
Pola penyajian untuk sistem ML
Ada berbagai cara untuk menyajikan inferensi dalam sistem pembelajaran mesin. Dalam artikel ini, saya memperkenalkan pola penyajian berikut untuk sistem ML, yang dijelaskan dalam GitHub Mercari.
- Pola web-tunggal
- Pola sinkron
- Pola asinkron
- Pola batch
- Pola prep-pred
- Pola layanan mikro serial
- Pola layanan mikro paralel
- Pola cache inferensi
- Pola cache data
Pola web-tunggal
Pola web-tunggal menggabungkan model dengan server web. Dengan memasang antarmuka REST (atau GRPC), preprocessing, dan model yang dilatih pada server yang sama, server inferensi sederhana dapat dibuat.
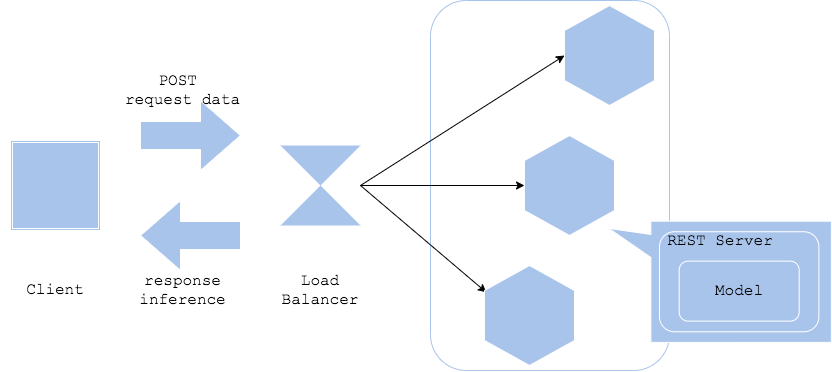
- Pro
- Web, preprocessing, dan inferensi dapat diimplementasikan dalam bahasa pemrograman yang sama
- Struktur sederhana dan pengoperasian yang mudah
- Kontra
- Komponen (web, preprocessing, inferensi) dilampirkan dalam gambar kontainer yang sama, sehingga komponen tidak dapat diperbarui secara individual
- Kasus penggunaan
- Konfigurasi sederhana untuk pelepasan cepat server inferensi
- Ketika hanya satu model yang mengembalikan inferensi secara sinkron
Pola sinkron
Dalam pola sinkron, server web dan server inferensi dipisahkan, dan inferensi ditangani secara sinkron. Klien menunggu sampai menerima respons terhadap permintaan inferensi.
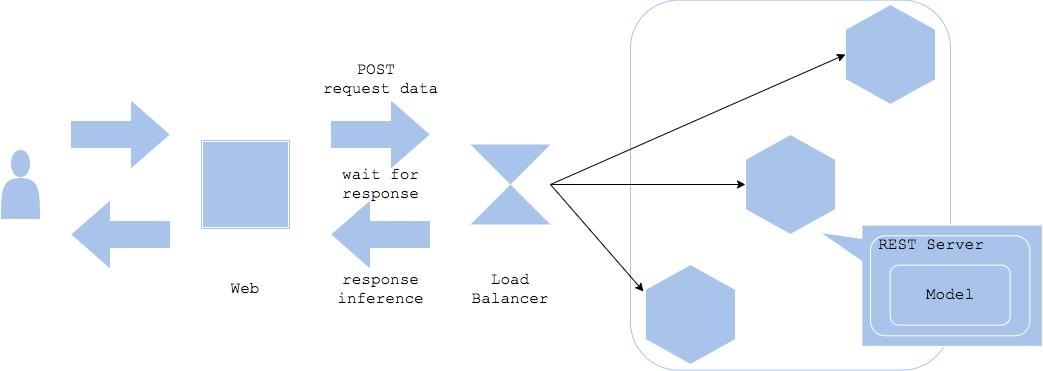
- Pro
- Struktur sederhana dan mudah dioperasikan
- Klien tidak berpindah ke proses berikutnya sampai inferensi selesai, sehingga mudah untuk memikirkan alur kerja
- Kontra
- Inferensi cenderung menjadi hambatan kinerja
- Inferensi menunggu, sehingga perlu mempertimbangkan cara-cara untuk menghindari penurunan pengalaman pengguna selama waktu ini
- Kasus penggunaan
- Ketika alur kerja aplikasi sedemikian rupa sehingga tidak dapat melanjutkan ke langkah berikutnya sampai hasil inferensi diperoleh
- Ketika alur kerja bergantung pada hasil inferensi
Pola Asinkron
Dalam pola Asynchronous, antrian atau cache ditempatkan di antara permintaan dan inferensi, dan permintaan inferensi dan hasil inferensi diperoleh secara asinkron. Dalam pola ini, dengan memisahkan permintaan dan inferensi, tidak perlu menunggu waktu inferensi dalam alur kerja klien.
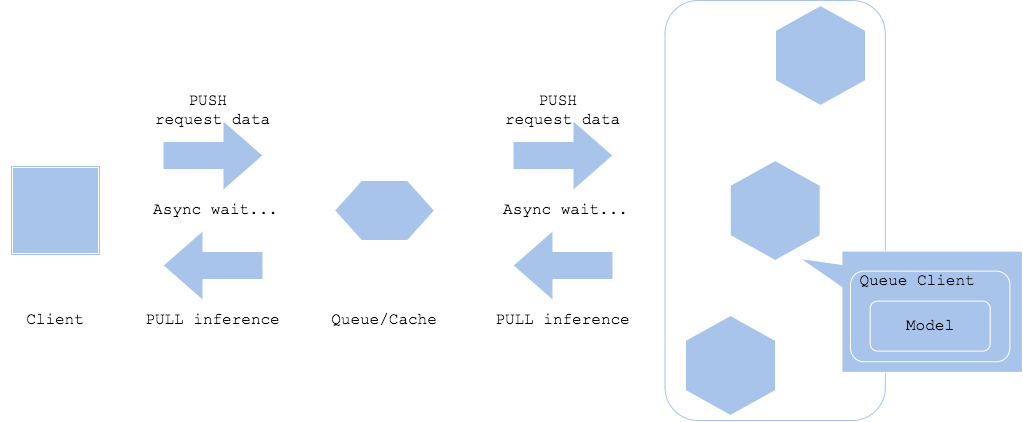
- Pros
- Dapat memisahkan inferensi dari klien
- Dampak klien lebih sedikit bahkan ketika inferensi menunggu untuk jangka waktu yang lama
- Kontra
- Membutuhkan antrian dan cache
- Tidak cocok untuk pemrosesan waktu nyata
- Kasus penggunaan
- Untuk alur kerja di mana perilaku pasca-pemrosesan langsung tidak bergantung pada hasil inferensi
- Klien dan tujuan output terpisah untuk hasil inferensi
Pola batch
Ketika inferensi tidak perlu dilakukan secara real-time, pekerjaan batch dapat dimulai untuk melakukan inferensi secara berkala. Dalam pola ini, data yang terakumulasi bisa diinferensi secara periodik, seperti pada malam hari, dan hasilnya bisa disimpan.
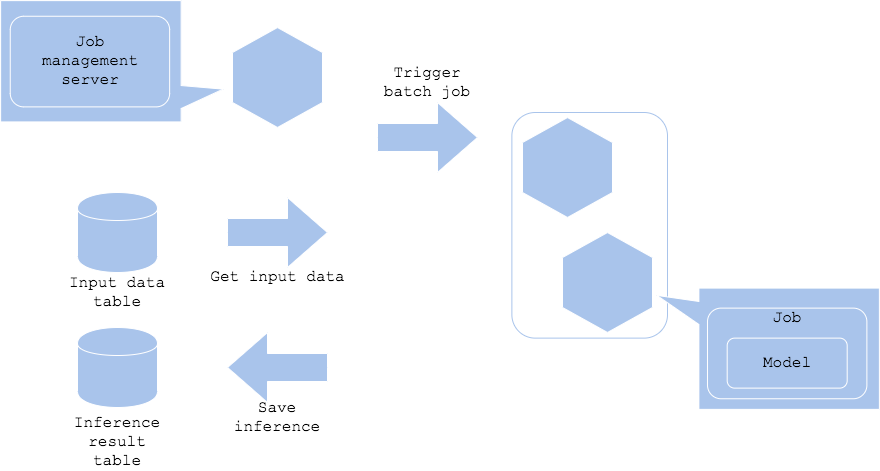
- Pro
- Manajemen resource server yang fleksibel
- Jika inferensi gagal karena suatu alasan, bisa dilakukan lagi.
- Kontra
- Server manajemen pekerjaan diperlukan.
- Kasus penggunaan
- Ketika inferensi waktu nyata atau kuasi-waktu tidak diperlukan
- Apabila Anda ingin melakukan inferensi ringkasan pada data historis
Anda ingin menyimpulkan data secara berkala, seperti pada malam hari, per jam, bulanan, dll.
Pola prep-pred
Preprocessing dan inferensi mungkin memerlukan resource dan library yang berbeda. Dalam kasus seperti itu, Anda dapat membagi server atau kontainer antara preprocessor dan inferencer untuk merampingkan pengembangan dan operasi. Meskipun membagi preprocessor dan inferencer memungkinkan pemanfaatan resource yang efisien, pengembangan individu, dan isolasi kesalahan, ini juga memerlukan penyetelan setiap resource, desain jaringan bersama, dan pembuatan versi. Pola ini sering digunakan ketika deep learning digunakan sebagai inferencer.
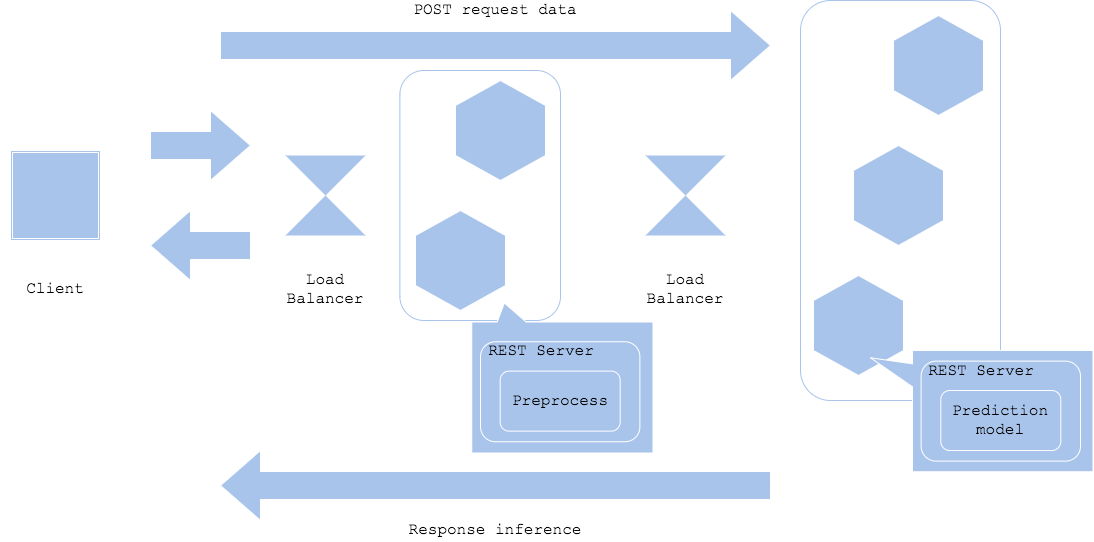
Simple prep-pred pattern
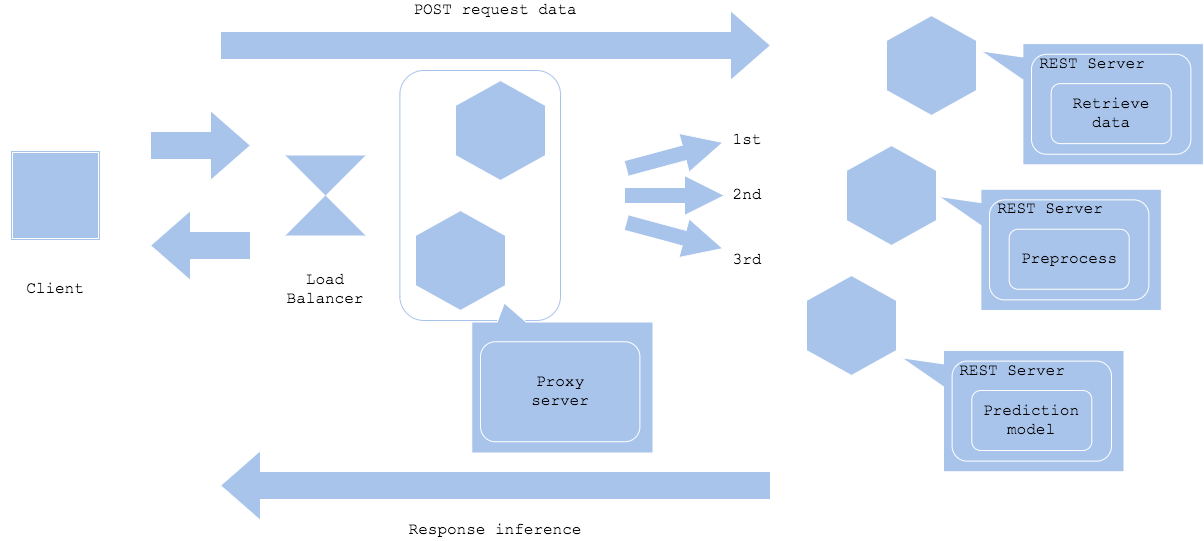
Microservice prep-pred pattern
- Pro
- Memungkinkan isolasi kesalahan
- Memungkinkan fleksibilitas dalam memilih pustaka dan menambah atau mengurangi resource
- Kontra
- Peningkatan kompleksitas server yang dikelola dan konfigurasi jaringan, mengakibatkan peningkatan beban operasional
- Jaringan antara server preprocessing dan server inferensi dapat menjadi hambatan
- Kasus penggunaan
- Pustaka, basis kode, dan beban resource berbeda antara preprocessing dan inferensi
- Ketika Anda ingin meningkatkan ketersediaan dengan memisahkan preprocessing dan inferensi
Pola layanan mikro serial
Jika Anda ingin menjalankan beberapa model inferensi secara berurutan, terapkan beberapa model pembelajaran mesin secara paralel di server terpisah. Kirim permintaan inferensi ke masing-masing secara bergantian, dan dapatkan hasil inferensi setelah menggabungkan inferensi terakhir.
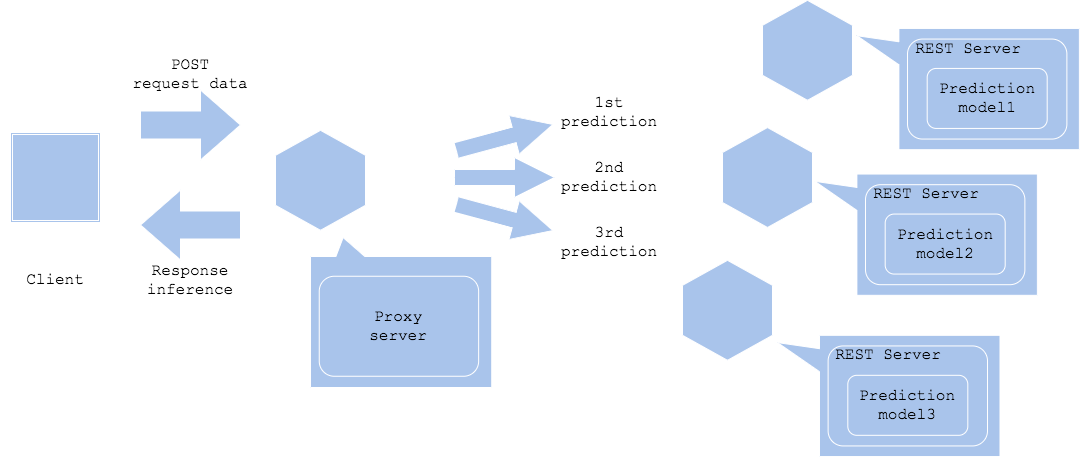
- Pro
- Setiap model inferensi dapat dieksekusi secara bergantian
- Dapat dikonfigurasi untuk memilih tujuan permintaan inferensi untuk model berikutnya tergantung pada hasil model inferensi sebelumnya
- Dengan membagi server dan basis kode untuk setiap inferensi, efisiensi resource dan isolasi kesalahan dapat ditingkatkan.
- Kontra
- Beberapa inferensi dieksekusi secara berurutan, yang dapat meningkatkan waktu yang dibutuhkan.
- Jika hasil dari inferensi sebelumnya tidak diperoleh, inferensi berikutnya tidak dapat dieksekusi, sehingga menciptakan bottleneck
- Konfigurasi sistem bisa menjadi lebih kompleks
- Kasus penggunaan
- Ketika beberapa inferensi dilakukan untuk operasi tunggal
- Ketika ada urutan eksekusi atau ketergantungan antara beberapa inferensi
Pola layanan mikro paralel
Dalam pola layanan mikro paralel, permintaan inferensi dikirim ke setiap server inferensi secara paralel untuk mendapatkan beberapa hasil inferensi.
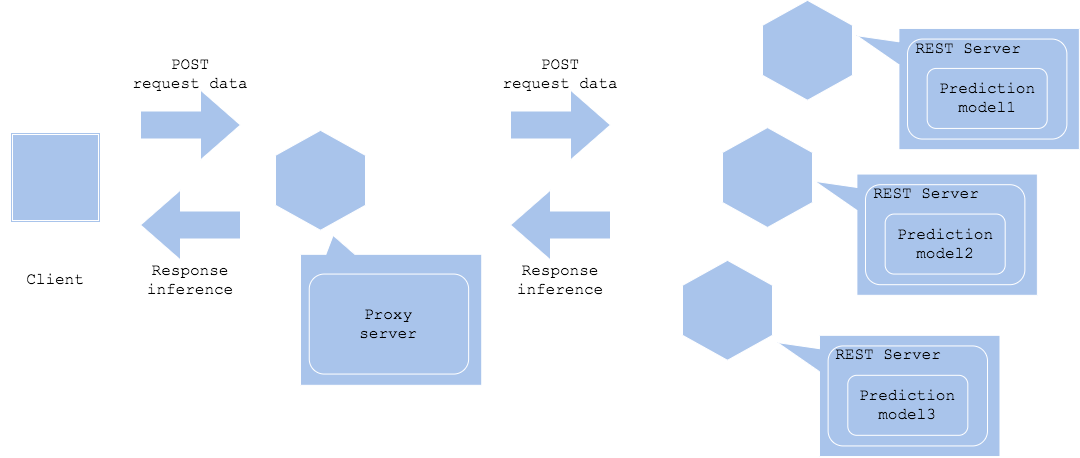
Synchronized horizontal
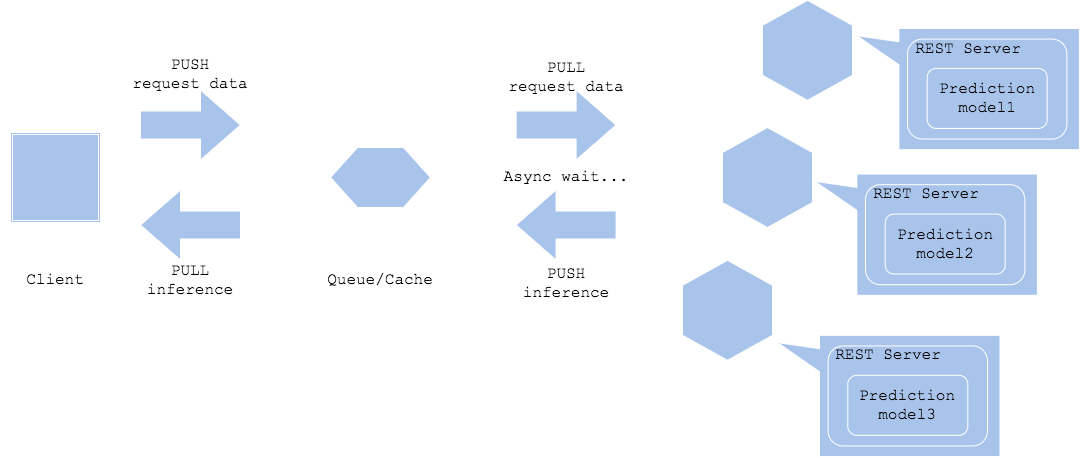
Asynchronized horizontal
- Pro
- Memisahkan server inferensi memungkinkan koordinasi resource dan isolasi kesalahan
- Konstruksi sistem yang fleksibel tanpa ketergantungan di antara alur kerja inferensi
- Kontra
- Sistem bisa menjadi kompleks karena menjalankan banyak inferensi
- Ketika berjalan secara sinkron, waktu yang dibutuhkan tergantung pada inferensi yang paling lambat
- Eksekusi asinkron membutuhkan alur kerja selanjutnya untuk mengkompensasi perbedaan waktu antara server inferensi.
- Kasus penggunaan
- Beberapa inferensi tanpa ketergantungan dieksekusi secara paralel
- Dalam kasus alur kerja di mana beberapa hasil inferensi diagregasi pada akhirnya
Pola cache inferensi
Dalam pola cache inferensi, hasil inferensi disimpan dalam cache, dan inferensi pada data yang sama dicari dalam cache.
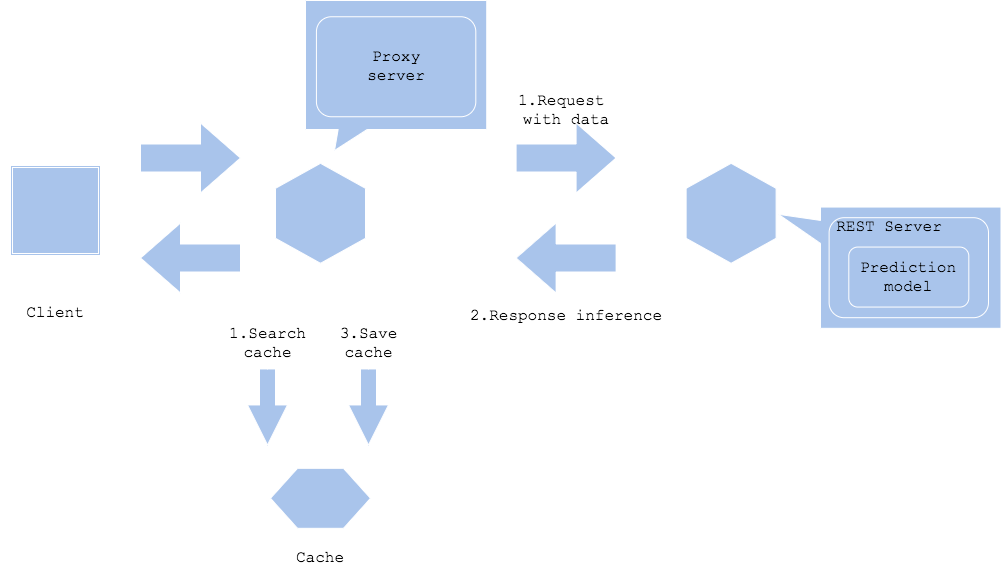
- Pro
- Dapat meningkatkan kecepatan inferensi dan membebani beban ke server inferensi
- Kontra
- Menimbulkan biaya server cache (banyak cache cenderung lebih mahal dan memiliki kapasitas yang lebih kecil daripada penyimpanan)
- Perlu mempertimbangkan kebijakan pembersihan cache
- Kasus penggunaan
- Permintaan inferensi yang sering untuk data yang sama
- Untuk data input yang bisa dicari dengan kunci cache
- Ketika Anda ingin memproses inferensi dengan kecepatan tinggi
Pola cache data
Pola cache data menyimpan data. Konten seperti gambar dan teks cenderung memiliki ukuran data yang besar. Jika ukuran data input atau data prapemrosesan besar, cache data dapat mengurangi beban akuisisi data.
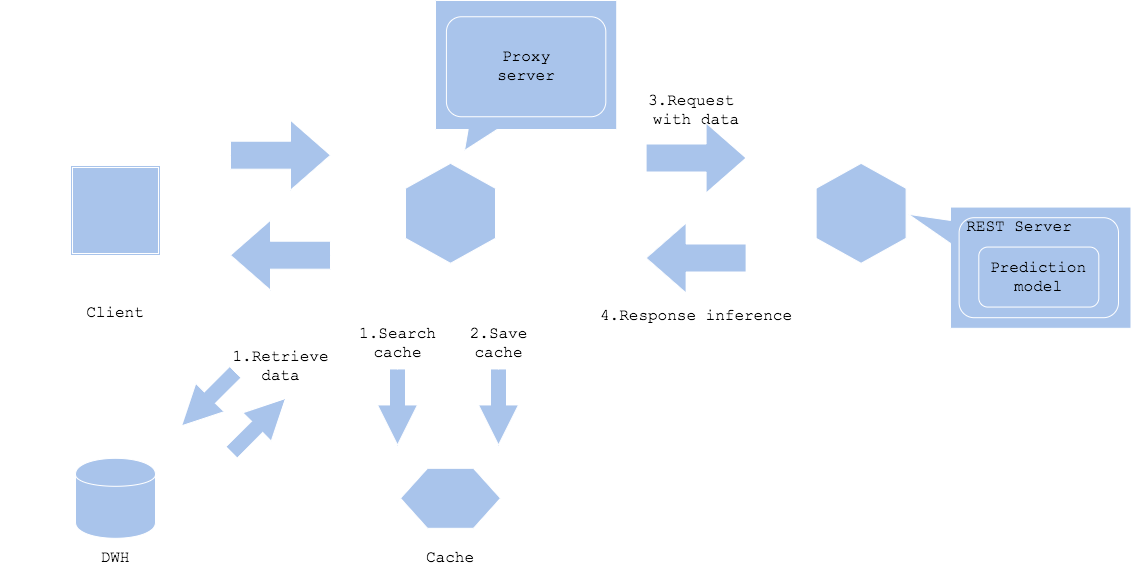
Input data cache
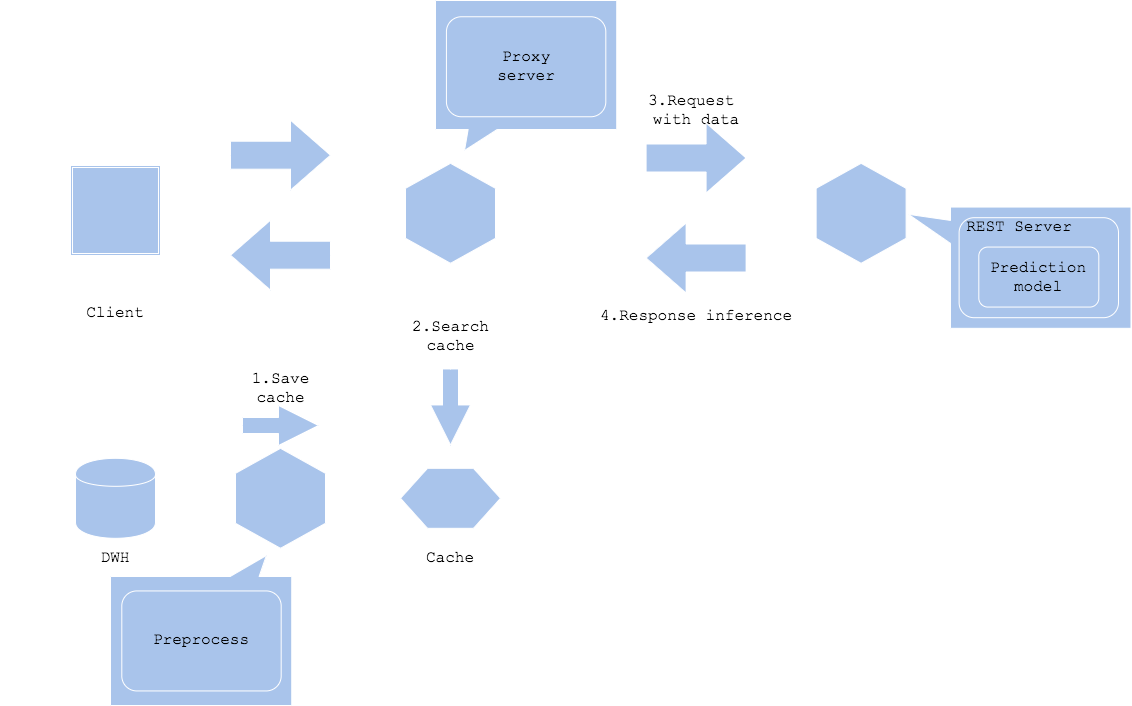
Preprocessed data cache
- Pro
- Dapat mengurangi akuisisi data dan overhead preprocessing
- Startup inferensi yang cepat
- Kontra
- Biaya server cache dikeluarkan
- Perlu mempertimbangkan kebijakan pembersihan cache
- Kasus penggunaan
- Alur kerja dengan permintaan inferensi untuk data yang sama
- Untuk data masukan berulang dari data yang sama
- Untuk data input yang bisa dicari dengan kunci cache
- Ketika Anda ingin mempercepat pemrosesan data
Referensi


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS