

Apa itu MLflow
MLflow adalah alat OSS untuk mengelola siklus hidup ML. Mlflow menawarkan fungsi-fungsi berikut:
- MLFlow Tracking: manajemen eksperimen
- MLFlow Projects: manajemen lingkungan runtime
- MLFlow Models: menyebarkan dan menyalurkan model Anda
- MLFlow Model Registry: pembuatan versi model
Artikel ini membahas MLflow Tracking, sebuah fitur manajemen eksperimen.
Pelacakan MLflow
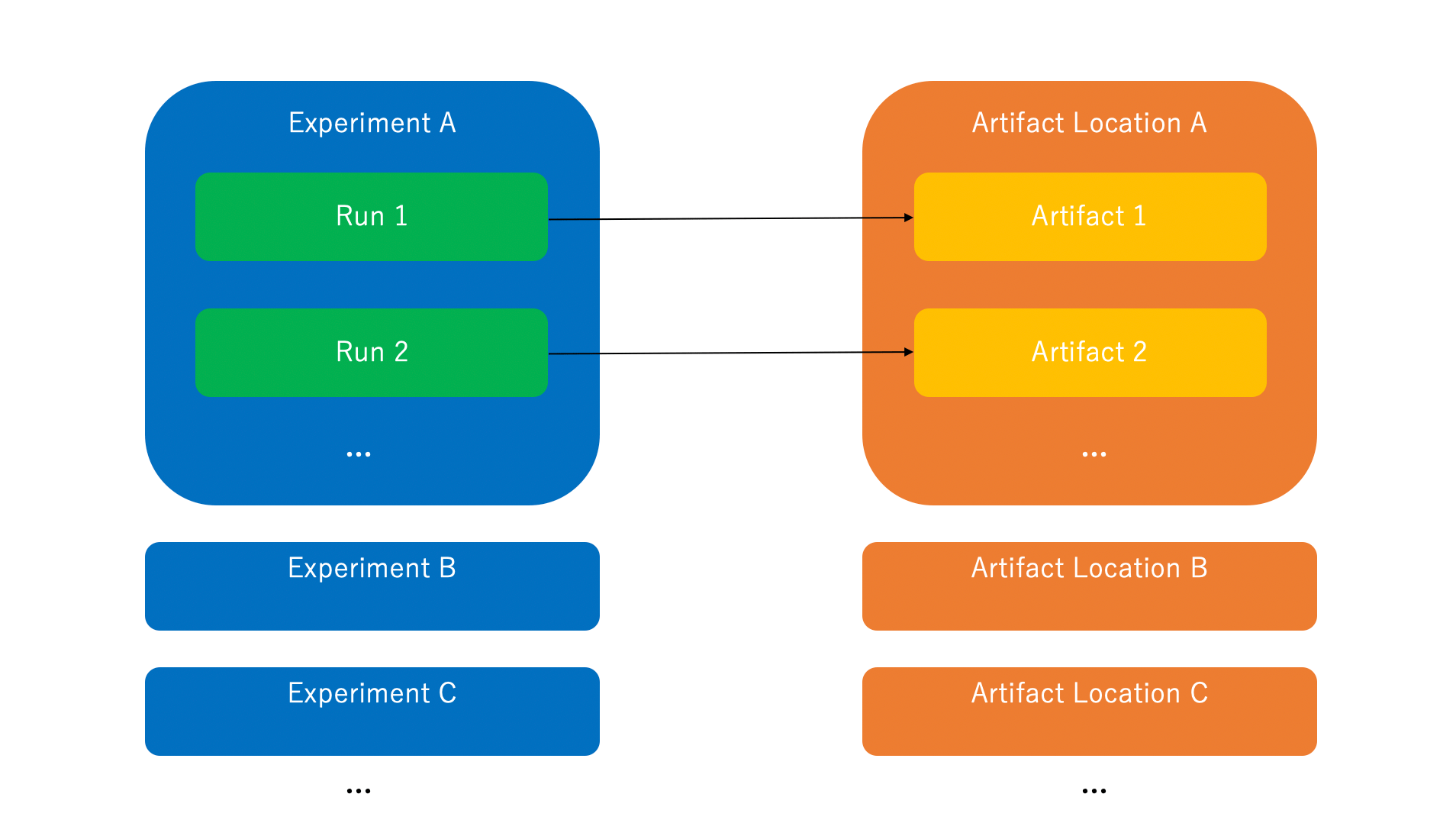
Manajemen eksperimen MLflow terdiri dari tiga komponen berikut.
- Run
Sebuah percobaan tunggal (misalnya, percobaan, studi) - Experiment
Sebuah grup yang mengikat Runs bersama-sama. - Artifact
Penyimpanan output atau produk antara dari sebuah Run
Mari kita benar-benar menggunakan Pelacakan MLflow. Pertama, instal pustaka.
$ pip install mlflow
Kemudian simpan kode berikut di main.py dan jalankan.
import os
from random import random, randint
from mlflow import log_metric, log_param, log_artifact, log_artifacts
if __name__ == "__main__":
# Log a parameter (key-value pair)
log_param("param1", randint(0, 100))
# Log a metric; metrics can be updated throughout the run
log_metric("foo", random())
log_metric("foo", random() + 1)
log_metric("foo", random() + 2)
# Log an artifact (output file)
if not os.path.exists("outputs"):
os.makedirs("outputs")
with open("outputs/test.txt", "w") as f:
f.write("Hello world!")
log_artifacts("outputs") # Record folder
$ python main.py
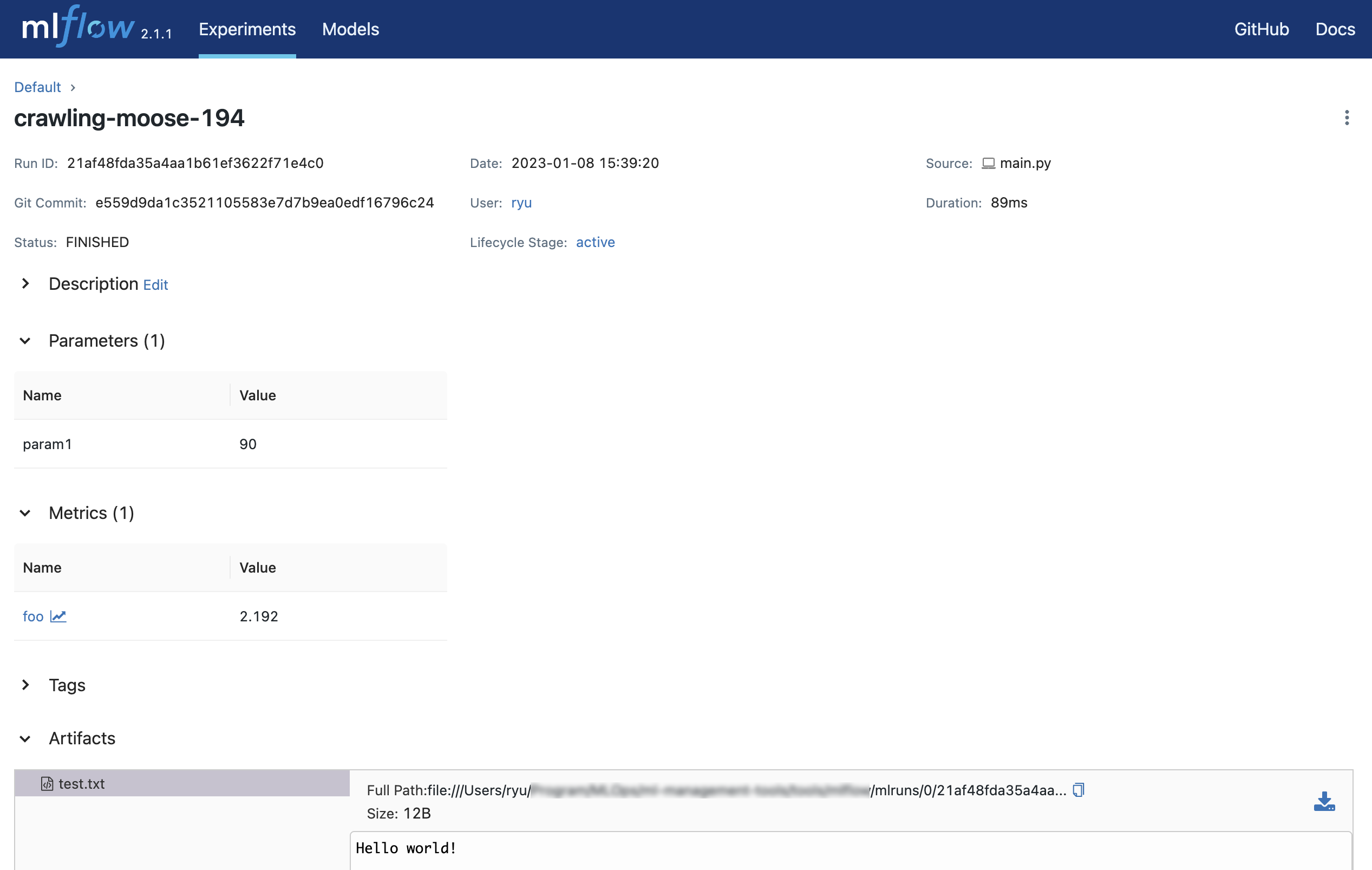
Sebuah folder mlruns dan sebuah folder outputs akan dibuat.
.
├── __init__.py
├── main.py
├── mlruns
│ └── 0
│ ├── 21af48fda35a4aa1b61ef3622f71e4c0
│ │ ├── artifacts
│ │ │ └── test.txt
│ │ ├── meta.yaml
│ │ ├── metrics
│ │ │ └── foo
│ │ ├── params
│ │ │ └── param1
│ │ └── tags
│ │ ├── mlflow.runName
│ │ ├── mlflow.source.git.commit
│ │ ├── mlflow.source.name
│ │ ├── mlflow.source.type
│ │ └── mlflow.user
│ └── meta.yaml
└── outputs
└── test.txt
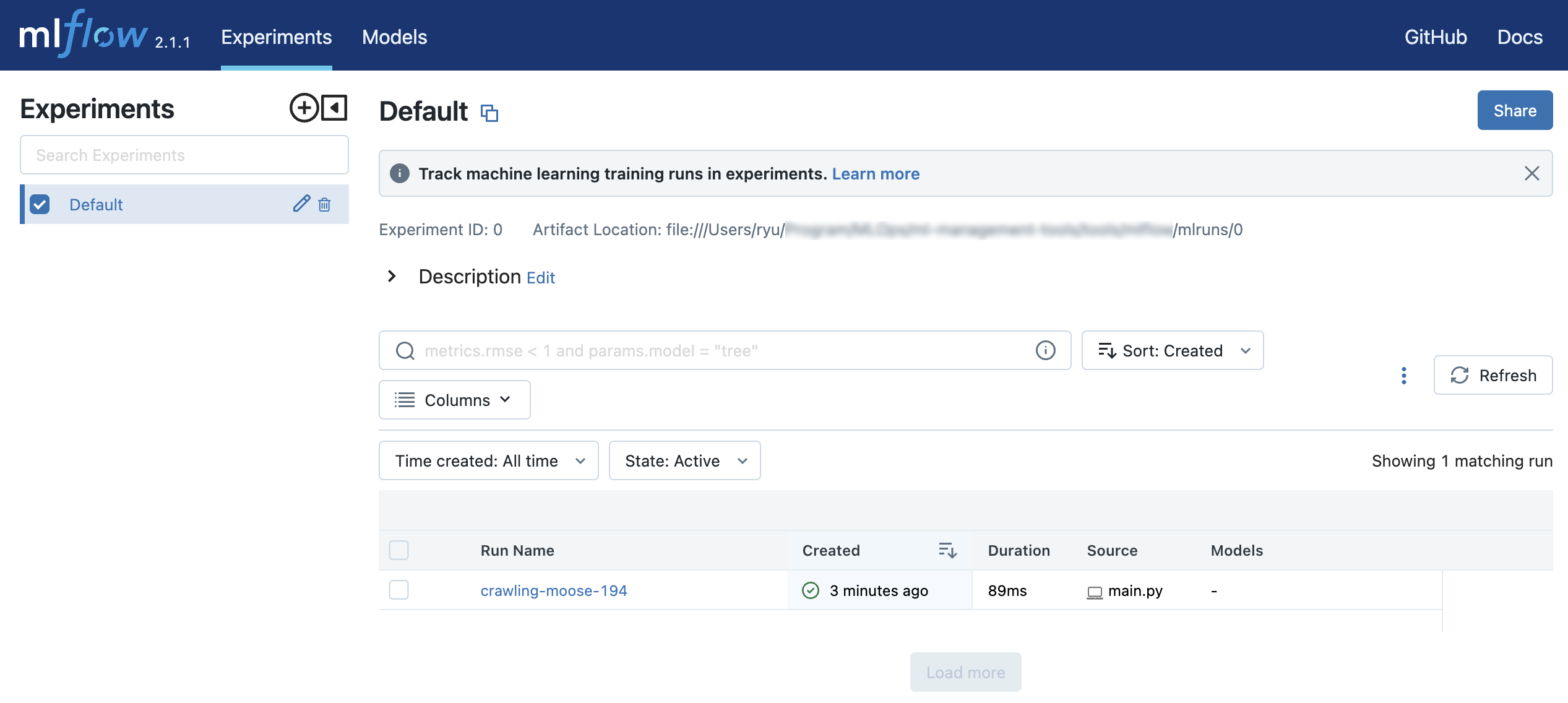
0 adalah ID dari Experiment dan 21af48fda35a4aa1b61ef3622f71e4c0 adalah ID dari Run.
Jalankan perintah mlflow ui.
$ mlflow ui
[2023-01-08 15:41:46 +0900] [54928] [INFO] Starting gunicorn 20.1.0
[2023-01-08 15:41:46 +0900] [54928] [INFO] Listening at: http://127.0.0.1:5000 (54928)
[2023-01-08 15:41:46 +0900] [54928] [INFO] Using worker: sync
[2023-01-08 15:41:46 +0900] [54930] [INFO] Booting worker with pid: 54930
[2023-01-08 15:41:47 +0900] [54931] [INFO] Booting worker with pid: 54931
[2023-01-08 15:41:47 +0900] [54932] [INFO] Booting worker with pid: 54932
[2023-01-08 15:41:47 +0900] [54933] [INFO] Booting worker with pid: 54933
[2023-01-08 15:41:55 +0900] [54928] [INFO] Handling signal: winch
[2023-01-08 15:41:58 +0900] [54928] [INFO] Handling signal: winch
Anda bisa mengakses http://127.0.0.1:5000 untuk melihat hasil eksperimen di browser Anda.
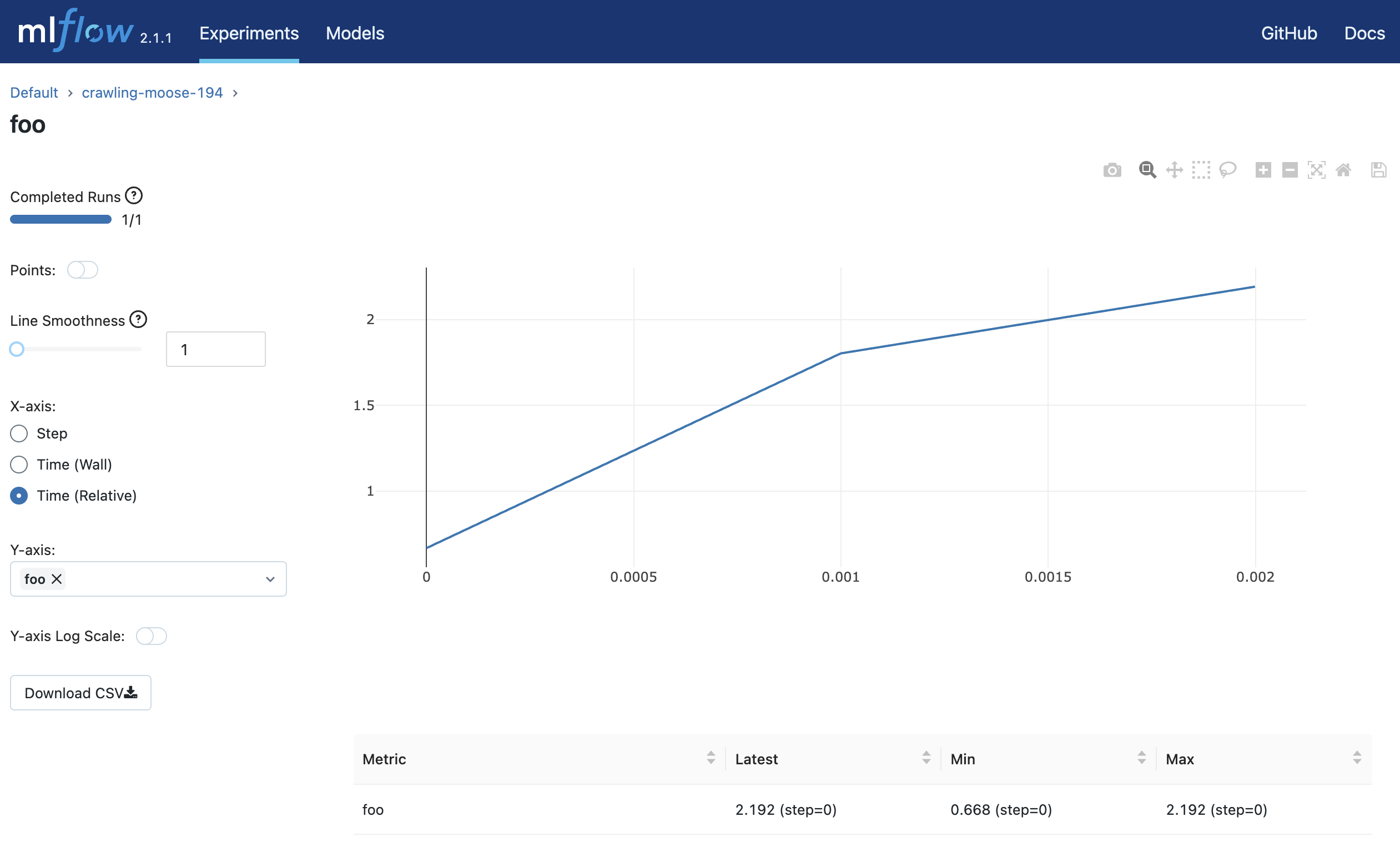
Eksperimen yang akan dikontrol
Dalam MLflow, empat nilai utama berikut ini dikendalikan.
- Parameters
Parameter untuk eksekusi eksperimen - Tags
Tag untuk eksekusi eksperimen - Metrics
Metrik dari eksperimen - Artifacts
File yang dihasilkan oleh eksperimen
Fungsi pencatatan
MLflow dapat mencatat data ke Run menggunakan Python, R, Java, atau REST API.
Server MLflow Tracking
Anda dapat menggunakan perintah mlflow server untuk mengatur server Tracking MLflow.
$ mlflow server \
--backend-store-uri /mnt/persistent-disk \
--default-artifact-root s3://my-mlflow-bucket/ \
--host 0.0.0.0
Server Tracking MLflow memiliki dua komponen terkait penyimpanan
- Backend Stores (
--backend-store-uri) - Artifact Stores (
--default-artifact-root)
Backend Stores
Backend Store adalah tempat untuk menyimpan metadata eksperimen dan eksekusi, parameter eksekusi, metrik, dan tag.
Backend Store berikut dapat ditentukan dalam --backend-store-uri.
- Sistem berkas lokal
. /path_to_storefile:/path_to_store
- DB yang kompatibel dengan SQLAlchemy
<dialect>+<driver>://<username>:<password>@<host>:<port>/<database>
Nilai default dari --backend-store-uri adalah . /mlruns.
Artifact Stores
Artifact Stores adalah tempat penyimpanan Artifacts. Artifact Stores mendukung sistem file berikut ini
- Amazon S3
- Google Cloud Storage
- Azure Blob Storage
- FTP server
- SFTP Server
- NFS
- HDFS
--default-artifact-root menentukan lokasi artefak default.
Pencatatan otomatis
MLflow menggunakan fitur yang disebut pencatatan otomatis untuk secara otomatis mencatat metrik, parameter, dan model tanpa secara eksplisit menulis kode pencatatan. Pustaka berikut mendukung pencatatan otomatis
- Scikit-learn
- Keras
- Gluon
- XGBoost
- LightGBM
- Statsmodels
- Spark
- Fastai
- Pytorch
Ada dua cara untuk menggunakan pencatatan otomatis:
- Panggil fungsi
mlflow.autolog()sebelum kode pembelajaran - Panggil fungsi khusus library (misalnya
mlflow.sklearn.autolog())
Kode berikut ini adalah contoh dari autologging sklearn.
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
mlflow.autolog()
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
# Create and train models.
rf = RandomForestRegressor(n_estimators = 100, max_depth = 6, max_features = 3)
rf.fit(X_train, y_train)
# Use the model to make predictions on the test dataset.
predictions = rf.predict(X_test)
autolog_run = mlflow.last_active_run()
Eksperimen LightGBM
Mari kita bereksperimen dengan klasifikasi LightGBM dari dataset iris mata.
Pertama, siapkan server Pelacakan MLflow.
$ mlflow server \
--backend-store-uri ./mlruns \
--default-artifact-root gs://GCS_BUCKET/mlruns \
--host 0.0.0.0
Kemudian jalankan kode berikut dua kali.
from datetime import datetime
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
import mlflow
params = dict(
test_size=0.2,
random_state=42,
)
iris = datasets.load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, **params)
lgb_params = dict(
learning_rate=0.05,
n_estimators=500,
)
model = lgb.LGBMClassifier(**lgb_params)
def mlflow_callback():
def callback(env):
for name, loss_name, loss_value, _ in env.evaluation_result_list:
mlflow.log_metric(key=loss_name, value=loss_value, step=env.iteration)
return callback
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_experiment("EXP-1")
with mlflow.start_run(run_name=str(datetime.now())):
mlflow.log_params({**params, **lgb_params})
model.fit(
X_train,
y_train,
eval_set=(X_test, y_test),
eval_metric=["softmax"],
callbacks=[
lgb.early_stopping(10),
mlflow_callback(),
])
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
mlflow.log_artifact("output.txt")
$ lightgbm_experiment.py
$ lightgbm_experiment.py
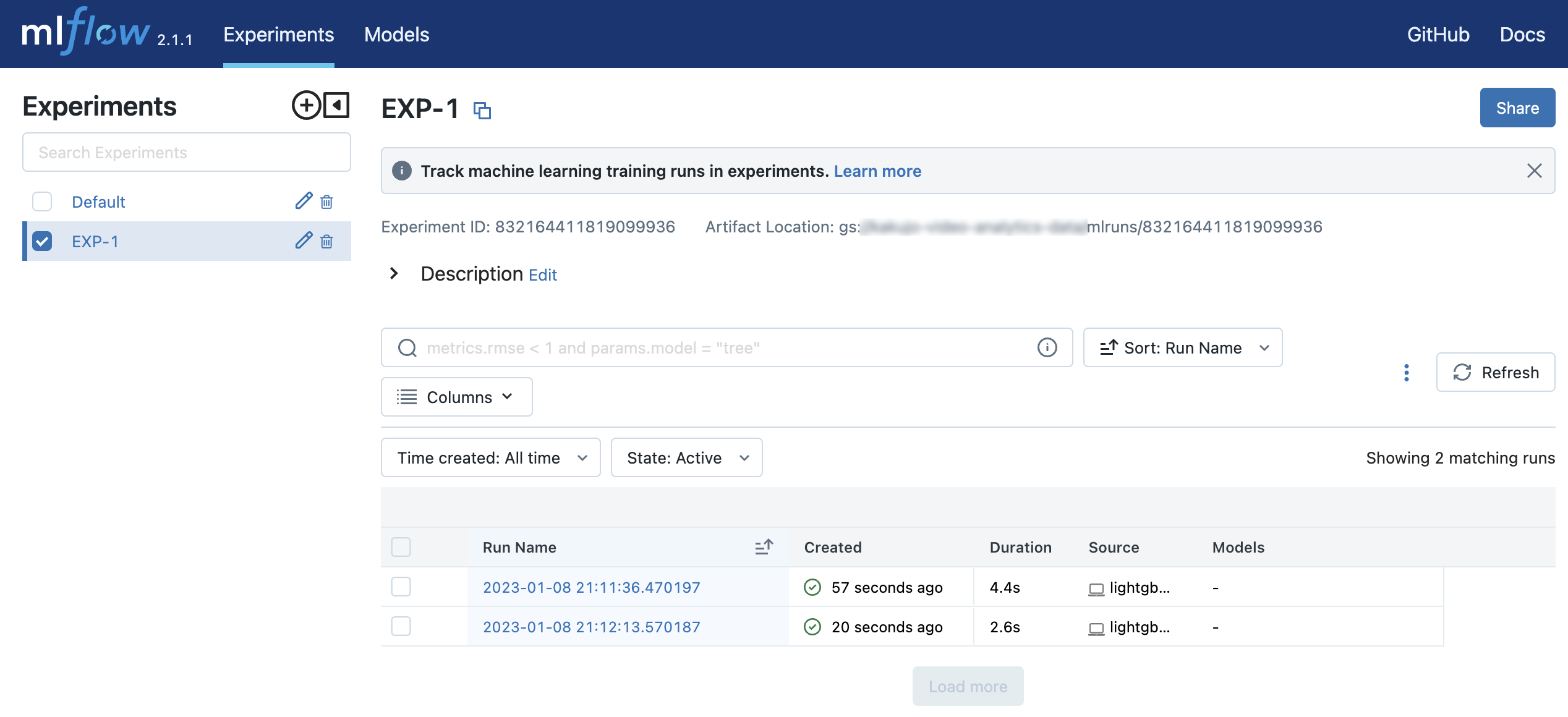
Ketika Anda membuka http://127.0.0.1:5000, Anda akan melihat dua Run dalam Eksperimen yang disebut EXP-1.
Referencsi

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS