
Introduction
The success of a machine learning model is determined by its ability to accurately predict outcomes based on input data. A successful model should generalize well to new, unseen data, making accurate predictions that reflect the underlying patterns and relationships in the data. To achieve this, model performance must be optimized to strike a balance between capturing the essential structure of the data and avoiding overfitting or underfitting.
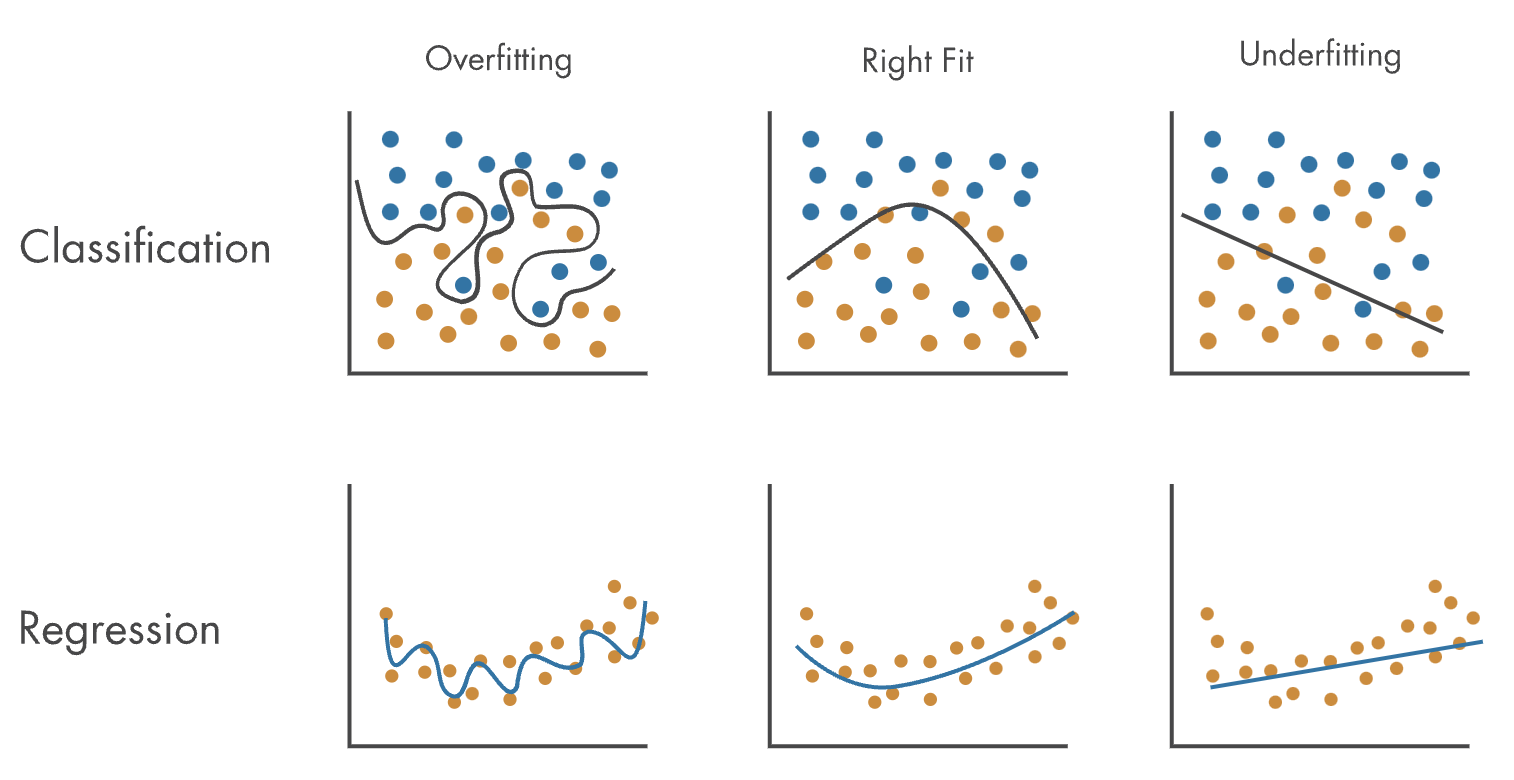
Avoid overfitting machine learning models
What is Underfitting
Underfitting is a situation in which a machine learning model fails to capture the underlying pattern or structure in the training data. In other words, the model is too simple to accurately represent the relationships between input features and output predictions. As a result, underfitted models tend to have poor performance on both training and testing datasets.
Causes of Underfitting
Several factors can lead to underfitting in machine learning models:
-
Insufficient Model Complexity
When a model is not complex enough to represent the true relationship between input features and output predictions, it can result in underfitting. For example, using a linear regression model for a problem with non-linear relationships between variables. -
Inadequate Feature Engineering
If the input features do not provide enough information about the output predictions, the model will struggle to learn the relationship between them, leading to underfitting. This can be due to a lack of relevant features or poor feature representation. -
Overly Strong Regularization
Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function. However, if the regularization term is too large, it can constrain the model excessively, causing it to underfit the data.
Implications of Underfitting on Model Performance
Underfitting has several negative consequences on the performance of a machine learning model:
-
Low Training and Testing Accuracy
An underfitted model will not perform well on the training dataset, as it fails to capture the underlying structure in the data. This poor performance will also be observed on the testing dataset, resulting in low predictive accuracy. -
High Bias
Underfitting is often characterized by high bias, meaning the model consistently produces predictions that deviate from the true values. High bias indicates that the model's assumptions about the data are incorrect or oversimplified. -
Poor Generalization
Since an underfitted model does not capture the underlying relationships in the training data, it will struggle to generalize well to new, unseen data.
What is Overfitting
Overfitting occurs when a machine learning model captures not only the underlying pattern or structure in the training data but also the noise and random fluctuations. In other words, the model becomes too complex and fits the training data too closely, resulting in poor generalization to new, unseen data. Overfitted models tend to have excellent performance on the training dataset but perform poorly on the testing dataset.
Causes of Overfitting
Several factors can contribute to overfitting in machine learning models:
-
Excessive Model Complexity
When a model is too complex, it can easily adapt to the training data's noise and fluctuations, leading to overfitting. For example, using a deep neural network with many layers and neurons for a problem with limited training data. -
Insufficient Training Data
If the training dataset is too small or not representative of the population, the model can learn to fit the training data too closely, resulting in overfitting. -
Inadequate Regularization
If the regularization term is too small, it can allow the model to become overly complex, causing it to overfit the data.
Implications of Overfitting on Model Performance
Overfitting has several negative consequences on the performance of a machine learning model:
-
High Training Accuracy, Low Testing Accuracy
An overfitted model will have excellent performance on the training dataset, as it captures the underlying structure and noise in the data. However, this high accuracy will not translate to the testing dataset, where the model will perform poorly. -
High Variance
Overfitting is often characterized by high variance, meaning the model's predictions are highly sensitive to small changes in the input data. High variance indicates that the model is too complex and does not generalize well to new data. -
Poor Generalization
Since an overfitted model learns to fit the noise in the training data, it will struggle to generalize well to new, unseen data.
References


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS