
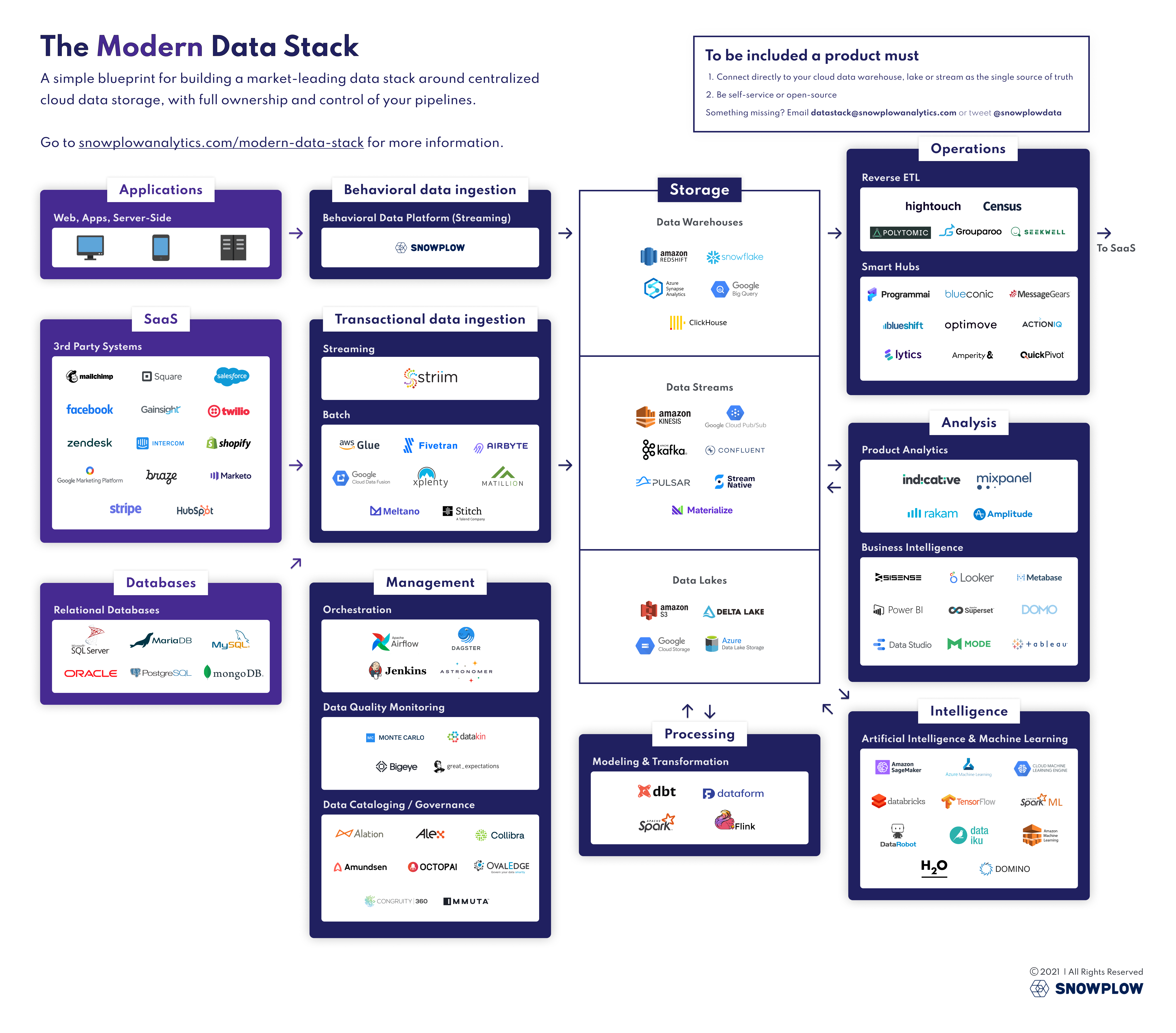
What is the Modern Data Stack
The Modern Data Stack is a collection of technologies comprised of cloud-native data-related services. By designing a data infrastructure that is appropriate for the modern cloud environment, we can reduce the time lag in making data actionable.
The Modern Data Stack includes the following services.
The modern data stack: a guide | SNOWPLOW
- Data accumulation
- Data Warehouses
Services for storing data in a form optimized for analysis
- Data Warehouses
- Data Integration
- ETL Tools / Change Data Capture / Data Streaming
Services for integrating data
- ETL Tools / Change Data Capture / Data Streaming
- Data processing
- Modeling & Transformation
Services for transforming stored data
- Modeling & Transformation
- Data management
- Orchestration
Job management services for data integration and data modeling - Data Cataloging / Governance
Services for storing metadata and facilitating data searchability and understanding - Data Quality / Monitoring
Services to detect low quality data and ensure data quality
- Orchestration
- Data analysis
- Business Intelligence
Services for data visualization and simple processing - Product Analytics
A set of services specialized in the analysis of offered products
- Business Intelligence
- Data operations
- Reverse ETL
Services for integrating stored data with other SaaS offerings.
- Reverse ETL
Key capabilities of the technologies included in the Modern Data Stack include
- Provided as a managed service
Minimal engineering required. - Constituted around a cloud DWH (data warehouse)
Built around the powerful cloud-based DWHs of today. - SQL-centric ecosystem to democratize data
The suite of services is built around easy-to-learn SQL for data/analytics engineers and business users. - Elastic workload
Pay-as-you-go and can scale up instantly.
With Modern Data Stack, companies have an easy-to-setup, low-cost data platform.
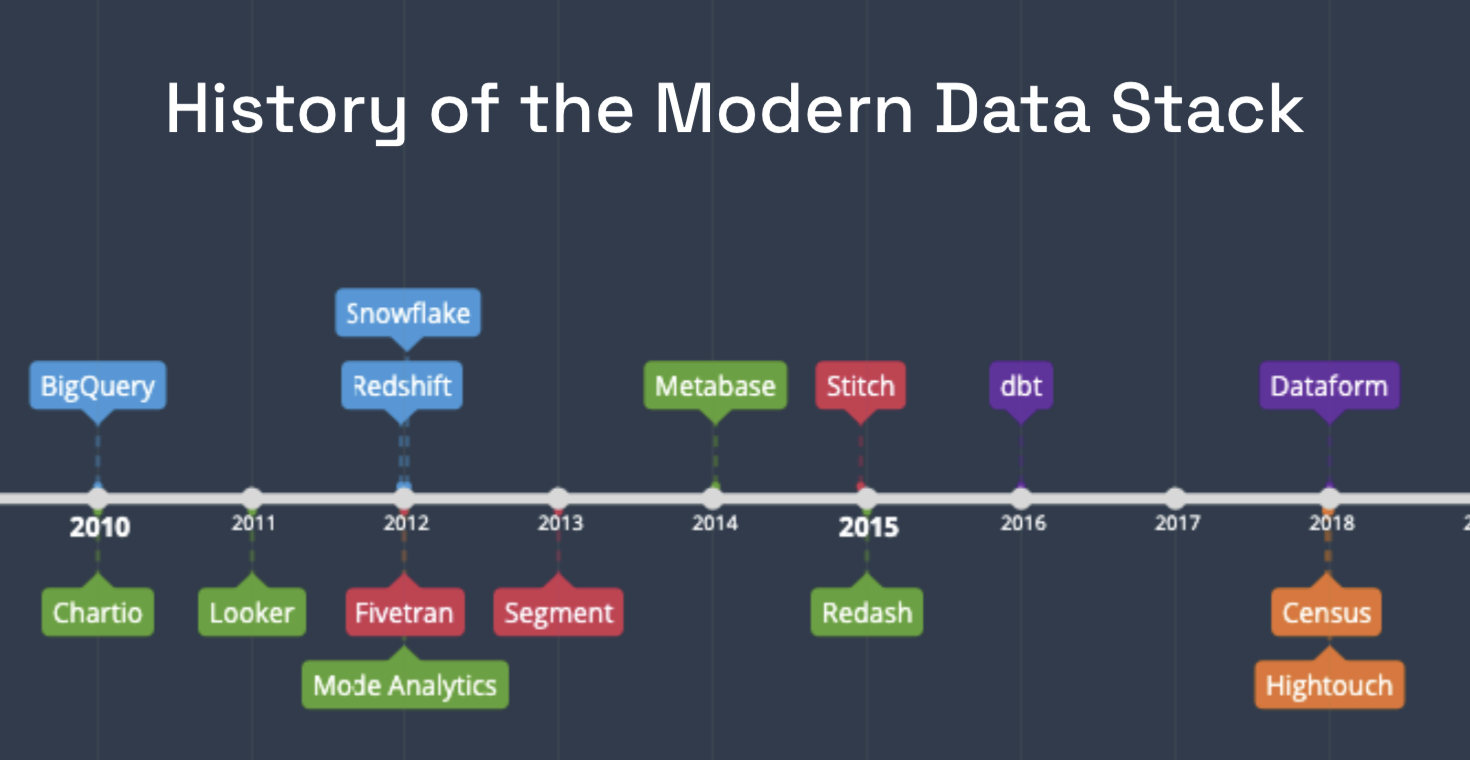
History of the Modern Data Stack
Underlying the Modern Data Stack is the evolution of cloud DWHs such as BigQuery, Snowflake, and Redshift.
Decades ago, only large enterprises could analyze large data sets, which required vertical scaling of computing resources and large upfront investments.From there, the era of public clouds such as AWS, GCP, and Azure has arrived, eliminating the need for companies to build and maintain capital-intensive server centers. AWS, GCP, and Azure have made it possible for any company to pay for as much storage and computing resources as it needs on a pay-as-you-go basis.
The modern cloud DWH revolution began with Google's BigQuery in 2010, followed by Redshift and Snowflake in 2012. Cloud DWHs are as simple and easy to use as RDBMSs before them and are built to handle big data type workloads. This shift began with SMBs that lacked the manpower needed for big data solutions, and as the SaaS-oriented cloud environment dramatically lowered the barrier to entry, large enterprises quickly jumped on board to simplify and reduce costs with elastic workloads.
Shortly after the advent of cloud DWH, an ecosystem of adjacent cloud-native technologies began to emerge, including
- BI
- Chartio - 2010
- Looker - 2011
- Mode - 2012
- Data integration
- Fivetran - 2012
- Segment - 2013
- Stitch - 2015
- Data transformation
- dbt - 2016
- Dataform - 2018
- Reverse ETL
- Census - 2018
- Hightouch - 2018
The ecosystem that has sprung up around the DWH makes up the Modern Data Stack. It is now possible to build a data infrastructure from scratch to production in less than a week, without spending any money and without months of architectural review and pipeline integration. The DWH is now a robust, easy-to-use platform that any company can obtain and be as competitive as the best high-tech companies in data analytics.
Trends in Modern Data Stack
Data integration
The number of areas where data is being used is increasing every year, and the number of SaaS that companies are dealing with is growing. In the past, companies developed their own REST APIs to extract data from various SaaS and put it into a DWH, but with the advent of services such as Fivetran and OSS such as Airbyte and Meltano, the need to develop data integration in-house is becoming less and less necessary. Many companies are opting for managed services that simply sync data to the DWH rather than developing it in-house.
ELT
With recent improvements in cloud DWH scalability, distributed systems technology, and query engines, it has become reasonable to perform transformations on the DWH, and ELT is becoming a common approach.
dbt
Anyone who knows SQL SELECT statements can develop a data mart with dbt. dbt has the following main features and functions
- Development can be done using only SQL SELECT statements.
- Automatic generation of schema and dependency documentation
- Automatic testing for NULLs, referential integrity, etc.
- Modularization of processing with Jinja
- Data Lineage
- Software development methods such as Git and CI/CD can be used
Reverse ETL
Reverse ETL is the process or technology of integrating from DWH to SaaS. As companies began to utilize DWH and SaaS, their data pipelines became more complex and the cost of researching and implementing various SaaS APIs to synchronize data from DWH to third-party SaaS tools became significant. Against this backdrop, Reverse ETL products have emerged, eliminating the need to write your own scripts to integrate from DWH to SaaS.
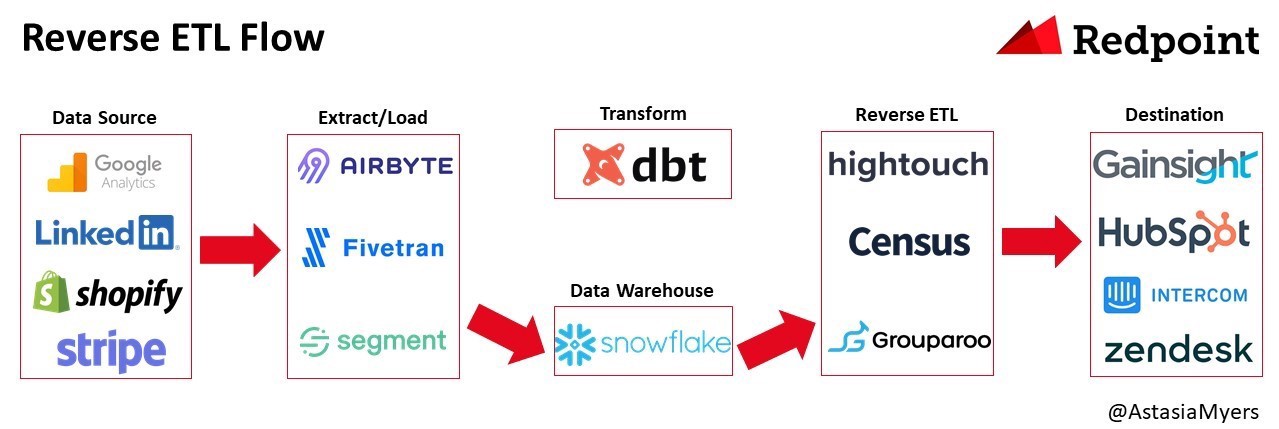
The following Reverse ETL products are currently available.
- Census
- Hightouch
- Grouparoo
- Polytomic
- Rudderstack
- Seekwell
- Workato
Data management with templated SQL and YAML
Templated SQL and YAML are becoming the way to manage the "T" in ELT. SQL is a mature interface that is easy to learn and declarative. Combine this with a templating language such as Jinja and it can be parameterized and made more dynamic. It can also be code managed and CI/CD can be applied.
Data mesh
As organizations expand, centralized data management becomes problematic and the concept of "data mesh," a decentralized data governance, is raised.
Data Lakehouse
While DWH is for structured data sets and data lakes are for unstructured and semi-structured data, a "data lakehouse" has recently emerged that integrates the data lake with the DWH so that the functions, schemas, and metadata of the DWH can be leveraged in the data lake. Behind the emergence of data lake houses are various issues that have emerged with the full-fledged use of AI, such as "data silos" caused by the dispersion of data storage locations due to different data formats, etc., and "process silos" caused by different tools for each business, such as data engineering, data science, and BI. The use of AI has brought with it a variety of issues.
References


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS