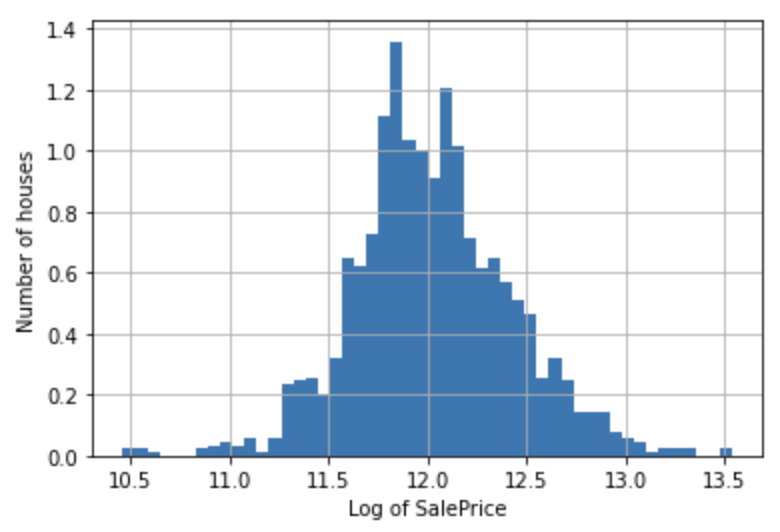
Distribusi lebih menyerupai distribusi normal.
Jenis data dari variabel penjelas
Mari kita identifikasi variabel kategorikal dan numerik.
Pertama, identifikasi variabel kategorikal.
cat_vars = [var for var in df.columns if df[var].dtype == 'O']
# MSSubClass is also categorical by definition, despite its numeric values
# so add MSSubClass to the list of categorical variables
cat_vars = cat_vars + ['MSSubClass']
print('number of categorical variables:', len(cat_vars))
number of categorical variables: 44
Cast kolom-kolom yang terdapat dalam cat_vars menjadi data kategorikal.
df[cat_vars] = df[cat_vars].astype('O')
Berikutnya, identifikasi variabel numerik.
num_vars = [
var for var in df.columns if var not in cat_vars and var != 'SalePrice'
]
print('number of categorical variables:', len(num_vars))
number of numerical variables: 35
Nilai yang hilang
Periksa variabel mana dalam dataset yang mengandung nilai yang hilang.
vars_with_na = [var for var in df.columns if data[var].isnull().sum() > 0]
df[vars_with_na].isnull().mean().sort_values(
ascending=False).plot.bar(figsize=(10, 4))
plt.ylabel('% of missing data')
plt.axhline(y=0.80, color='r', linestyle='-')
plt.show()
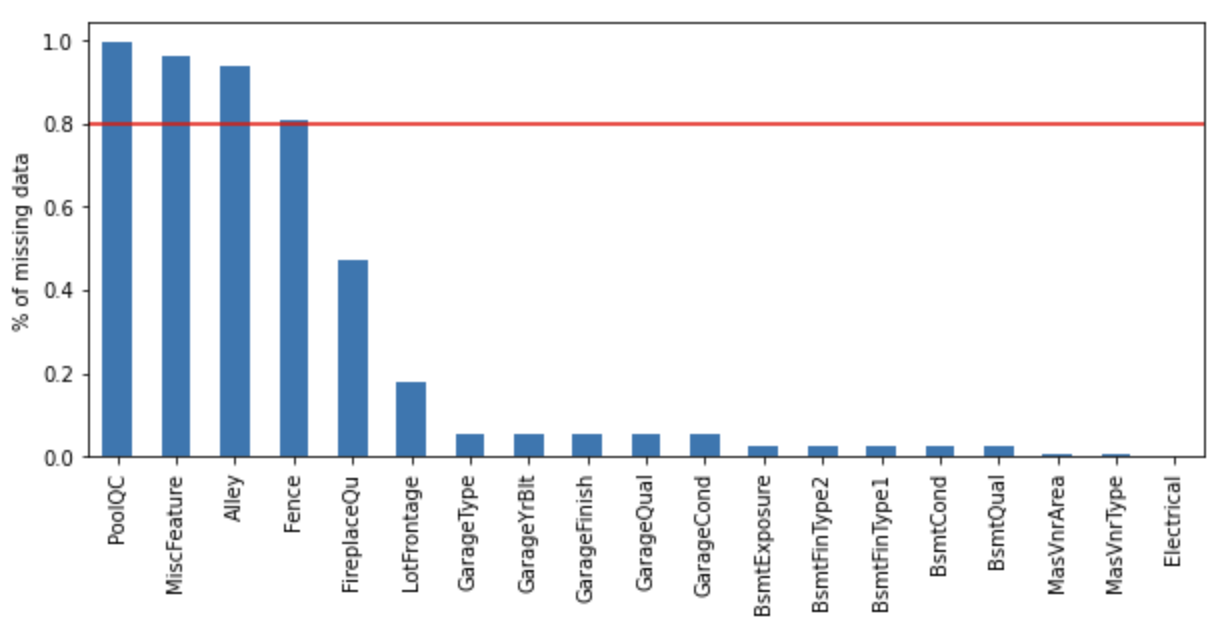
Kolom-kolom berikut ini menunjukkan persentase yang hilang melebihi 80%.
- PoolQC
- MiscFeature
- Alley
- Fence
Variabel numerik
Nilai deret waktu
Dataset dapat berisi data deret waktu seperti tahun, bulan, hari, dan waktu. Dalam hal ini, data yang terkait dengan tahun disertakan.
year_vars = [var for var in num_vars if 'Yr' in var or 'Year' in var]
print(year_vars)
['YearBuilt', 'YearRemodAdd', 'GarageYrBlt', 'YrSold']
Visualize the relationship between SalePrice and YrSold.
df.groupby('YrSold')['SalePrice'].median().plot()
plt.ylabel('Median House Price')
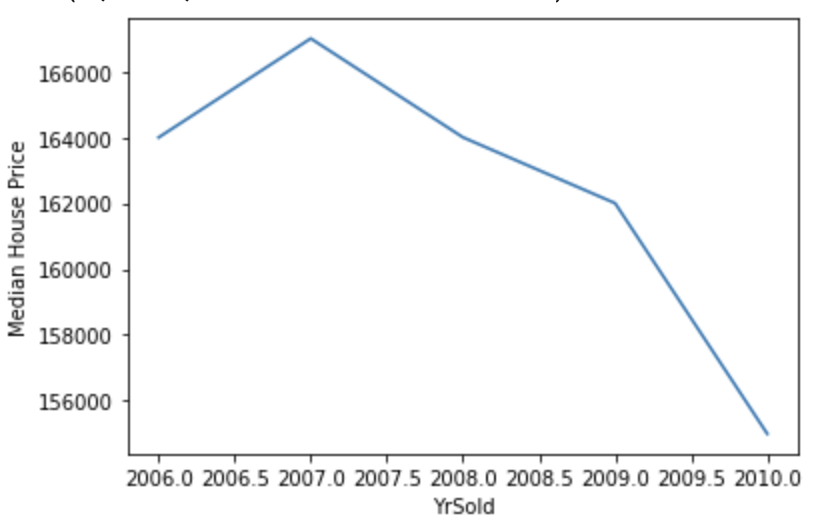
Harga jual rumah telah menurun dari tahun ke tahun.
Nilai diskrit
Periksa nilai diskrit, yang memiliki jumlah kemungkinan nilai yang terbatas.
discrete_vars = [var for var in num_vars if len(
df[var].unique()) < 20 and var not in year_vars]
for var in discrete_vars:
sns.catplot(x=var, y='SalePrice', data=df, kind="box", height=4, aspect=1.5)
sns.stripplot(x=var, y='SalePrice', data=df, jitter=0.1, alpha=0.3, color='k')
plt.show()
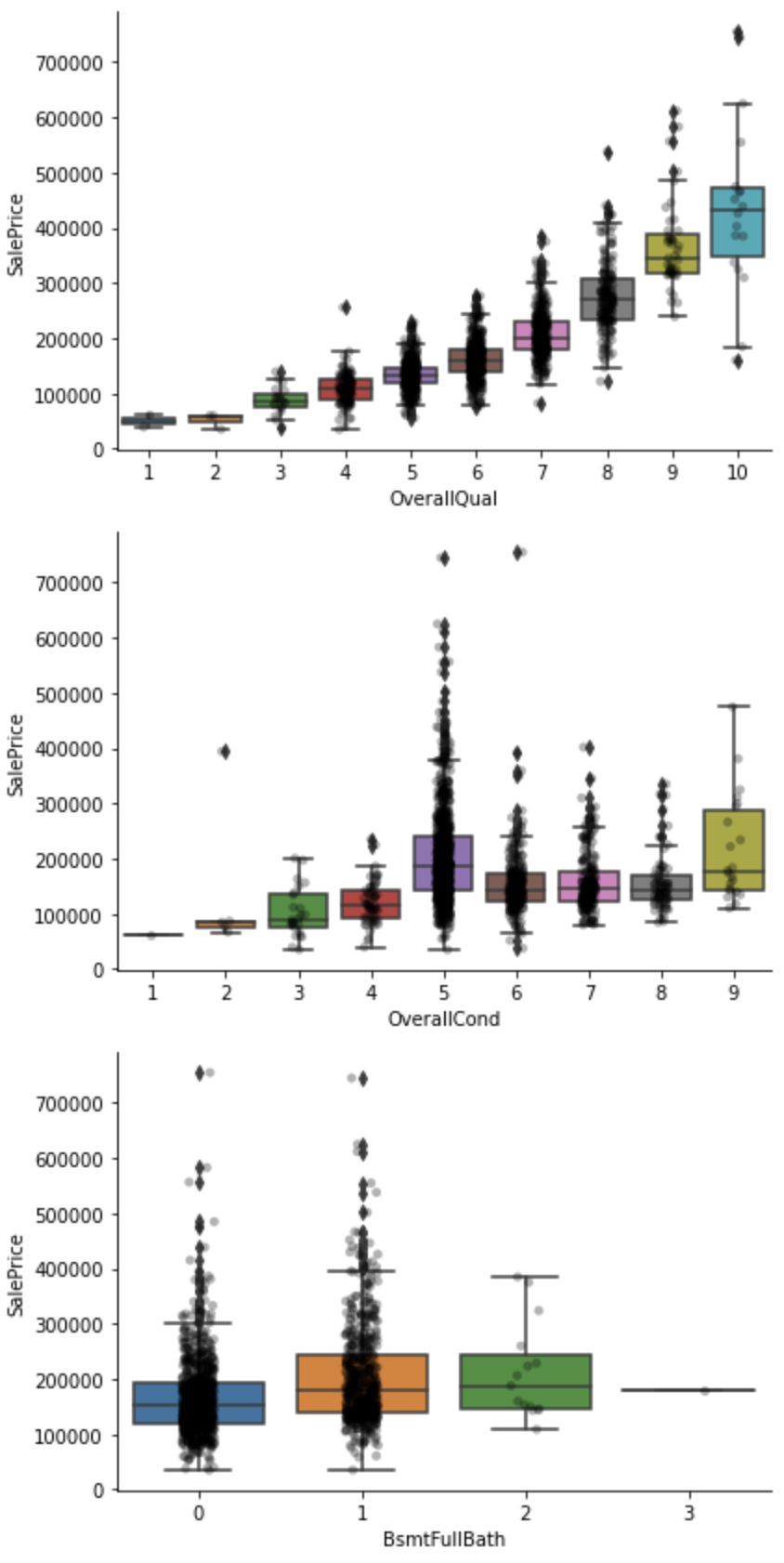
Harga jual untuk OverallQual, OverallCond, dan BsmtFullBath pada capture di atas tampaknya cenderung meningkat seiring dengan meningkatnya nilai.
Nilai Kontinu
Periksa distribusi nilai kontinu.
cont_vars = [
var for var in num_vars if var not in discrete_vars + year_vars]
df[cont_vars].hist(bins=30, figsize=(15,15))
plt.show()
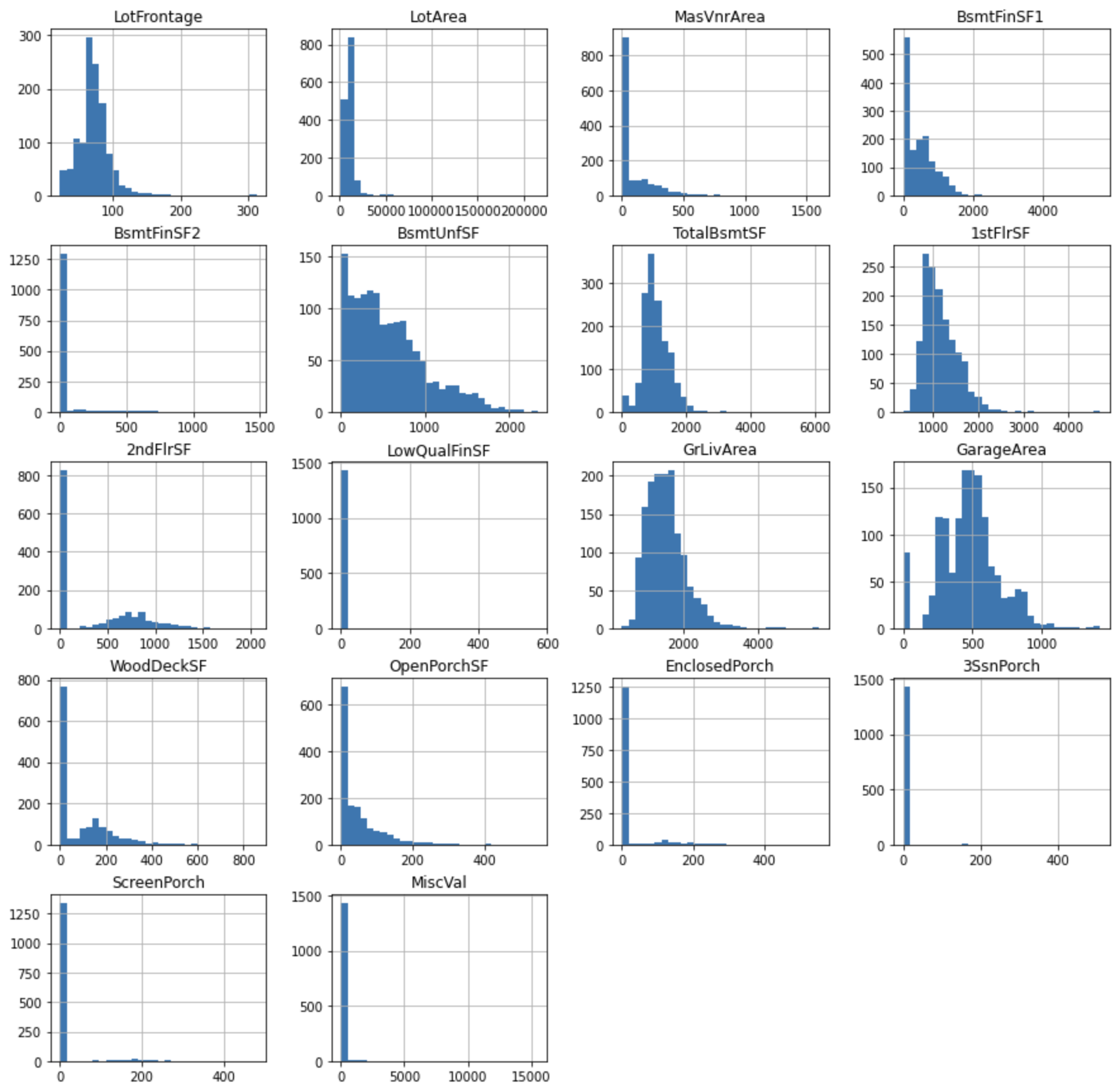
Anda dapat melihat bahwa variabel-variabel tidak terdistribusi secara normal. Mentransformasi variabel untuk memperbaiki distorsi distribusi dapat meningkatkan kinerja model.
Dalam hal ini, terapkan transformasi Yeo-Johnson untuk variabel seperti LotFrontage, LotArea, dan terapkan transformasi biner untuk variabel dengan skewness ekstrim seperti 3SsnPorch, ScreenPorch.
Simpan variabel yang sangat miring di skewed.
skewed = [
'BsmtFinSF2', 'LowQualFinSF', 'EnclosedPorch',
'3SsnPorch', 'ScreenPorch', 'MiscVal'
]
cont_vars = [
'LotFrontage',
'LotArea',
'MasVnrArea',
'BsmtFinSF1',
'BsmtUnfSF',
'TotalBsmtSF',
'1stFlrSF',
'2ndFlrSF',
'GrLivArea',
'GarageArea',
'WoodDeckSF',
'OpenPorchSF',
]
Transformasi Yeo-Johnson
Menerapkan transformasi Yeo-Johnson.
tmp = df.copy()
for var in cont_vars:
tmp[var], param = stats.yeojohnson(df[var])
tmp[cont_vars].hist(bins=30, figsize=(15,15))
plt.show()
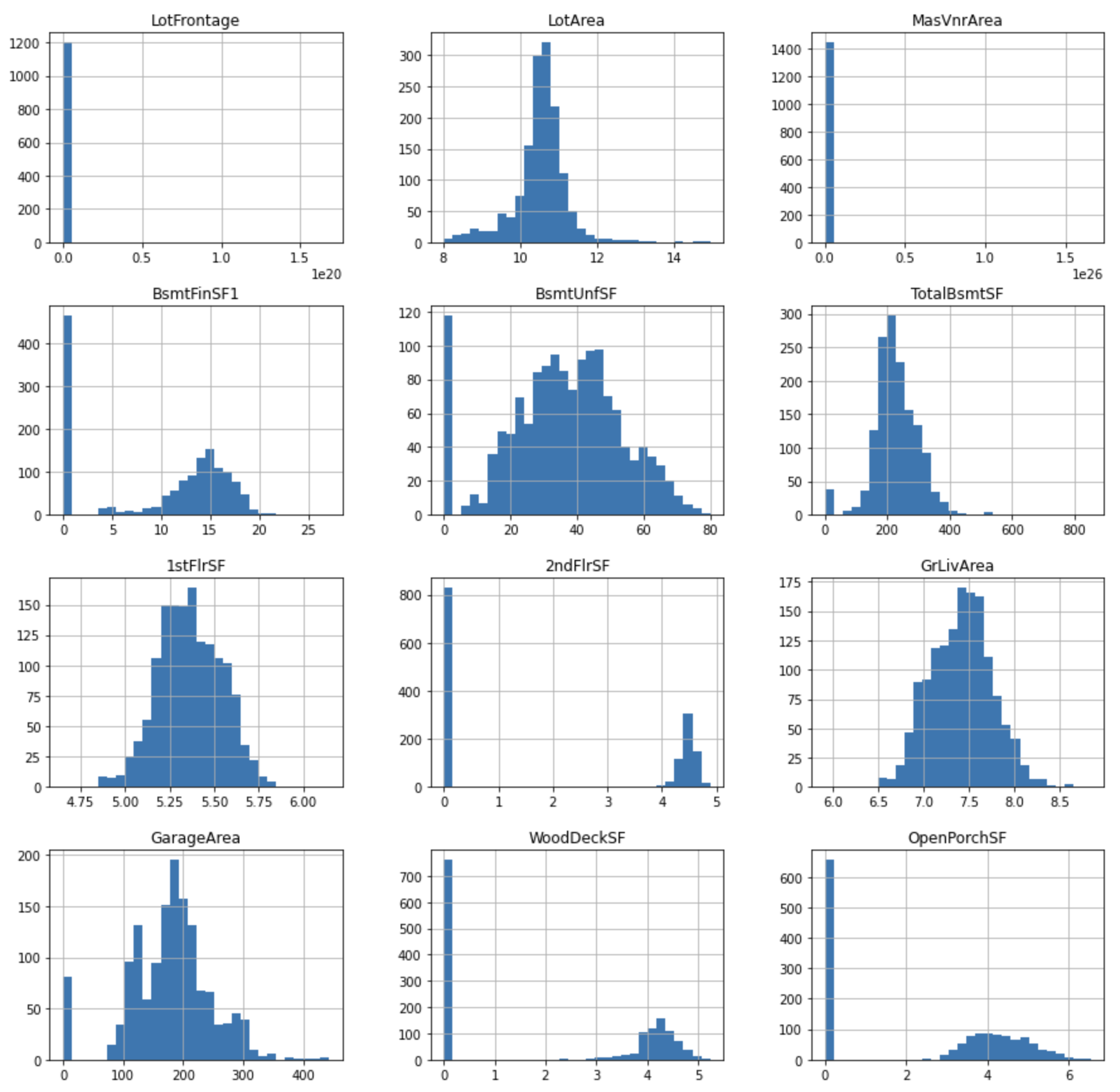
Visualisasikan hubungan dengan SalePrice.
for var in cont_vars:
plt.figure(figsize=(12,4))
plt.subplot(1, 2, 1)
plt.scatter(df[var], np.log(df['SalePrice']))
plt.ylabel('SalePrice')
plt.xlabel('Original ' + var)
plt.subplot(1, 2, 2)
plt.scatter(tmp[var], np.log(tmp['SalePrice']))
plt.ylabel('SalePrice')
plt.xlabel('Transformed ' + var)
plt.show()
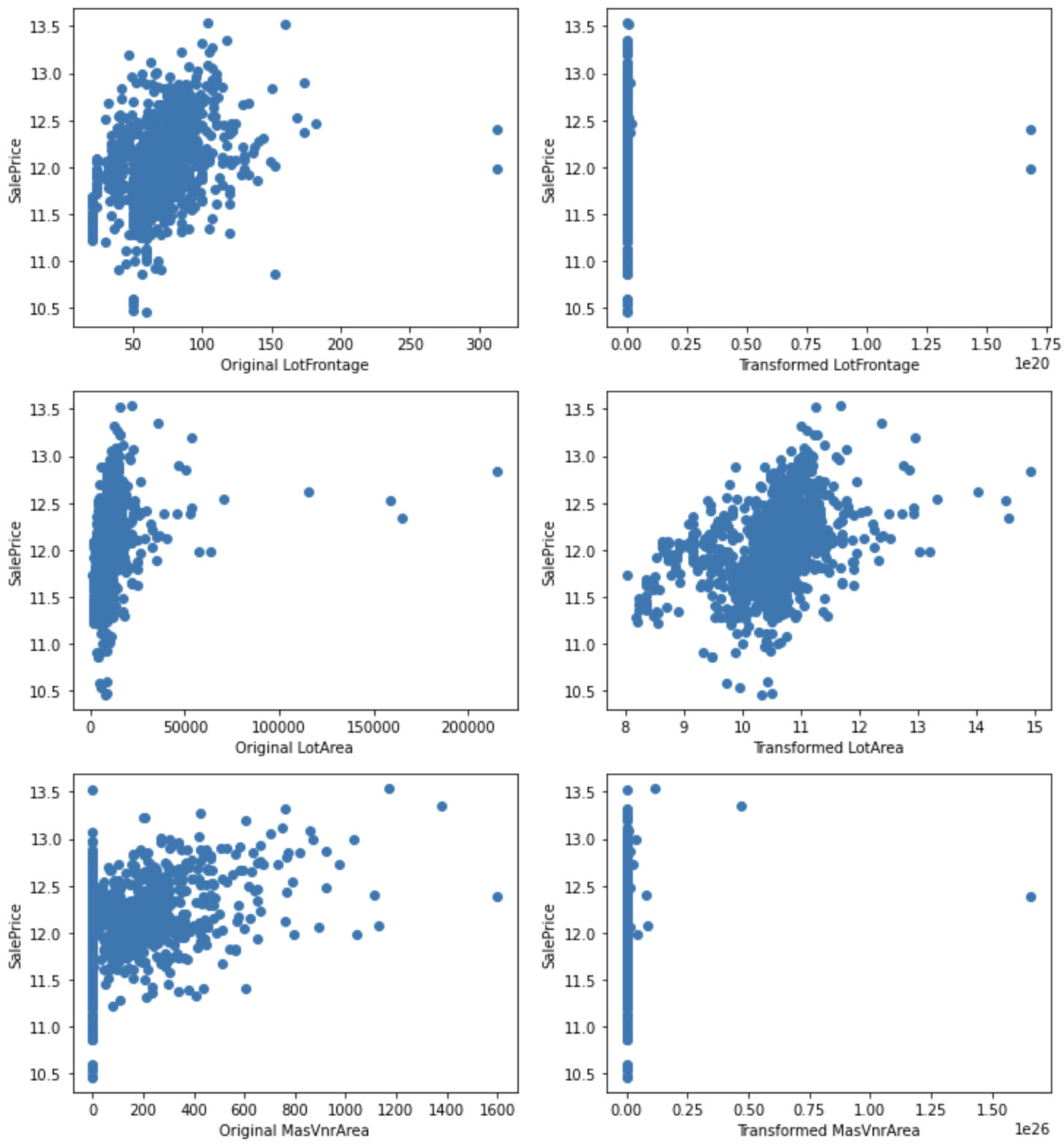
Untuk LotArea, konversi meningkatkan hubungan dengan SalePrice.
Sebagian besar variabel mengandung 0, sehingga transformasi logaritmik tidak dapat diterapkan, tetapi dapat diterapkan untuk LotFrontage, 1stFlrSF GrLivArea. Lakukan transformasi logaritmik pada variabel-variabel ini dan lihat apakah hubungan dengan HargaJual membaik.
Transformasi logaritmik
tmp = df.copy()
for var in ["LotFrontage", "1stFlrSF", "GrLivArea"]:
tmp[var] = np.log(df[var])
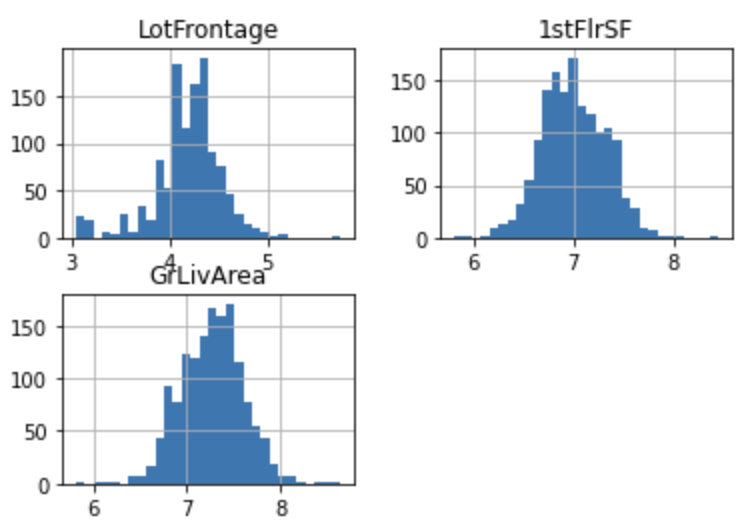
tmp[["LotFrontage", "1stFlrSF", "GrLivArea"]].hist(bins=30)
plt.show()
for var in ["LotFrontage", "1stFlrSF", "GrLivArea"]:
plt.figure(figsize=(12,4))
plt.subplot(1, 2, 1)
plt.scatter(df[var], np.log(df['SalePrice']))
plt.ylabel('SalePrice')
plt.xlabel('Original ' + var)
plt.subplot(1, 2, 2)
plt.scatter(tmp[var], np.log(tmp['SalePrice']))
plt.ylabel('SalePrice')
plt.xlabel('Transformed ' + var)
plt.show()
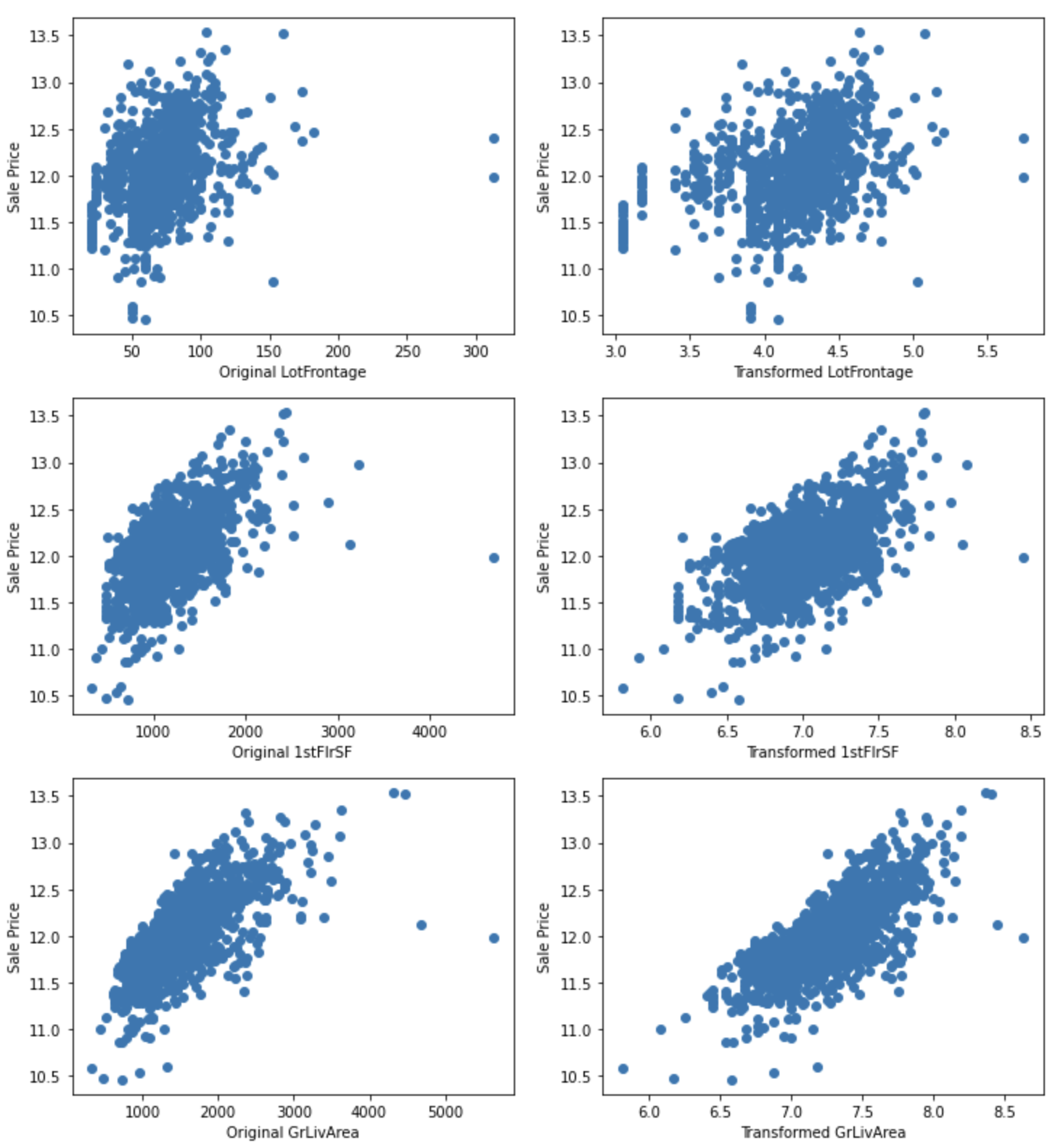
Hubungan dengan SalePrice tampaknya telah diperbaiki.
Transformasi biner
Melakukan transformasi biner pada variabel yang sangat miring.
for var in skewed:
tmp = df.copy()
tmp[var] = np.where(df[var]==0, 0, 1)
tmp = tmp.groupby(var)['SalePrice'].agg(['mean', 'std'])
tmp.plot(kind="barh", y="mean", legend=False,
xerr="std", title="Sale Price", color='green')
plt.show()
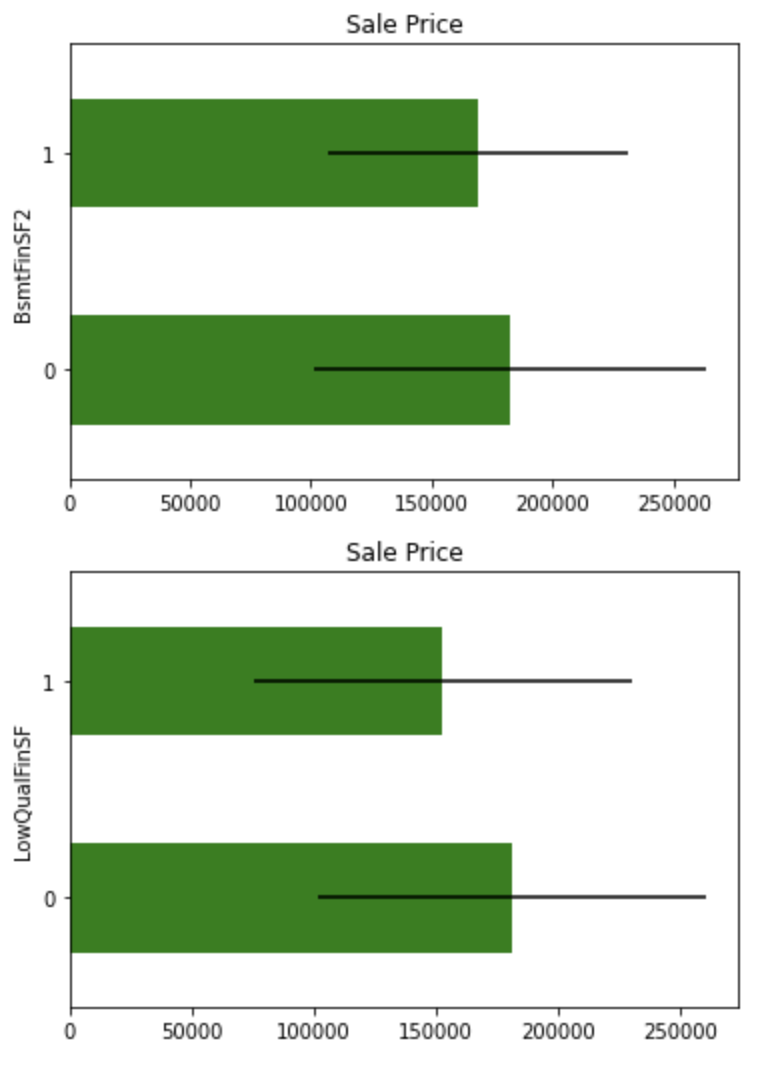
Meskipun variabel-variabel ini sedikit berbeda dalam nilai rata-rata, mereka tidak tampak sebagai variabel penjelas yang penting karena tumpang tindih dalam interval kepercayaan.
Variabel kategorikal
Kardinalitas
Periksa jumlah kategori unik.
df[cat_vars].nunique().sort_values(ascending=False).plot.bar(figsize=(12,5))
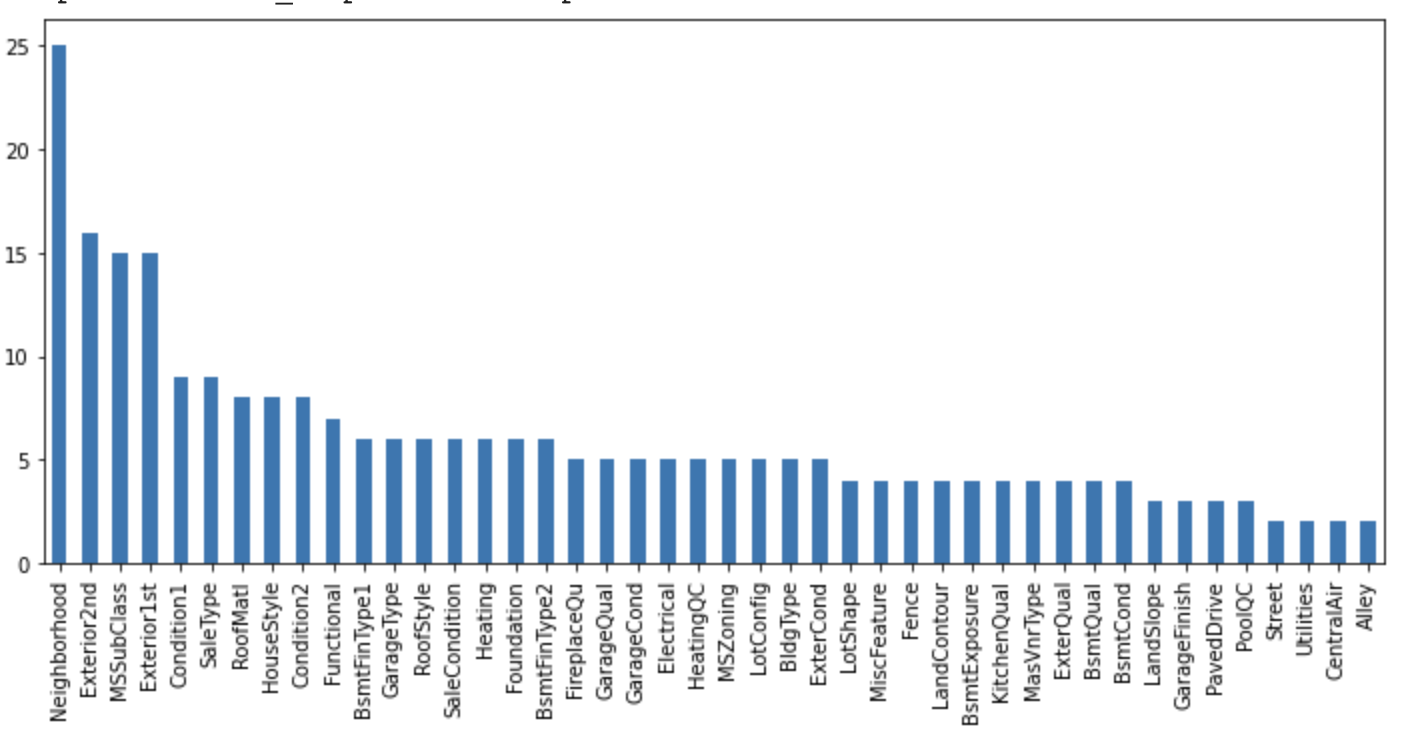
Variabel kategorikal dalam dataset ini menunjukkan kardinalitas rendah.
Label kualitas
Variabel kategori dalam dataset dapat mewakili kualitas, dalam hal ini mereka diganti dengan nilai numerik.
Kali ini, dataset berisi variabel kategori yang meningkat kualitasnya dari "Po" ke "Ex" seperti yang ditunjukkan di bawah ini. Petakan ini ke nilai numerik.
- Ex: Excellent
- Gd: Good
- TA: Average/Typical
- Fa: Fair
- Po: Poor
qual_mappings = {'Po': 1, 'Fa': 2, 'TA': 3, 'Gd': 4, 'Ex': 5, 'Missing': 0, 'NA': 0}
qual_vars = ['ExterQual', 'ExterCond', 'BsmtQual', 'BsmtCond',
'HeatingQC', 'KitchenQual', 'FireplaceQu',
'GarageQual', 'GarageCond',
]
for var in qual_vars:
df[var] = df[var].map(qual_mappings)
exposure_mappings = {'No': 1, 'Mn': 2, 'Av': 3, 'Gd': 4, 'Missing': 0, 'NA': 0}
var = 'BsmtExposure'
df[var] = df[var].map(exposure_mappings)
finish_mappings = {'Missing': 0, 'NA': 0, 'Unf': 1, 'LwQ': 2, 'Rec': 3, 'BLQ': 4, 'ALQ': 5, 'GLQ': 6}
finish_vars = ['BsmtFinType1', 'BsmtFinType2']
for var in finish_vars:
df[var] = df[var].map(finish_mappings)
garage_mappings = {'Missing': 0, 'NA': 0, 'Unf': 1, 'RFn': 2, 'Fin': 3}
var = 'GarageFinish'
df[var] = df[var].map(garage_mappings)
fence_mappings = {'Missing': 0, 'NA': 0, 'MnWw': 1, 'GdWo': 2, 'MnPrv': 3, 'GdPrv': 4}
var = 'Fence'
df[var] = df[var].map(fence_mappings)
qual_vars = qual_vars + finish_vars + ['BsmtExposure','GarageFinish','Fence']
for var in qual_vars:
sns.catplot(x=var, y='SalePrice', data=df, kind="box", height=4, aspect=1.5)
sns.stripplot(x=var, y='SalePrice', data=df, jitter=0.1, alpha=0.3, color='k')
plt.show()
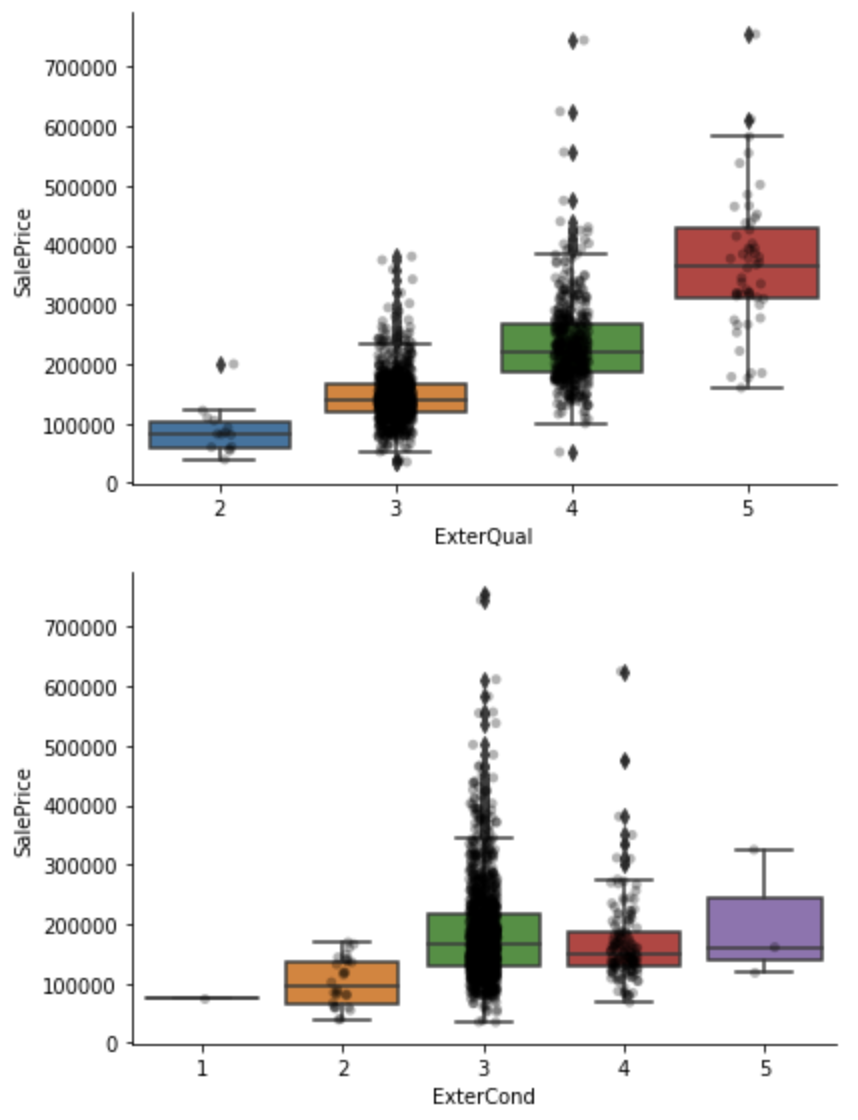
Label langka
Beberapa variabel kategorikal mungkin memiliki label yang hadir kurang dari 1% dari waktu. Label yang kurang terwakili dalam dataset cenderung menyebabkan overfitting model pembelajaran mesin, sehingga harus dihapus. Kode berikut mengekstrak label yang muncul kurang dari 1% dari waktu.
cat_others = [
var for var in cat_vars if var not in qual_vars
]
def analyse_rare_labels(df_, var, rare_perc):
df = df_.copy()
tmp = df.groupby(var)['SalePrice'].count() / len(df)
return tmp[tmp < rare_perc]
for var in cat_others:
print(analyse_rare_labels(df, var, 0.01))
print()
MSZoning
C (all) 0.006849
Name: SalePrice, dtype: float64
Street
Grvl 0.00411
Name: SalePrice, dtype: float64
.
.
.
Kesimpulan
EDA hanyalah salah satu contoh, masih banyak lagi hal yang harus dianalisis, dan EDA yang baik serta pemahaman yang mendalam tentang data diperlukan oleh para ilmuwan data.
Referensi

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS