



Introduction
In recent years, the fields of machine learning and natural language processing have been rapidly advancing. Among these, the Large Language Model (LLM) has garnered significant attention from researchers and developers.
By storing the latest information obtained from in-house documents or web scraping in a database and integrating it with the LLM, it is expected that the system can provide responses inclusive of the most up-to-date information.
In this article, I explain how to build an LLM system using proprietary data, utilizing Vector DB.
System Architecture
Document Ingestion
The architecture of many document ingestion systems in LLM systems using proprietary data is roughly as follows.
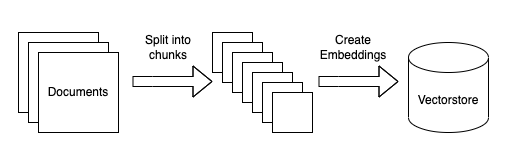
Ingest a Series of Documents
The initial phase in embedding unique data into the LLM system involves acquiring the requisite documents. Various methods such as API access and web scraping can be employed to achieve this.
Divide Documents into Smaller Chunks
To ensure the LLM system can process data effectively, it is beneficial to fragment larger documents into more manageable segments, like paragraphs or sentences. This segmentation process facilitates the efficient extraction of vital data in later stages.
Create Vector Representations for Each Document
Each chunk is converted into a high-dimensional vector representation. These vectors are stored in the vector database for use in later query processing.
Query
The query of the LLM system follows an architectural design, as shown below.
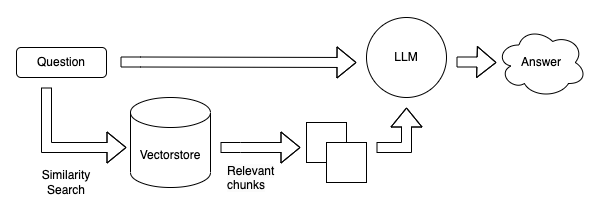
Generate a Vector for the Query
When a query is submitted by a user, the system promptly creates a vector representation of it. This step enables the efficient calculation of similarity scores between the query and the stored document chunks.
Search for the Most Similar Document in the Vector Database
Leveraging the vector database, the system looks for the document vector with the highest similarity to the query vector. This search procedure allows the system to swiftly pinpoint documents that bear relevance to the user's query.
Supply Document and Original Query to LLM to Generate a Response
Lastly, the document selected from the vector database, along with the original query, is fed into the LLM system. This system then generates a suitable response based on the given inputs and conveys it to the user.
References















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS