

Modular pipelines
Kedro allows you to modularize your pipelines to create reusable pipelines. For example, you can run multiple pipelines that differ only in features. Modular pipelines are easier to develop, test, and maintain and are more portable.
Extending project with modular pipelines
Let us extend the pipeline of spaceflights Starter provided by Kedro. First, prepare your spaceflights project.
$ kedro new --starter=spaceflights
$ cd spaceflights
$ pip install -r src/requirements.txt
We will now add namespaces with the following different parameters to the modeling component of the data science pipeline.
active_modelling_pipelinecandidate_modelling_pipeline
Edit conf/base/parameters/data_science.yml as follows.
- model_options:
- test_size: 0.2
- random_state: 3
- features:
- - engines
- - passenger_capacity
- - crew
- - d_check_complete
- - moon_clearance_complete
- - iata_approved
- - company_rating
- - review_scores_rating
+ active_modelling_pipeline:
+ model_options:
+ test_size: 0.2
+ random_state: 3
+ features:
+ - engines
+ - passenger_capacity
+ - crew
+ - d_check_complete
+ - moon_clearance_complete
+ - iata_approved
+ - company_rating
+ - review_scores_rating
+
+ candidate_modelling_pipeline:
+ model_options:
+ test_size: 0.2
+ random_state: 8
+ features:
+ - engines
+ - passenger_capacity
+ - crew
+ - review_scores_rating
Edit conf/base/catalog.yml as follows.
- regressor:
- type: pickle.PickleDataSet
- filepath: data/06_models/regressor.pickle
- versioned: true
+ active_modelling_pipeline.regressor:
+ type: pickle.PickleDataSet
+ filepath: data/06_models/regressor_active.pickle
+ versioned: true
+
+ candidate_modelling_pipeline.regressor:
+ type: pickle.PickleDataSet
+ filepath: data/06_models/regressor_candidate.pickle
+ versioned: true
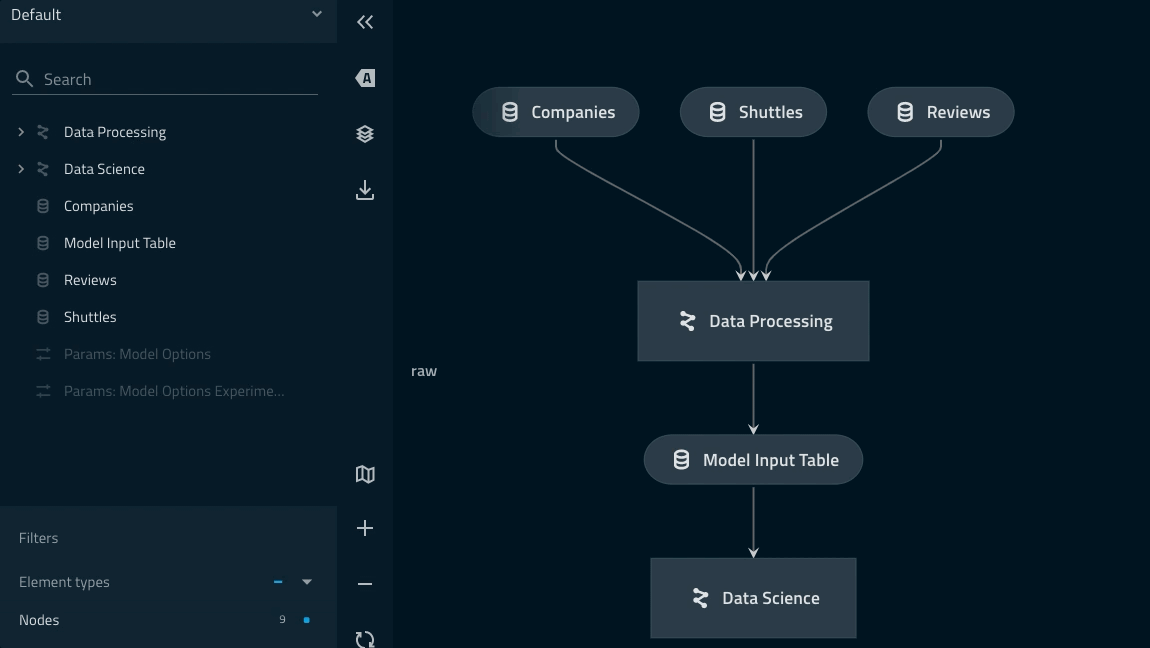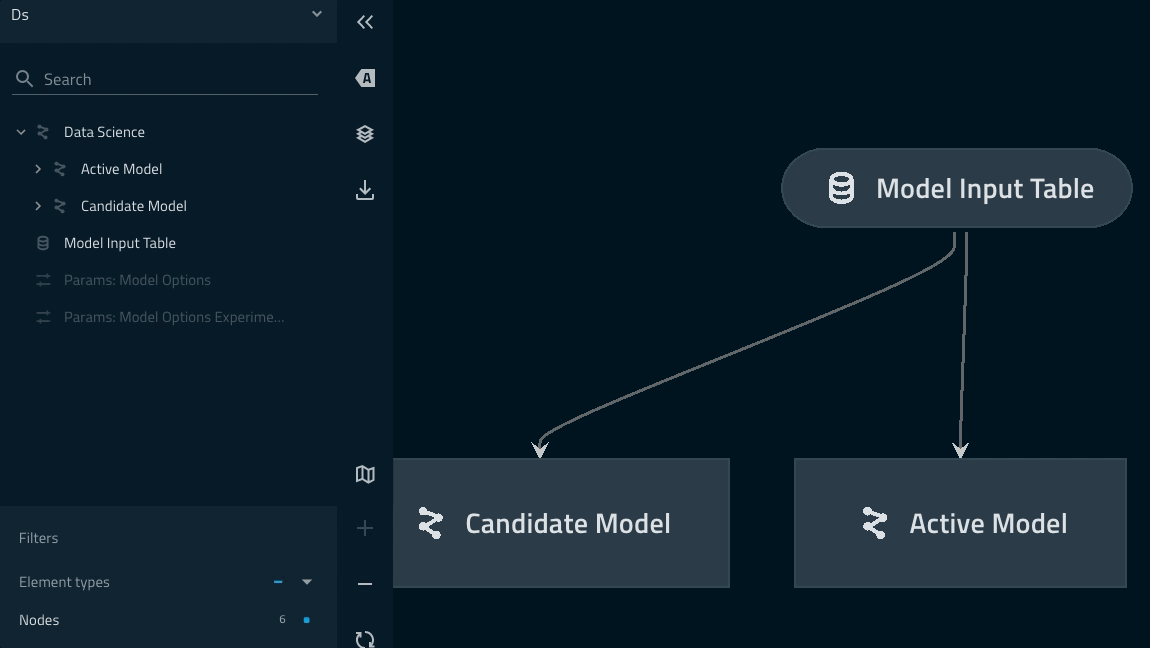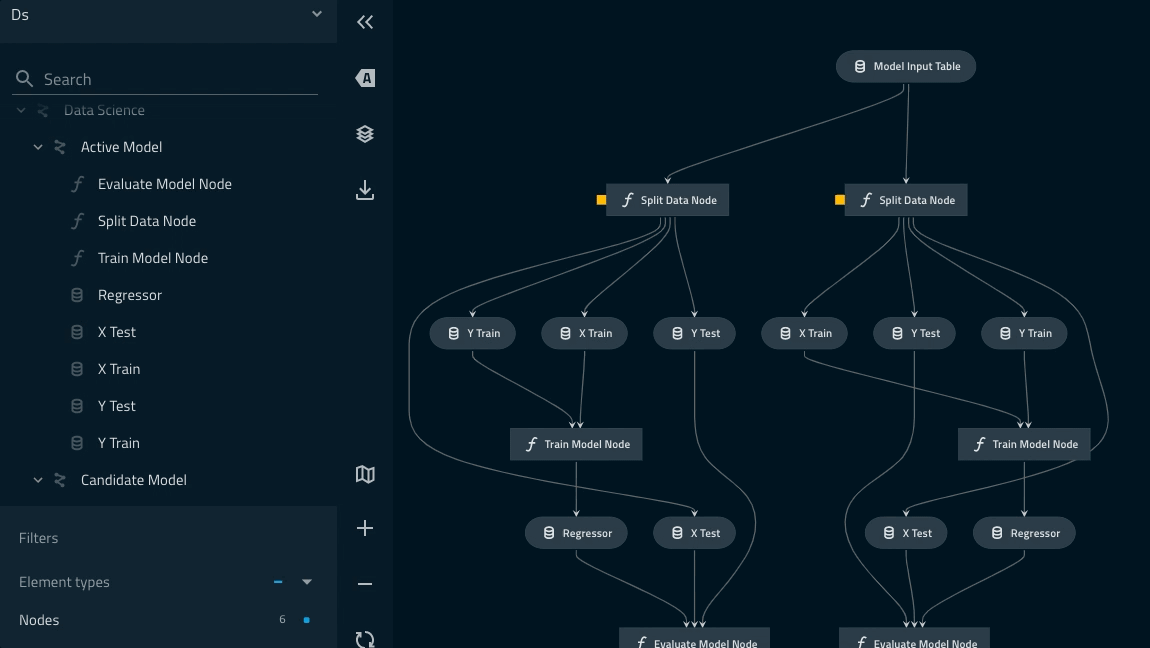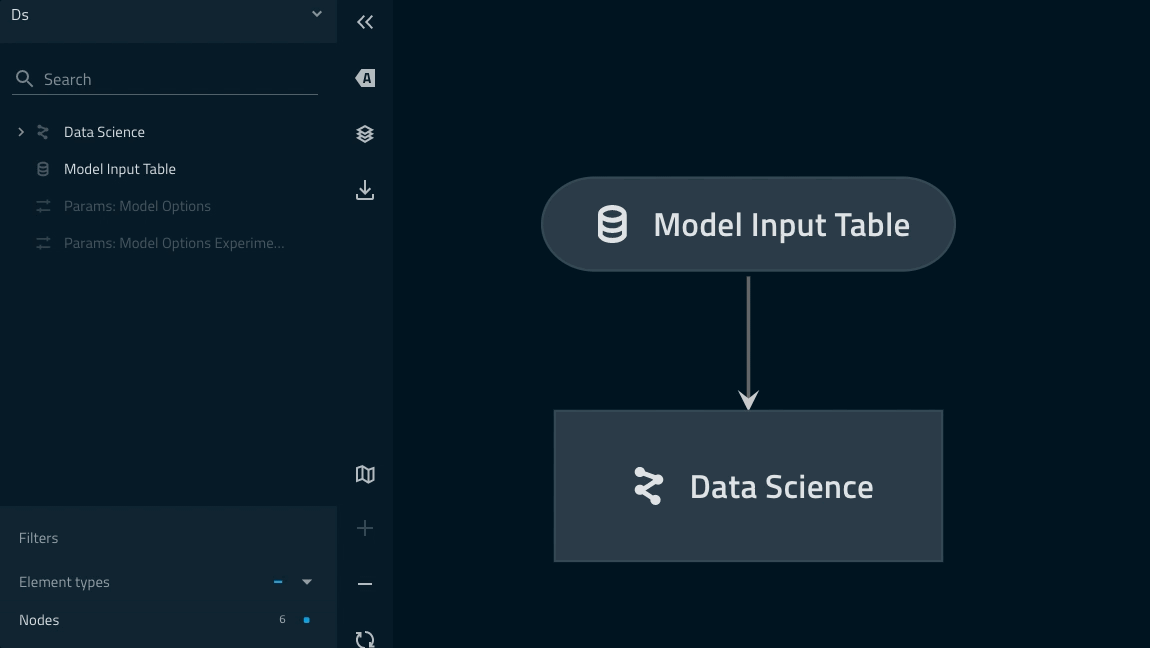
Edit pipelines/data_science/pipeline.py as follows.
from kedro.pipeline import Pipeline, node
- from kedro.pipeline import pipeline
+ from kedro.pipeline.modular_pipeline import pipeline
from .nodes import evaluate_model, split_data, train_model
def create_pipeline(**kwargs) -> Pipeline:
- return pipeline(
- [
- node(
- func=split_data,
- inputs=["model_input_table", "params:model_options"],
- outputs=["X_train", "X_test", "y_train", "y_test"],
- name="split_data_node",
- ),
- node(
- func=train_model,
- inputs=["X_train", "y_train"],
- outputs="regressor",
- name="train_model_node",
- ),
- node(
- func=evaluate_model,
- inputs=["regressor", "X_test", "y_test"],
- outputs=None,
- name="evaluate_model_node",
- ),
- ]
- )
+ pipeline_instance = pipeline(
+ [
+ node(
+ func=split_data,
+ inputs=["model_input_table", "params:model_options"],
+ outputs=["X_train", "X_test", "y_train", "y_test"],
+ name="split_data_node",
+ ),
+ node(
+ func=train_model,
+ inputs=["X_train", "y_train"],
+ outputs="regressor",
+ name="train_model_node",
+ ),
+ node(
+ func=evaluate_model,
+ inputs=["regressor", "X_test", "y_test"],
+ outputs=None,
+ name="evaluate_model_node",
+ ),
+ ]
+ )
+ ds_pipeline_1 = pipeline(
+ pipe=pipeline_instance,
+ inputs="model_input_table",
+ namespace="active_modelling_pipeline",
+ )
+ ds_pipeline_2 = pipeline(
+ pipe=pipeline_instance,
+ inputs="model_input_table",
+ namespace="candidate_modelling_pipeline",
+ )
+
+ return ds_pipeline_1 + ds_pipeline_2
If you run kedro run, you will see that both active_modelling_pipeline and candidate_modelling_pipeline pipelines are running.
$ kedro run
[11/02/22 10:41:06] WARNING /Users/<username>/opt/anaconda3/envs/py38/lib/python3.8/site-packages/plotly/graph_objects/ warnings.py:109
__init__.py:288: DeprecationWarning: distutils Version classes are deprecated. Use
packaging.version instead.
if LooseVersion(ipywidgets.__version__) >= LooseVersion("7.0.0"):
[11/02/22 10:41:07] INFO Kedro project kedro-tutorial session.py:340
[11/02/22 10:41:08] INFO Loading data from 'companies' (CSVDataSet)... data_catalog.py:343
INFO Running node: preprocess_companies_node: preprocess_companies([companies]) -> node.py:327
[preprocessed_companies]
INFO Saving data to 'preprocessed_companies' (ParquetDataSet)... data_catalog.py:382
INFO Completed 1 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'shuttles' (ExcelDataSet)... data_catalog.py:343
[11/02/22 10:41:13] INFO Running node: preprocess_shuttles_node: preprocess_shuttles([shuttles]) -> node.py:327
[preprocessed_shuttles]
WARNING /Users/<username>/Documents/kedro-projects/kedro-tutorial/src/kedro_tutorial/pipelines/data warnings.py:109
_processing/nodes.py:19: FutureWarning: The default value of regex will change from True to
False in a future version. In addition, single character regular expressions will *not* be
treated as literal strings when regex=True.
x = x.str.replace("$", "").str.replace(",", "")
INFO Saving data to 'preprocessed_shuttles' (ParquetDataSet)... data_catalog.py:382
INFO Completed 2 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'preprocessed_shuttles' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'preprocessed_companies' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'reviews' (CSVDataSet)... data_catalog.py:343
INFO Running node: create_model_input_table_node: node.py:327
create_model_input_table([preprocessed_shuttles,preprocessed_companies,reviews]) ->
[model_input_table]
^[[B[11/02/22 10:41:14] INFO Saving data to 'model_input_table' (ParquetDataSet)... data_catalog.py:382
[11/02/22 10:41:15] INFO Completed 3 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'model_input_table' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'params:active_modelling_pipeline.model_options' (MemoryDataSet)... data_catalog.py:343
INFO Running node: split_data_node: node.py:327
split_data([model_input_table,params:active_modelling_pipeline.model_options]) ->
[active_modelling_pipeline.X_train,active_modelling_pipeline.X_test,active_modelling_pipeline.y_t
rain,active_modelling_pipeline.y_test]
INFO Saving data to 'active_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'active_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'active_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'active_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:382
INFO Completed 4 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'model_input_table' (ParquetDataSet)... data_catalog.py:343
INFO Loading data from 'params:candidate_modelling_pipeline.model_options' (MemoryDataSet)... data_catalog.py:343
INFO Running node: split_data_node: node.py:327
split_data([model_input_table,params:candidate_modelling_pipeline.model_options]) ->
[candidate_modelling_pipeline.X_train,candidate_modelling_pipeline.X_test,candidate_modelling_pip
eline.y_train,candidate_modelling_pipeline.y_test]
INFO Saving data to 'candidate_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'candidate_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'candidate_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:382
INFO Saving data to 'candidate_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:382
INFO Completed 5 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'active_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'active_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:343
INFO Running node: train_model_node: node.py:327
train_model([active_modelling_pipeline.X_train,active_modelling_pipeline.y_train]) ->
[active_modelling_pipeline.regressor]
INFO Saving data to 'active_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:382
INFO Completed 6 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'candidate_modelling_pipeline.X_train' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'candidate_modelling_pipeline.y_train' (MemoryDataSet)... data_catalog.py:343
INFO Running node: train_model_node: node.py:327
train_model([candidate_modelling_pipeline.X_train,candidate_modelling_pipeline.y_train]) ->
[candidate_modelling_pipeline.regressor]
INFO Saving data to 'candidate_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:382
INFO Completed 7 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'active_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:343
INFO Loading data from 'active_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'active_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:343
INFO Running node: evaluate_model_node: node.py:327
evaluate_model([active_modelling_pipeline.regressor,active_modelling_pipeline.X_test,active_model
ling_pipeline.y_test]) -> None
INFO Model has a coefficient R^2 of 0.462 on test data. nodes.py:60
INFO Completed 8 out of 9 tasks sequential_runner.py:85
INFO Loading data from 'candidate_modelling_pipeline.regressor' (PickleDataSet)... data_catalog.py:343
INFO Loading data from 'candidate_modelling_pipeline.X_test' (MemoryDataSet)... data_catalog.py:343
INFO Loading data from 'candidate_modelling_pipeline.y_test' (MemoryDataSet)... data_catalog.py:343
INFO Running node: evaluate_model_node: node.py:327
evaluate_model([candidate_modelling_pipeline.regressor,candidate_modelling_pipeline.X_test,candid
ate_modelling_pipeline.y_test]) -> None
INFO Model has a coefficient R^2 of 0.449 on test data. nodes.py:60
INFO Completed 9 out of 9 tasks sequential_runner.py:85
INFO Pipeline execution completed successfully.
pipeline() wrapper
The following imports allow the creation of multiple instances of a pipeline with dynamic inputs and outputs and parameters.
from kedro.pipeline.modular_pipeline import pipeline
The arguments to pipeline() are as follows
| Keyword argument | Description |
|---|---|
pipe |
The Pipeline object you want to wrap |
inputs |
Any overrides provided to this instance of the underlying wrapped Pipeline object |
outputs |
Any overrides provided to this instance of the underlying wrapped Pipeline object |
parameters |
Any overrides provided to this instance of the underlying wrapped Pipeline object |
namespace |
The namespace that will be encapsulated by this pipeline instance |
Pipeline linage can be checked with the kedro viz command.
References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS