

Pengantar
Tokyo Institute of Technology telah menciptakan dan memelihara koleksi latihan NLP yang disebut "NLP 100 Exercise".
Dalam artikel ini, saya akan memberikan contoh jawaban untuk "Chapter 5: Dependency parsing".
Pengaturan lingkungan
Sebuah berkas ai.ja.zip berisi teks yang diekstrak dari sebuah artikel tentang "Kecerdasan Buatan" di Wikipedia bahasa Jepang. Lakukan analisis ketergantungan pada teks ini dengan menggunakan alat bantu seperti CaboCha atau KNP, dan simpan hasilnya dalam file ai.ja.txt.parsed. Baca file ini dan jalankan program untuk menjawab pertanyaan-pertanyaan berikut.
!apt install -y curl file git libmecab-dev make mecab mecab-ipadic-utf8 swig xz-utils
!pip install mecab-python3
import os
filename_crfpp = 'crfpp.tar.gz'
!wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" \
-O $filename_crfpp
!tar zxvf $filename_crfpp
%cd CRF++-0.58
!./configure
!make
!make install
%cd ..
os.environ['LD_LIBRARY_PATH'] += ':/usr/local/lib'
FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU"
FILE_NAME = "cabocha.tar.bz2"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=\
$(wget --quiet --save-cookies /tmp/cookies.txt \
--keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- \
| sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
!tar -xvf cabocha.tar.bz2
%cd cabocha-0.69
!./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
!make
!make check
!make install
%cd ..
%cd cabocha-0.69/python
!python setup.py build_ext
!python setup.py install
!ldconfig
%cd ../
%cd cabocha-0.69
!make
!make check
!make install
%cd ../
!wget https://nlp100.github.io/data/ai.ja.zip
!unzip ai.ja.zip
!cabocha -f1 -o ai.ja.txt.parsed ai.ja.txt
!wc -l ./ai.ja.txt.parsed
>> 11744 ./ai.ja.txt.parsed
!head -15 ./ai.ja.txt.parsed
>> * 0 -1D 1/1 0.000000
>> 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
>> 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
>> EOS
>> EOS
>> * 0 17D 1/1 0.388993
>> 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
>> 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
>> * 1 17D 2/3 0.613549
>> ( 記号,括弧開,*,*,*,*,(,(,(
>> じん 名詞,一般,*,*,*,*,じん,ジン,ジン
>> こうち 名詞,一般,*,*,*,*,こうち,コウチ,コーチ
>> のう 助詞,終助詞,*,*,*,*,のう,ノウ,ノー
>> 、 記号,読点,*,*,*,*,、,、,、
>> 、 記号,読点,*,*,*,*,、,、,、
40. Read the parse result (words)
Mengimplementasikan Morph, sebuah kelas yang merepresentasikan sebuah morfem. Kelas ini harus memiliki variabel anggota bentuk permukaan (
surface), bentuk dasar (base), bagian dari kata (pos), dan bagian dari kata subdivisi 1 (pos1). Selain itu, baca hasil penguraian ketergantungan (ai.en.txt.parsed), merepresentasikan setiap kalimat sebagai daftar objekMorph, dan menampilkan urutan morfologi dari kalimat pertama deskripsi.
class Morph:
def __init__(self, line):
surface, attr = line.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[-3]
self.pos = attr[0]
self.pos1 = attr[1]
sentences = []
morphs = []
with open("./ai.ja.txt.parsed") as f:
for line in f:
if line[0] == "*":
continue
elif line != "EOS\n":
morphs.append(Morph(line))
else:
sentences.append(morphs)
morphs = []
for i in sentences[0]:
print(vars(i))
{'surface': '人工', 'base': '人工', 'pos': '名詞', 'pos1': '一般'}
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'}
41. Read the parse result (dependency)
40 plus mengimplementasikan kelas
Chunk, yang merepresentasikan sebuah frasa. Kelas ini harus memiliki variabel anggota berupa daftar morfem (objekmorf), daftar nomor indeks frasa tujuan (dst), dan daftar nomor indeks frasa sumber (srcs). Selain itu, baca hasil penguraian ketergantungan dari teks masukan, merepresentasikan satu kalimat sebagai daftar objekChunk, dan mencetak string frasa penjelasan pembuka dan pelepasannya. Gunakan program yang telah Anda buat untuk soal-soal yang tersisa dalam bab ini.
class Chunk:
def __init__(self, morphs, dst, chunk_id):
self.morphs = morphs
self.dst = dst
self.srcs = []
self.chunk_id = chunk_id
class Sentence:
def __init__(self, chunks):
self.chunks = chunks
for i, chunk in enumerate(self.chunks):
if chunk.dst not in [None, -1]:
self.chunks[chunk.dst].srcs.append(i)
class Morph:
def __init__(self, line):
surface, attr = line.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[-3]
self.pos = attr[0]
self.pos1 = attr[1]
sentences = []
chunks = []
morphs = []
chunk_id = 0
with open("./ai.ja.txt.parsed") as f:
for line in f:
if line[0] == "*":
if morphs:
chunks.append(Chunk(morphs, dst, chunk_id))
chunk_id += 1
morphs = []
dst = int(line.split()[2].replace("D", ""))
elif line != "EOS\n":
morphs.append(Morph(line))
else:
chunks.append(Chunk(morphs, dst, chunk_id))
sentences.append(Sentence(chunks))
morphs = []
chunks = []
dst = None
chunk_id = 0
for chunk in sentences[2].chunks:
print(f'chunk str: {"".join([morph.surface for morph in chunk.morphs])}\ndst: {chunk.dst}\nsrcs: {chunk.srcs}\n')
chunk str: 人工知能
dst: 17
srcs: []
chunk str: (じんこうちのう、、
dst: 17
srcs: []
chunk str: AI
dst: 3
srcs: []
chunk str: 〈エーアイ〉)とは、
dst: 17
srcs: [2]
.
.
.
42. Show root words
Ekstrak semua teks klausa sumber dan tujuan dalam format tab-delimited. Namun, jangan keluarkan tanda baca.
sentence = sentences[2]
for chunk in sentence.chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentence.chunks[int(chunk.dst)].morphs if morph.pos != "記号"])
print(surf_org, surf_dst, sep='\t')
人工知能 語
じんこうちのう 語
AI エーアイとは
エーアイとは 語
計算 という
という 道具を
概念と 道具を
コンピュータ という
という 道具を
道具を 用いて
.
.
.
43. Show verb governors and noun dependents
Ketika klausa yang berisi kata benda terkait dengan klausa yang berisi kata kerja, ekstrak mereka dalam format tab-delimited. Namun, jangan keluarkan tanda baca.
sentence = sentences[2]
for chunk in sentence.chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"])
pos_noun = [morph.surface for morph in chunk.morphs if morph.pos == "名詞"]
pos_verb = [morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos == "動詞"]
if pos_noun and pos_verb:
print(surf_org, surf_dst, sep='\t')
道具を 用いて
知能を 研究する
一分野を 指す
知的行動を 代わって
人間に 代わって
コンピューターに 行わせる
研究分野とも される
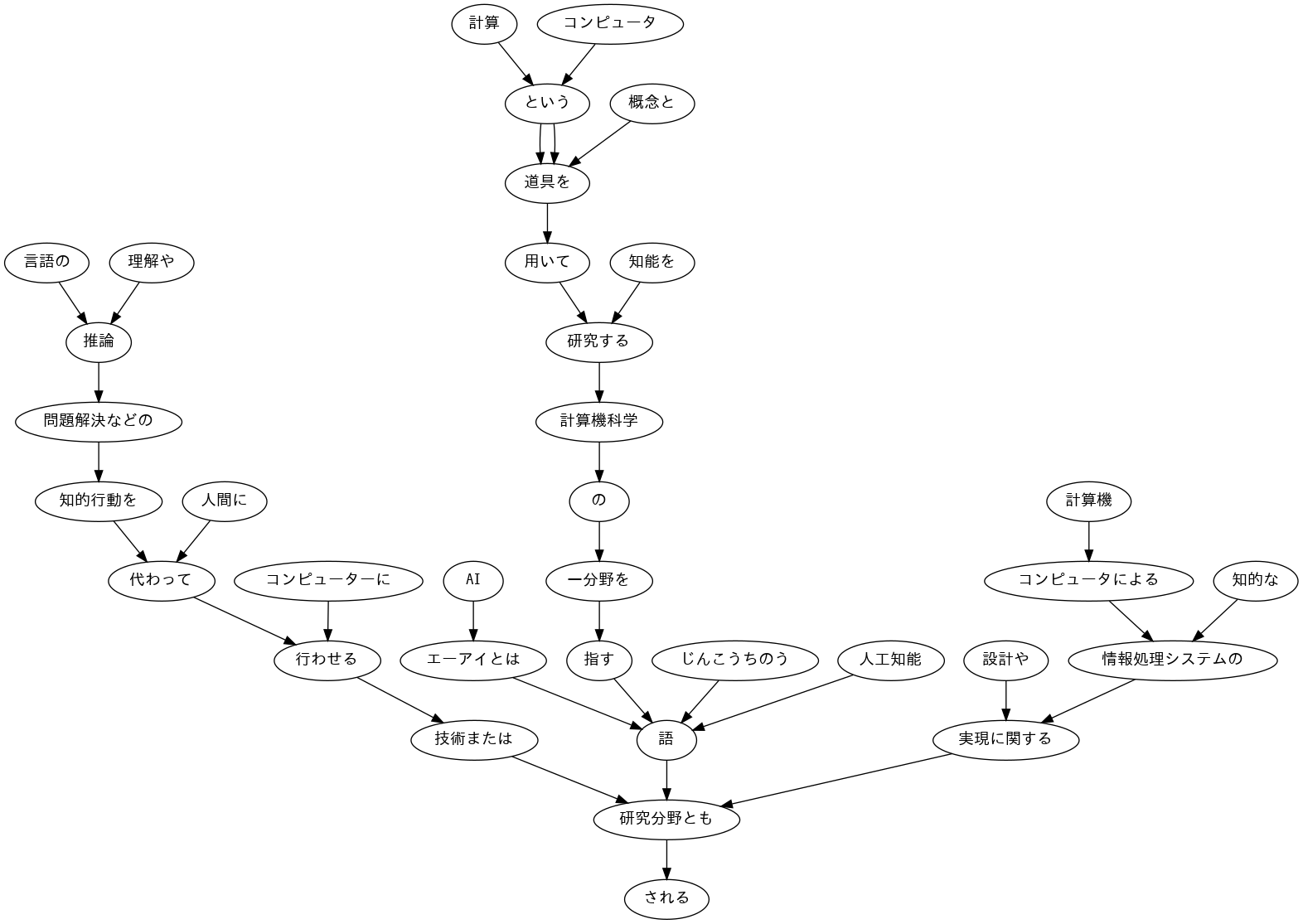
44. Visualize dependency trees
Memvisualisasikan pohon ketergantungan dari kalimat yang diberikan sebagai sebuah graf berarah. Anda dapat menggunakan Graphviz atau perangkat lunak serupa untuk visualisasi.
!apt install fonts-ipafont-gothic
!pip install pydot
import pydot_ng as pydot
from IPython.display import Image,display_png
edges = []
for chunk in sentences[2].chunks:
if int(chunk.dst) == -1:
continue
else:
surf_org = "".join([morph.surface for morph in chunk.morphs if morph.pos != "記号"])
surf_dst = "".join([morph.surface for morph in sentences[2].chunks[int(chunk.dst)].morphs if morph.pos != "記号"]) #文節のリストに係り先番号をindexに指定。その文節の形態素リストを取得
edges.append((surf_org, surf_dst))
img = pydot.Dot()
img.set_node_defaults(fontname="IPAGothic")
for s, t in edges:
img.add_edge(pydot.Edge(s, t))
img.write_png("./result44.png")
display_png(Image('./result44.png'))
45. Triple with subject, verb, and direct object
Kita ingin menyelidiki kemungkinan kasus predikat bahasa Jepang, dengan mempertimbangkan kalimat yang digunakan dalam penelitian ini sebagai korpus. Anggaplah kata kerja sebagai predikat dan kasus sebagai partikel klausa yang terkait dengan kata kerja, dan keluarkan predikat dan kasus dalam format tab-delimited. Namun, keluarannya harus memenuhi spesifikasi berikut.
Dalam klausa yang berisi kata kerja, gunakan bentuk dasar kata kerja paling kiri sebagai predikat.
Kasus partikel dari predikat adalah kasus dari predikat
Jika ada lebih dari satu partikel (klausa) yang terkait dengan predikat, daftarkan semua partikel dalam urutan leksikografi, dipisahkan oleh spasi
Simpanlah hasil dari program ini ke dalam sebuah file dan periksa dengan menggunakan perintah-perintah UNIX.
Predikat dan pola huruf besar-kecil yang sering muncul dalam korpus
- Pola huruf besar kecilnya kata kerja "行う", "なる", dan "与える" (sesuai dengan urutan frekuensi kemunculannya dalam korpus)
with open("./result45.txt", "w") as f:
for i in range(len(sentences)):
for chunk in sentences[i].chunks:
for morph in chunk.morphs:
if morph.pos == "動詞":
particles = []
for src in chunk.srcs:
particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"]
if len(particles) > 0:
particles = sorted(list(set(particles)))
print(f"{morph.base}\t{' '.join(particles)}", file=f)
!cat ./result45.txt | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "行う" | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "なる" | sort | uniq -c | sort -nr | head -n 5
!cat ./result45.txt | grep "与える" | sort | uniq -c | sort -nr | head -n 5
>> 49 する を
>> 19 する が
>> 15 する に
>> 15 する と
>> 12 する は を
>> 8 行う を
>> 1 行う まで を
>> 1 行う は を をめぐって
>> 1 行う は を
>> 1 行う に を
>> 4 なる に は
>> 3 なる が と
>> 2 なる に
>> 2 なる と
>> 1 異なる も
>> 1 与える に は を
>> 1 与える が に
>> 1 与える が など に
46. Expanding subjects and objects
Modifikasi program di 45 untuk menampilkan pola predikat dan kasus yang diikuti oleh istilah (klausa itu sendiri yang terlibat dalam predikat) dalam format tab-delimited.
- Term harus berupa urutan kata dari klausa yang terlibat dalam predikat (tidak perlu menghapus partikel di belakangnya).
- Jika ada beberapa klausa yang terkait dengan predikat, mereka harus dipisahkan dengan spasi dalam urutan yang sama dan dengan kriteria yang sama dengan partikel.
with open("./result46.txt", "w") as f:
for i in range(len(sentences)):
for chunk in sentences[i].chunks:
for morph in chunk.morphs:
if morph.pos == "動詞":
particles = []
items = []
for src in chunk.srcs:
particles += [morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos == "助詞"]
items += ["".join([morph.surface for morph in sentences[i].chunks[src].morphs if morph.pos != "記号"])]
if len(particles) > 0:
if len(items) > 0:
particles_form = " ".join(sorted(set(particles)))
items_form = " ".join(sorted(set(items)))
print(f"{morph.base}\t{particles_form}\t{items_form}", file=f)
!head -n 10 result46.txt
>> 用いる を 道具を
>> する て を 用いて 知能を
>> 指す を 一分野を
>> 代わる に を 人間に 知的行動を
>> 行う て に コンピューターに 代わって
>> せる て に コンピューターに 代わって
>> する と も 研究分野とも
>> れる と も 研究分野とも
>> 述べる で に の は 佐藤理史は 次のように 解説で
>> いる で に の は 佐藤理史は 次のように 解説で
47. Triple from the passive sentence
Kita hanya ingin fokus pada kasus di mana kata kerja wo mengandung konjungsi subjungtif. 46 Modifikasi program untuk memenuhi spesifikasi berikut ini.
- Kita hanya ingin fokus pada kasus di mana klausa yang terdiri dari "サ変接続名詞+を(助詞)" berhubungan dengan kata kerja.
- Predikat harus berupa "サ変接続名詞+を+ bentuk dasar 動詞", dan jika ada lebih dari satu kata kerja dalam klausa, kata kerja yang paling kiri harus digunakan.
- Jika ada beberapa partikel (klausa) yang berhubungan dengan predikat, semua partikel dipisahkan dengan spasi dan disusun sesuai urutan leksikal.
- Jika ada lebih dari satu klausa untuk predikat, pisahkan semua istilah dengan spasi (sejajar dengan urutan partikel)
with open('./result47.txt', 'w') as f:
for sentence in sentences:
for chunk in sentence.chunks:
for morph in chunk.morphs:
if morph.pos == '動詞':
for i, src in enumerate(chunk.srcs):
if len(sentence.chunks[src].morphs) == 2 and sentence.chunks[src].morphs[0].pos1 == 'サ変接続' and sentence.chunks[src].morphs[1].surface == 'を':
predicate = ''.join([sentence.chunks[src].morphs[0].surface, sentence.chunks[src].morphs[1].surface, morph.base])
particles = []
items = []
for src_r in chunk.srcs[:i] + chunk.srcs[i + 1:]:
case = [morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos == '助詞']
if len(case) > 0:
particles = particles + case
items.append(''.join(morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos != '記号'))
if len(particles) > 0:
particles = sorted(list(set(particles)))
line = '{}\t{}\t{}'.format(predicate, ' '.join(particles), ' '.join(items))
print(line, file=f)
break
!head -n 10 result47.txt
>> 注目を集める が を ある その後 サポートベクターマシンが
>> 経験を行う に を 元に 学習を
>> 学習を行う に を 元に 経験を
>> 進化を見せる て において は を 加えて 敵対的生成ネットワークは 活躍している 特に 生成技術において
>> 進化をいる て において は を 加えて 敵対的生成ネットワークは 活躍している 特に 生成技術において
>> 開発を行う は を エイダ・ラブレスは 製作した
>> 命令をする で を 機構で 直接
>> 運転をする に を 元に 増やし
>> 特許をする が に まで を 2018年までに 日本が
>> 特許をいる が に まで を 2018年までに 日本が
48. Extract paths from the root to nouns
Untuk setiap klausa yang berisi semua kata benda dalam sebuah kalimat, ekstrak jalur dari klausa tersebut ke akar pohon parse. Namun, jalur pada pohon parsing harus memenuhi spesifikasi berikut ini.
- Setiap klausa diwakili oleh urutan morfem (dalam bentuk permukaan).
- Setiap frasa pada jalur, dari awal hingga akhir jalur, dihubungkan dengan "->".
sentence = sentences[2]
for chunk in sentence.chunks:
if "名詞" in [morph.pos for morph in chunk.morphs]:
path = ["".join(morph.surface for morph in chunk.morphs if morph.pos != "記号")]
while chunk.dst != -1:
path.append(''.join(morph.surface for morph in sentence.chunks[chunk.dst].morphs if morph.pos != "記号"))
chunk = sentence.chunks[chunk.dst]
print(" -> ".join(path))
人工知能 -> 語 -> 研究分野とも -> される
じんこうちのう -> 語 -> 研究分野とも -> される
AI -> エーアイとは -> 語 -> 研究分野とも -> される
エーアイとは -> 語 -> 研究分野とも -> される
計算 -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
概念と -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
コンピュータ -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
知能を -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される
.
.
.
49. Extract the shortest path between two nouns
Ekstrak jalur disjungsi terpendek yang menghubungkan semua pasangan frasa kata benda dalam kalimat. Namun, jika nomor klausa dari pasangan frasa kata benda adalah
dan i ( j ), jalur disjungsi harus memenuhi spesifikasi berikut. i<j
Seperti pada soal 48, jalur adalah representasi dari setiap frasa (urutan morfem dalam bentuk permukaan) dari klausa awal ke klausa akhir, yang digabungkan dengan "->"
Frasa kata benda pada klausa
dan i masing-masing digantikan oleh X dan Y j Frasa kata benda dalam klausa
dan i masing-masing digantikan oleh X dan Y > - Bentuk jalur ketergantungan dapat berupa salah satu dari dua cara berikut. j Jika klausa
berada di jalur dari klausa j ke akar pohon parsing: tampilkan jalur dari klausa i ke klausa i . j Jika selain cara di atas, ada klausa
yang sama pada jalur dari klausa k dan klausa i ke akar pohon parsing: jalur dari klausa j ke klausa i , jalur dari klausa k ke klausa j , dan isi klausa k ditampilkan dengan " | ". dirangkai dengan " | ". k
from itertools import combinations
import re
sentence = sentences[2]
nouns = []
for i, chunk in enumerate(sentence.chunks):
if [morph for morph in chunk.morphs if morph.pos == "名詞"]:
nouns.append(i)
for i, j in combinations(nouns, 2):
path_i = []
path_j = []
while i != j:
if i < j:
path_i.append(i)
i = sentence.chunks[i].dst
else:
path_j.append(j)
j = sentence.chunks[j].dst
if len(path_j) == 0:
X = "X" + "".join([morph.surface for morph in sentence.chunks[path_i[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
Y = "Y" + "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "名詞" and morph.pos != "記号"])
chunk_X = re.sub("X+", "X", X)
chunk_Y = re.sub("Y+", "Y", Y)
path_XtoY = [chunk_X] + ["".join(morph.surface for n in path_i[1:] for morph in sentence.chunks[n].morphs)] + [chunk_Y]
print(" -> ".join(path_XtoY))
else:
X = "X" + "".join([morph.surface for morph in sentence.chunks[path_i[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
Y = "Y" + "".join([morph.surface for morph in sentence.chunks[path_j[0]].morphs if morph.pos != "名詞" and morph.pos != "記号"])
chunk_X = re.sub("X+", "X", X)
chunk_Y = re.sub("Y+", "Y", Y)
chunk_k = "".join([morph.surface for morph in sentence.chunks[i].morphs if morph.pos != "記号"])
path_X = [chunk_X] + ["".join(morph.surface for n in path_i[1:] for morph in sentence.chunks[n].morphs if morph.pos != "記号")]
path_Y = [chunk_Y] + ["".join(morph.surface for n in path_j[1: ]for morph in sentence.chunks[n].morphs if morph.pos != "記号")]
print(" | ".join([" -> ".join(path_X), " -> ".join(path_Y), chunk_k]))
X -> | Yのう -> | 語
X -> | Y -> エーアイとは | 語
X -> | Yとは -> | 語
X -> | Y -> という道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Yと -> 道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Y -> という道具を用いて研究する計算機科学の一分野を指す | 語
X -> | Yを -> 用いて研究する計算機科学の一分野を指す | 語
X -> | Yを -> 研究する計算機科学の一分野を指す | 語
X -> | Yする -> 計算機科学の一分野を指す | 語
X -> | Y -> の一分野を指す | 語
X -> | Yを -> 指す | 語
.
.
.
Referensi

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS