

What is Perceptron
The perceptron is a simple yet powerful model inspired by the behavior of biological neurons in the brain. It is the basic building block for artificial neural networks and serves as a foundation for understanding more complex deep learning architectures.
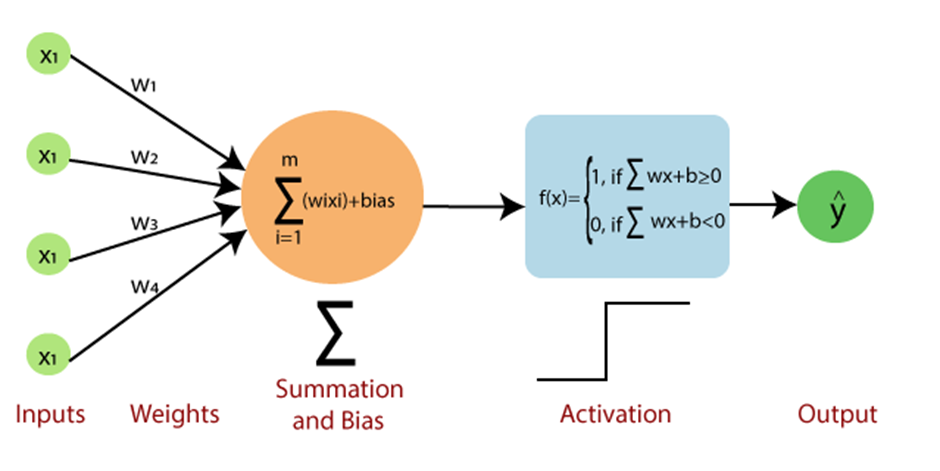
A perceptron is composed of several key components, including input nodes, weights, a bias, and an activation function. The input nodes receive input values, and the weights and bias determine the strength and direction of the connections. The activation function is responsible for transforming the weighted sum of the inputs into an output.
-
Input Nodes
The input nodes represent the features or variables of the input data. In a simple perceptron, each input node corresponds to a single feature. The input nodes transmit their values to the next layer in the network, multiplied by their corresponding weights. -
Weights
Weights are numerical values that signify the strength and direction of the connection between input nodes and the perceptron's output. During the learning process, the weights are adjusted to minimize the error between the predicted and actual output. -
Bias
The bias is an additional parameter that allows the perceptron to shift the decision boundary. It acts as an offset, enabling the perceptron to learn more complex relationships between the input features and the output. -
Activation Function
The activation function processes the weighted sum of the inputs, producing an output value. The choice of activation function significantly impacts the perceptron's behavior and learning capabilities.
Difference between perceptron and neuron?
Learning Algorithm of Perceptron
The perceptron learning algorithm adjusts the weights and biases based on the error between the actual and predicted output. The algorithm can be summarized as follows:
- Initialize the weights and bias with random values.
- For each input in the training dataset, calculate the weighted sum of the inputs and pass it through the activation function to obtain the predicted output.
- Compute the error between the predicted and actual output.
- Update the weights and bias using the error and a learning rate.
- Repeat steps 2-4 until the perceptron converges to a solution or a predefined stopping criterion is reached.
The perceptron learning algorithm is an example of supervised learning, as it requires a dataset with labeled examples to train the model. It is also an instance of online learning, as the weights and biases are updated incrementally after each input example.
Perceptrons in Deep Learning
Perceptrons play a foundational role in deep learning, serving as the building blocks for more sophisticated architectures. In this chapter, I will explore how perceptrons are organized in deep learning models, discuss multi-layer perceptrons (MLPs), and examine the process of training deep MLPs using backpropagation.
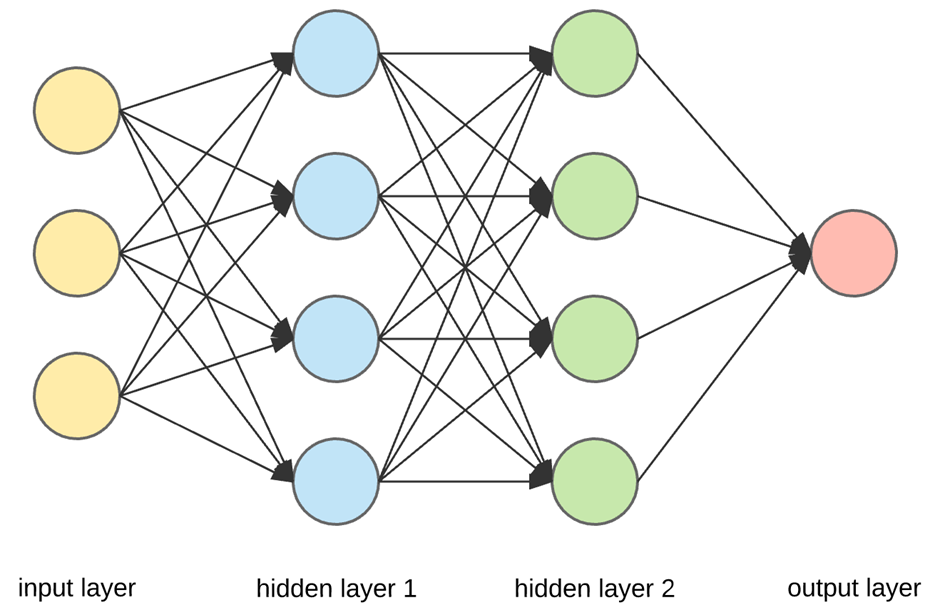
Perceptron Layers
In deep learning, perceptrons are organized into layers. Each layer can contain multiple perceptrons, and there are three main types of layers:
-
Input Layer
The input layer receives the raw data and consists of as many input nodes as there are features in the dataset. This layer does not perform any computation; it merely transmits the input values to the next layer. -
Hidden Layer(s)
Hidden layers process and transform the information from the input layer. A deep learning model can have multiple hidden layers, allowing the model to learn increasingly complex and abstract representations of the input data. Each hidden layer contains a number of perceptrons, which can vary depending on the architecture and problem being solved. -
Output Layer
The output layer produces the final prediction or classification. The number of output nodes depends on the task. For binary classification, a single output node suffices, while multi-class classification or regression tasks may require multiple output nodes.
Difference between perceptron and neuron?
Multi-Layer Perceptrons (MLPs)
An MLP is a feedforward neural network comprising multiple layers of perceptrons. The term "feedforward" indicates that the information flows in one direction through the network, from the input layer to the output layer, without any loops.
The key feature of MLPs is their ability to learn and represent complex, non-linear relationships between inputs and outputs. Unlike single-layer perceptrons, which can only learn linear decision boundaries, MLPs can approximate any continuous function, given a sufficient number of hidden layers and perceptrons.
Training a Deep MLP
Training a deep MLP involves adjusting the weights and biases through a process called backpropagation. The backpropagation algorithm calculates the gradient of the error with respect to each weight and bias, which is then used to update the model's parameters. The algorithm can be summarized as follows:
- Initialize the weights and biases with random values.
- Perform a forward pass through the network, calculating the weighted sum of the inputs and applying the activation function at each layer to obtain the final prediction.
- Compute the error between the predicted and actual output.
- Perform a backward pass through the network, calculating the gradient of the error with respect to each weight and bias using the chain rule.
- Update the weights and biases using the calculated gradients and a learning rate.
- Repeat steps 2-5 for a predefined number of epochs or until a stopping criterion is reached.
Backpropagation is an example of supervised learning, as it requires a dataset with labeled examples to train the model. It is also a form of batch learning, as the weights and biases are updated after processing the entire dataset.
References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS