
Serving patterns for ML systems
There are various ways of serving inference in machine learning systems. In this article, I introduce the following serving pattern for ML systems, which is described in Mercari's GitHub.
- Web-single pattern
- Synchronous pattern
- Asynchronous pattern
- Batch pattern
- Prep-pred pattern
- Serial microservices pattern
- Parallel microservices pattern
- Inference cache pattern
- Data cache pattern
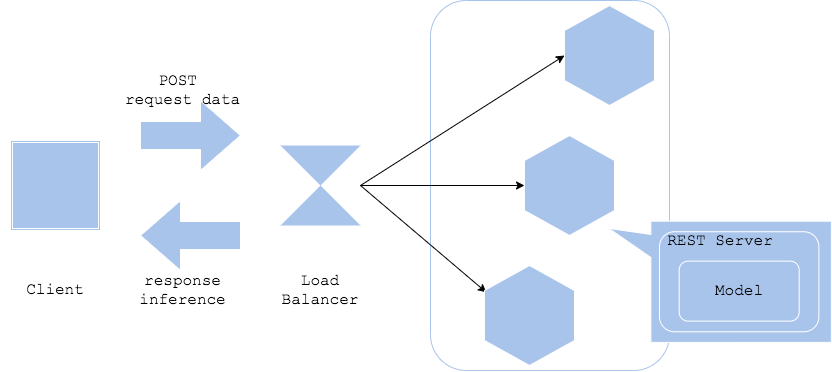
Web-single pattern
The Web-single pattern bundles models with a web server. By installing a REST interface (or GRPC), preprocessing, and trained models on the same server, a simple inference server can be generated.
- Pros
- Web, preprocessing, and inference can be implemented in the same programming language
- Simple structure and easy operation
- Cons
- Components (web, preprocessing, inference) are enclosed in the same container image, so components cannot be updated individually
- Use cases
- Simple configuration for quick release of inference server
- When only one model returns inferences synchronously
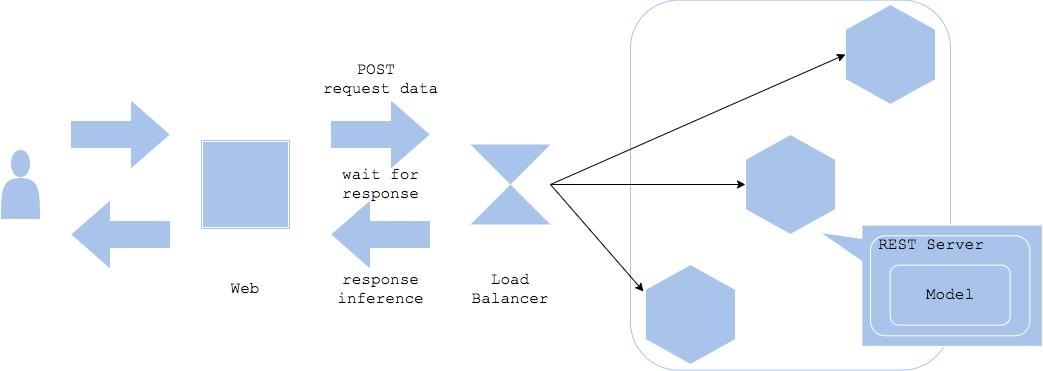
Synchronous pattern
In the synchronous pattern, the web server and the inference server are separated, and inference is handled synchronously. The client waits until it receives a response to its inference request.
- Pros
- Simple structure and easy to operate
- Clients do not move on to the next process until inference is complete, making it easy to think about workflows
- Cons
- Inference tends to be a performance bottleneck
- Inference waits, so it is necessary to consider ways to avoid degrading the user experience during this time
- Use cases
- When the workflow of an application is such that it cannot proceed to the next step until the inference result is obtained
- When the workflow depends on the inference result
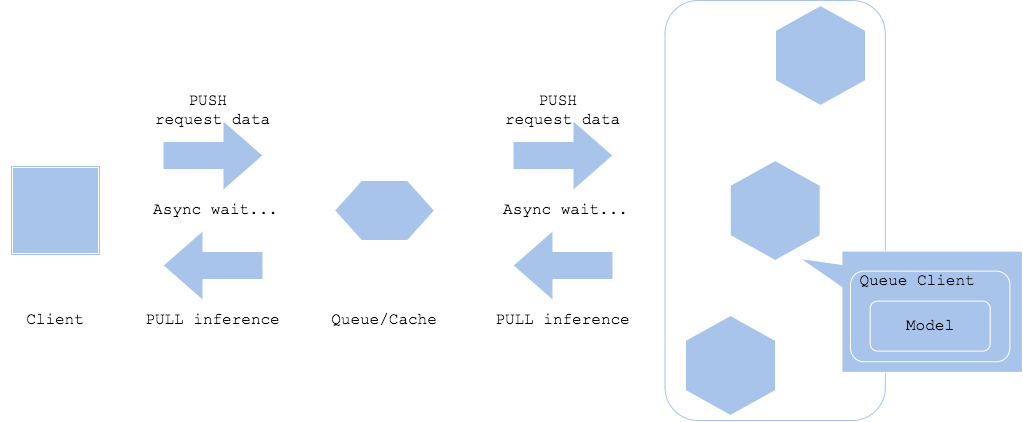
Asynchronous pattern
In the Asynchronous pattern, a queue or cache is placed between the request and inference, and the inference request and inference result are obtained asynchronously. In this pattern, by separating request and inference, there is no need to wait for inference time in the client workflow.
- Pros
- Can decouple inference from the client
- Less client impact even when inference waits for long periods of time
- Cons
- Requires queues and caches
- Not suitable for real-time processing
- Use cases
- For workflows in which the immediate post-processing behavior does not depend on the inference result
- Separate client and output destination for inference results
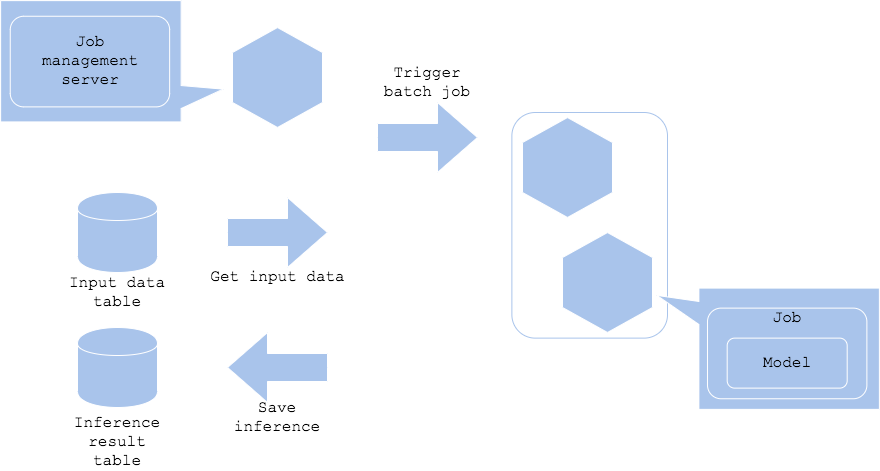
Batch pattern
When inference does not need to be performed in real-time, a batch job can be started to perform inference periodically. In this pattern, accumulated data can be inferred periodically, such as at night, and the results can be saved.
- Pros
- Flexible server resource management
- If inference fails for some reason, it can be done again.
- Cons
- Job management server is needed.
- Use cases
- When real-time or quasi-real-time inference is not required
- When you want to perform summary inference on historical data
You want to infer data periodically, such as at night, hourly, monthly, etc.
Prep-pred pattern
Preprocessing and inference may require different resources and libraries. In such cases, you can split servers or containers between preprocessors and inferencers to streamline development and operation. While dividing preprocessors and inferencers allows for efficient resource utilization, individual development, and fault isolation, it also requires tuning of each resource, mutual network design, and versioning. This pattern is often used when deep learning is used as the inferencers.
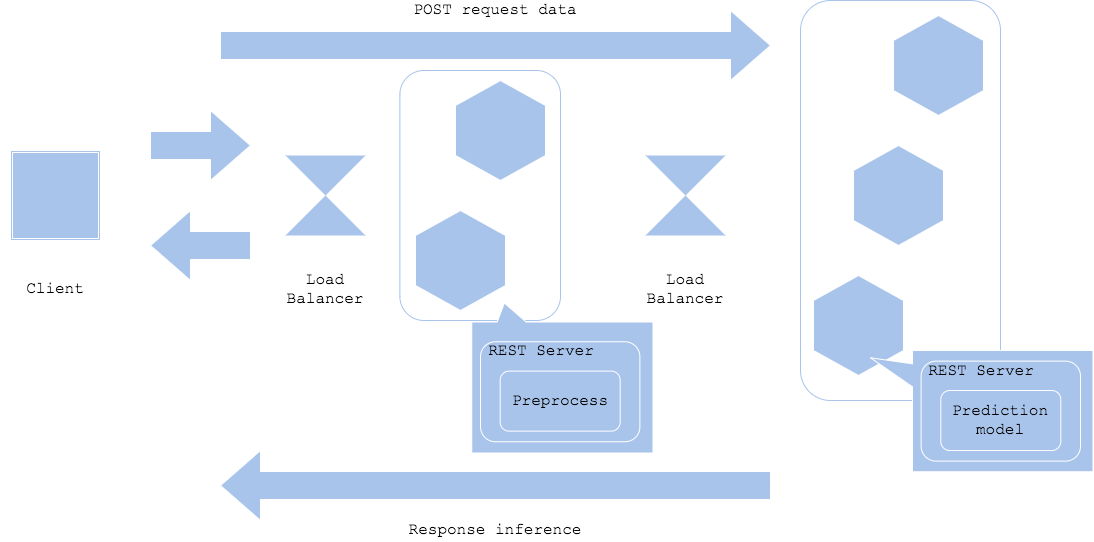
Simple prep-pred pattern
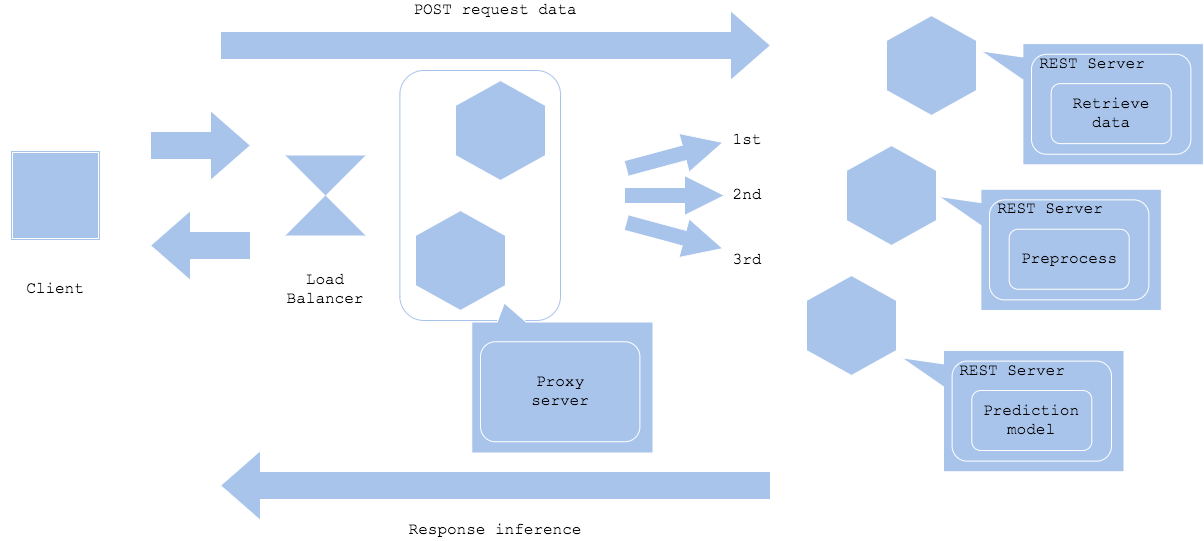
Microservice prep-pred pattern
- Pros
- Enables fault isolation
- Allows flexibility in selecting libraries and increasing or decreasing resources
- Cons
- Increased complexity of managed servers and network configuration, resulting in increased operational load
- Network between preprocessing server and inference server may become a bottleneck
- Use cases
- Libraries, code base, and resource load are different between preprocessing and inference
- When you want to improve availability by splitting up preprocessing and inference
Serial microservices pattern
If you want to run multiple inference models in sequence, deploy multiple machine learning models in parallel on separate servers. Send inference requests to each in turn, and get inference results after aggregating the last inference.
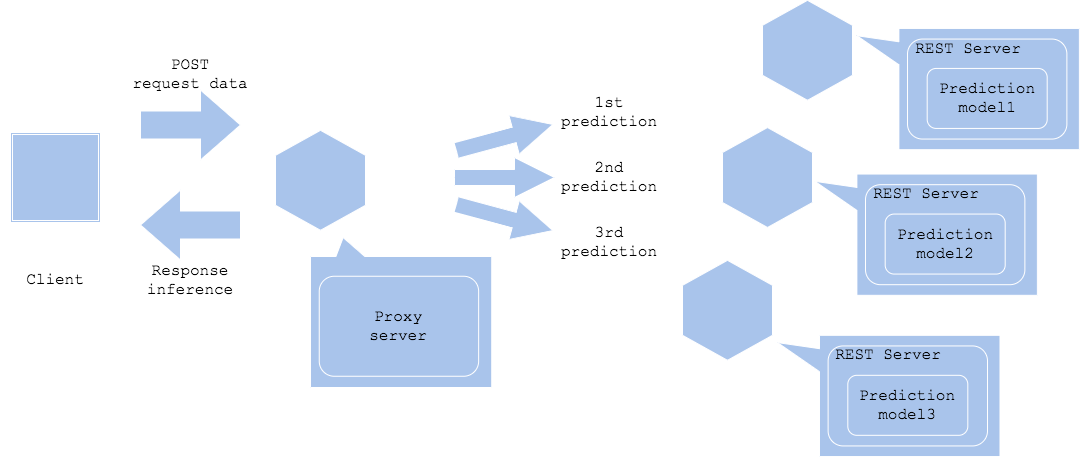
- Pros
- Each inference model can be executed in turn
- Can be configured to select the inference request destination for the next model depending on the results of the previous inference model
- By dividing the server and codebase for each inference, resource efficiency and fault isolation can be improved.
- Cons
- Multiple inferences are executed in sequence, which may increase the time required.
- If the result of the previous inference is not obtained, the next inference cannot be executed, creating a bottleneck
- System configuration may become more complex
- use cases
- When multiple inferences are performed for a single operation
- When there is an execution order or dependency between multiple inferences
Parallel microservices pattern
In the parallel microservice pattern, inference requests are sent to each inference server in parallel to obtain multiple inference results.
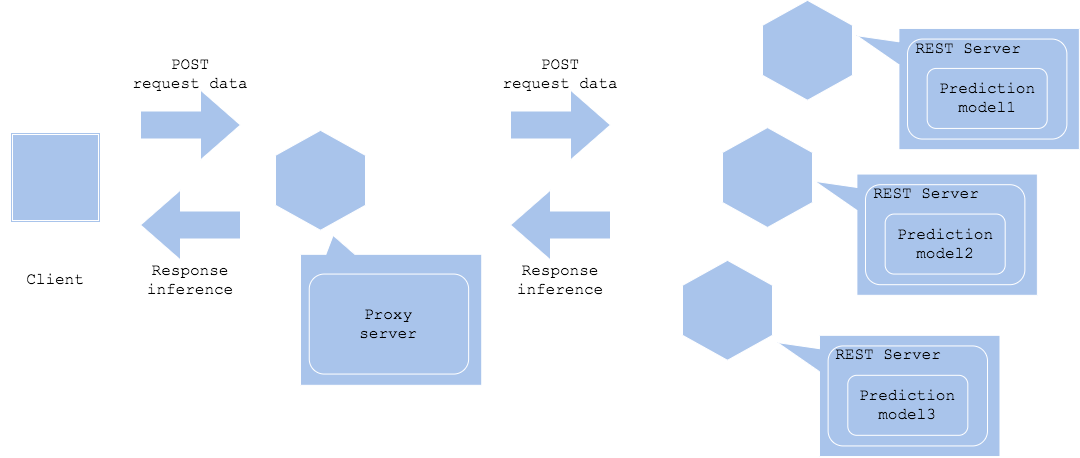
Synchronized horizontal
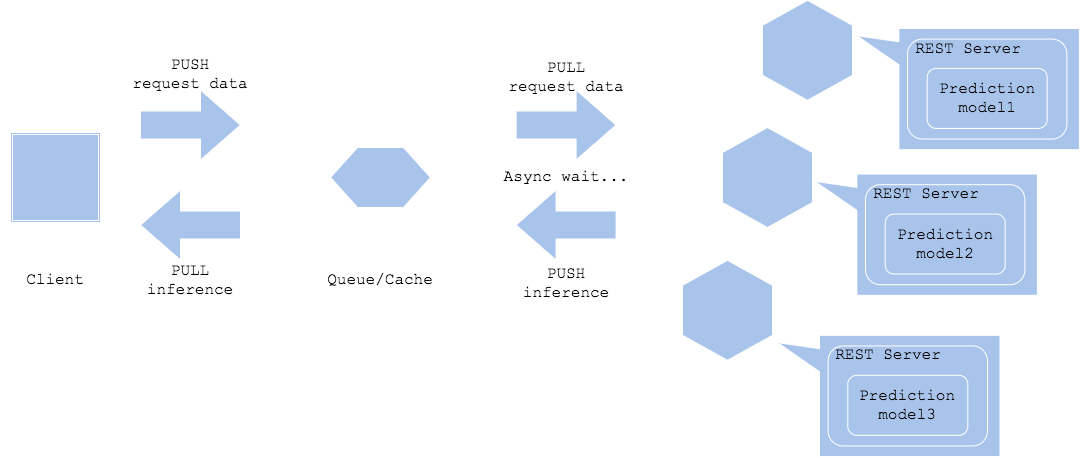
Asynchronized horizontal
- Pros
- Splitting the inference server allows for resource coordination and fault isolation
- Flexible system construction without dependencies among inference workflows
- Cons
- System can be complex due to running multiple inferences
- When running synchronously, the time required depends on the slowest inference
- Asynchronous execution requires a later workflow to compensate for time differences between inference servers.
- Use cases
- Multiple inferences without dependencies are executed in parallel
- In the case of a workflow where multiple inference results are aggregated at the end
Inference cache pattern
In the inference cache pattern, inference results are stored in a cache, and inferences on the same data are searched in the cache.
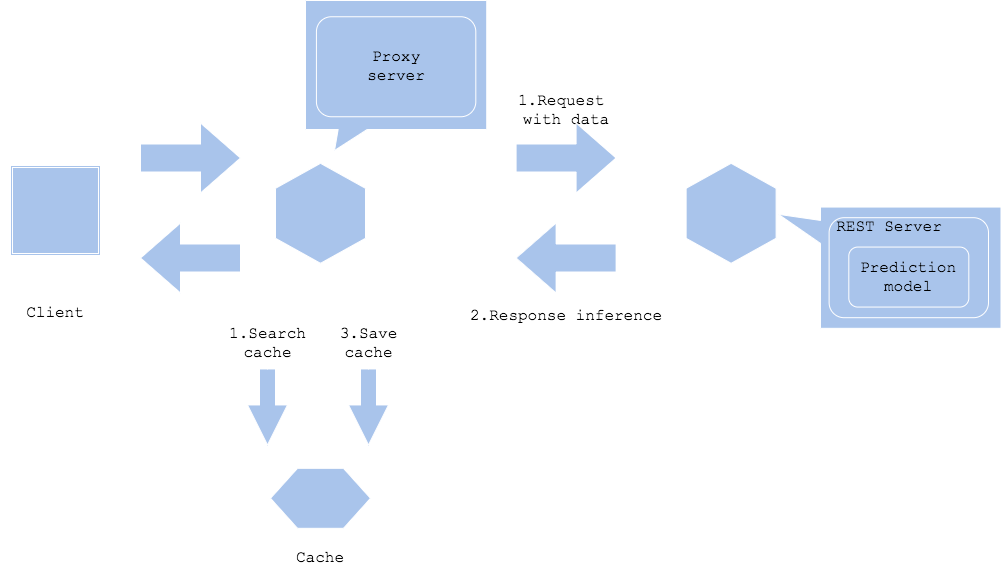
- Pros
- Can improve inference speed and offload load to the inference server
- Cons
- Incurs cache server costs (many caches tend to cost more and have smaller capacity than storage)
- Need to consider cache clearing policy
- Use cases
- Frequent inference requests for the same data
- For input data that can be searched by cache keys
- When you want to process inference at high speed
Data cache pattern
The data cache pattern caches data. Contents such as images and text tend to have large data size. If the size of input data or preprocessing data is large, data cache can reduce the load of data acquisition.
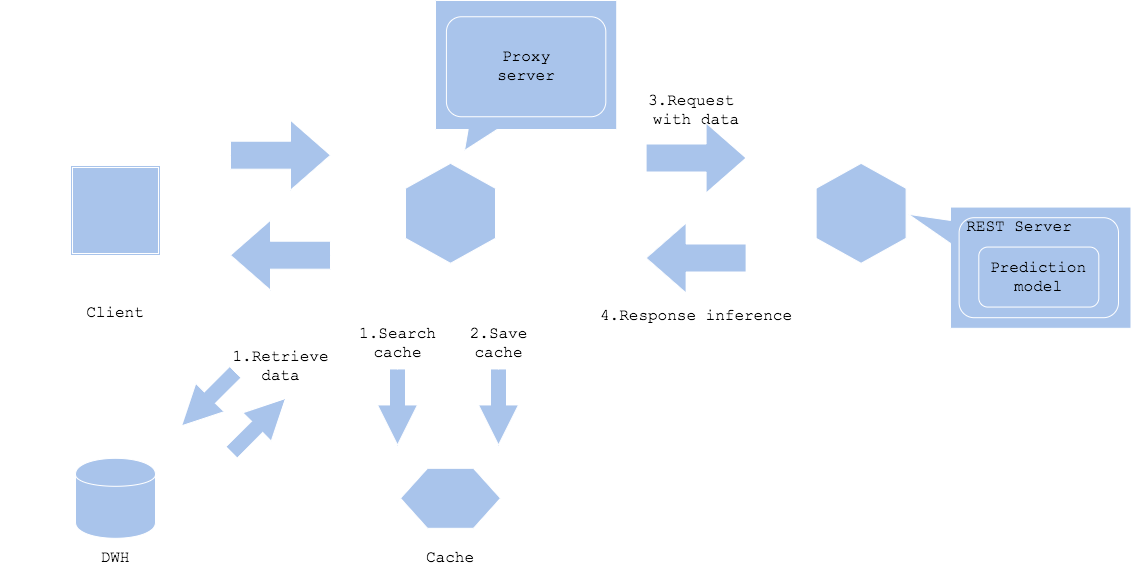
Input data cache
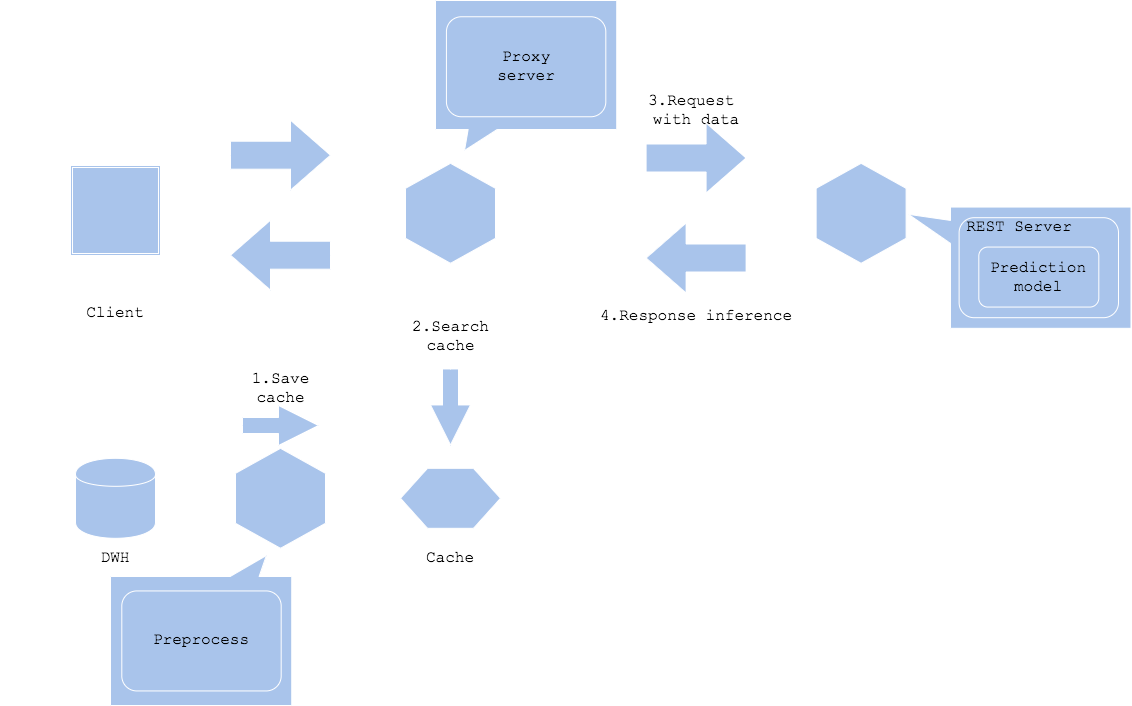
Preprocessed data cache
- Pros
- Can reduce data acquisition and preprocessing overhead
- Fast inference startup
- Cons
- Cache server cost is incurred
- Need to consider cache clearing policy
- Use cases
- Workflow with inference requests for the same data
- For repeated input data of the same data
- For input data that can be searched by cache keys
- When you want to speed up data processing
References


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS