

Epoch and batch size
In machine learning, training data is divided into clusters of samples and weights are optimized for each clump. The number of samples in a batch is called the batch size, which is basically a constant value.
Training all the training data once is called an epoch.
The weights and biases are updated each epoch by finding the average of the errors in the batch. The errors are defined as follows, with the batch size as
The gradient of the error weight
Since the weights and biases are updated after all samples in a batch have been used, the batch size can also be expressed as the interval between weight and bias modifications.
An example of a batch is shown below using a diagram of training data with 1,000 samples.
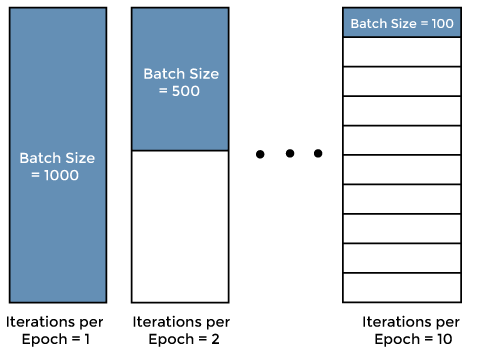
A batch size of 1,000 is equal to the number of samples in the training data, and the weights and biases are updated once per epoch. This type of learning where the number of training data samples equals the batch size is called batch training. Batch learning is stable because the influence of individual data on learning is reduced, but it has the disadvantage that it is easy to get stuck in a local optimum. Also, batch training is not possible if one epoch is too large for the computer to handle all the data at once.
If the batch size is 500, the weights and biases are updated twice per epoch. If the batch size is 100, the weights and biases are updated 10 times per epoch. Learning in which the weights and biases are updated more than once per epoch is called mini-batch training. Compared to batch learning, mini-batch training has the advantage that it is less likely to be trapped in a locally optimal solution.
How to determine batch size
Batch size affects learning time and performance, but setting an appropriate batch size is difficult. Generally, a batch size of 10 to 100 is often set.
How to determine the number of epochs
The gradient descent method is used for training. Since gradient descent is an iterative process, it is not sufficient to update the weights in one epoch; one epoch will result in the "underfit" shown below.

As the number of epochs increases, the number of times the weights are changed by the neural network increases and the curve goes from "Undefrit" to "Optimal" to an "Overfit" curve. Therefore, it is necessary to set the optimal number of epochs to reach the "Optimal" state.
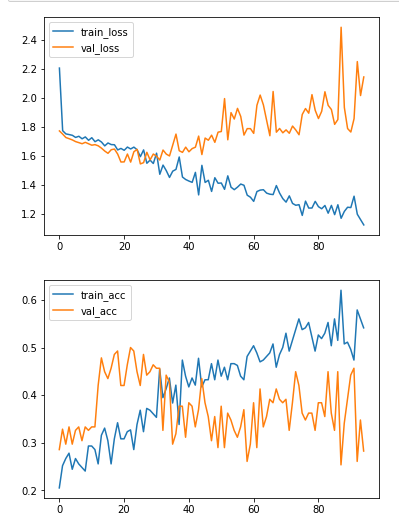
For example, in the figure below, the accuracy of the training data improves after 25 epochs, while the accuracy of the validation data does not improve. Therefore, the optimal number of epochs for this model is around 25 epochs, and after 25 epochs, overfitting to the Training data has started.
References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS