



Pengenalan
Decision Tree adalah pilihan populer di antara algoritma pembelajaran mesin karena kesederhanaannya, keinterpretabilitasannya, dan kemudahan visualisasinya. Aspek kritis dari Decision Tree adalah kemampuannya untuk secara otomatis memilih dan menempatkan fitur-fitur yang paling relevan dalam sebuah kumpulan data. Proses ini, disebut sebagai Feature Importance, membantu dalam menyederhanakan kumpulan data yang kompleks dan mengidentifikasi variabel yang paling signifikan. Dalam artikel ini, saya akan menjelajahi konsep Feature Importance dalam Decision Tree dan membahas berbagai metode yang digunakan untuk menghitungnya, seperti Gini Impurity, Information Gain, dan Gain Ratio.
Gini Impurity
Gini Impurity adalah ukuran seberapa sering elemen acak dari kumpulan data akan salah diklasifikasikan jika secara acak diberi label sesuai dengan distribusi label dalam subset. Gini Impurity dihitung untuk setiap fitur, dan algoritma Decision Tree memilih fitur dengan Gini Impurity terendah untuk memisahkan kumpulan data pada setiap simpul. Feature Importance secara keseluruhan ditentukan oleh pengurangan kumulatif dalam Gini Impurity yang dibawa oleh setiap fitur dalam pohon.
Secara matematis, Gini Impurity untuk kumpulan data
di mana
Gini Impurity digunakan untuk memutuskan fitur mana yang harus dibagi pada setiap simpul dalam Decision Tree. Fitur yang menghasilkan Gini Impurity rata-rata tertimbang terendah setelah membagi dipilih.
Information Gain
Information Gain adalah metode lain yang digunakan untuk menghitung Feature Importance dalam Decision Tree. Pendekatan ini didasarkan pada konsep entropi, yang merupakan ukuran keacakan atau kekacauan dalam sebuah kumpulan data. Information Gain menghitung pengurangan entropi yang dihasilkan dari membagi sebuah kumpulan data berdasarkan suatu fitur tertentu. Fitur yang menghasilkan Information Gain tertinggi dipilih untuk membagi kumpulan data pada setiap simpul. Feature Importance secara keseluruhan ditentukan oleh Information Gain kumulatif yang diberikan oleh setiap fitur dalam pohon.
Entropi dari kumpulan data
di mana
Information Gain dapat dihitung menggunakan rumus:
Gain Ratio
Gain Ratio adalah variasi dari Information Gain yang memperhitungkan informasi intrinsik dari sebuah fitur. Ini mengatasi bias terhadap fitur dengan jumlah nilai yang berbeda yang besar dalam Information Gain. Gain Ratio dihitung dengan membagi Information Gain dengan informasi intrinsik dari sebuah fitur. Fitur dengan Gain Ratio tertinggi dipilih untuk memisahkan pada setiap simpul, dan Feature Importance secara keseluruhan ditentukan oleh Gain Ratio kumulatif yang diberikan oleh setiap fitur dalam pohon.
Informasi intrinsik dari fitur
di mana
Gain Ratio kemudian dapat dihitung menggunakan rumus:
Mengvisualisasikan Feature Importance
Dalam bagian ini, saya akan menunjukkan bagaimana memvisualisasikan Feature Importance dalam kasus regresi dan klasifikasi menggunakan Python.
Pertama, mari impor library yang diperlukan dan buat dataset:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression, make_classification
from sklearn.tree import DecisionTreeRegressor, DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# Create synthetic datasets for regression and classification
X_reg, y_reg = make_regression(n_samples=1000, n_features=10, n_informative=5, random_state=42)
X_clf, y_clf = make_classification(n_samples=1000, n_features=10, n_informative=5, random_state=42)
# Split the datasets into train and test sets
X_reg_train, X_reg_test, y_reg_train, y_reg_test = train_test_split(X_reg, y_reg, test_size=0.3, random_state=42)
X_clf_train, X_clf_test, y_clf_train, y_clf_test = train_test_split(X_clf, y_clf, test_size=0.3, random_state=42)
Sekarang, mari buat dan latih model Decision Tree untuk regresi dan klasifikasi:
# Create and train decision tree models
regressor = DecisionTreeRegressor(random_state=42)
classifier = DecisionTreeClassifier(random_state=42)
regressor.fit(X_reg_train, y_reg_train)
classifier.fit(X_clf_train, y_clf_train)
Setelah model dilatih, kita dapat memperoleh nilai Feature Importance dan memvisualisasikannya:
# Get feature importance values for regression and classification models
reg_importance = regressor.feature_importances_
clf_importance = classifier.feature_importances_
# Function to visualize feature importance
def plot_feature_importance(importances, title):
indices = np.argsort(importances)[::-1]
plt.figure()
plt.title(title)
plt.bar(range(len(importances)), importances[indices], align='center')
plt.xticks(range(len(importances)), indices)
plt.xlabel('Feature Index')
plt.ylabel('Feature Importance')
plt.show()
# Visualize feature importance for regression and classification
plot_feature_importance(reg_importance, 'Feature Importance for Regression')
plot_feature_importance(clf_importance, 'Feature Importance for Classification')
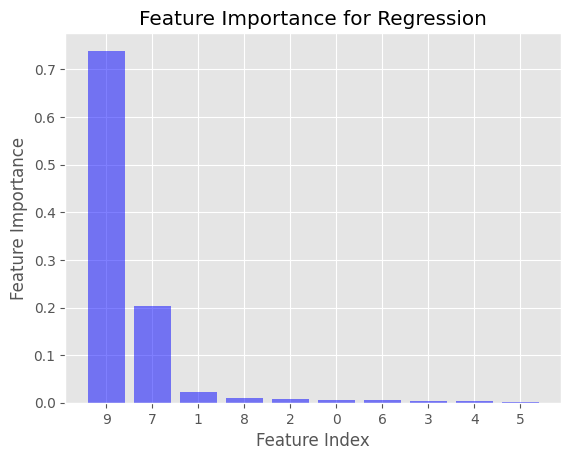
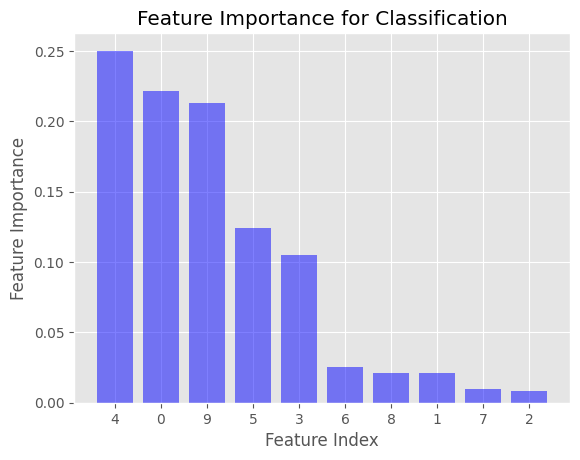
Ini akan menghasilkan dua diagram batang yang menampilkan nilai Feature Importance untuk kasus regresi dan klasifikasi. Sumbu-x mewakili indeks fitur, sedangkan sumbu-y mewakili nilai Feature Importance. Fitur diurutkan menurut pentingnya secara menurun.
Dalam contoh yang diberikan, Feature Importance dihitung menggunakan Gini Impurity untuk DecisionTreeClassifier dan mean squared error (MSE) untuk DecisionTreeRegressor. Ini adalah kriteria ketidakmurnian default yang digunakan dalam library Scikit-learn ketika membuat Decision Tree.
Anda dapat mengubah kriteria ketidakmurnian untuk DecisionTreeRegressor dan DecisionTreeClassifier dengan menentukan parameter kriteria ketika membuat model Decision Tree. Untuk DecisionTreeClassifier, Anda dapat menetapkan parameter criterion menjadi 'entropy' untuk menggunakan Information Gain sebagai gantinya dari Gini Impurity. Untuk DecisionTreeRegressor, Anda dapat menetapkan parameter criterion ke 'mae' (mean absolute error) jika Anda lebih suka menggunakan ukuran ketidakmurnian yang berbeda. Namun, Scikit-learn tidak mendukung Gain Ratio sebagai kriteria ketidakmurnian secara langsung.
Referensi















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS