
What is MLOps
MLOps is a term coined by combining machine learning (ML) and DevOps, and is a practice for managing the machine learning lifecycle, including data preprocessing, model development, deployment, and operations.
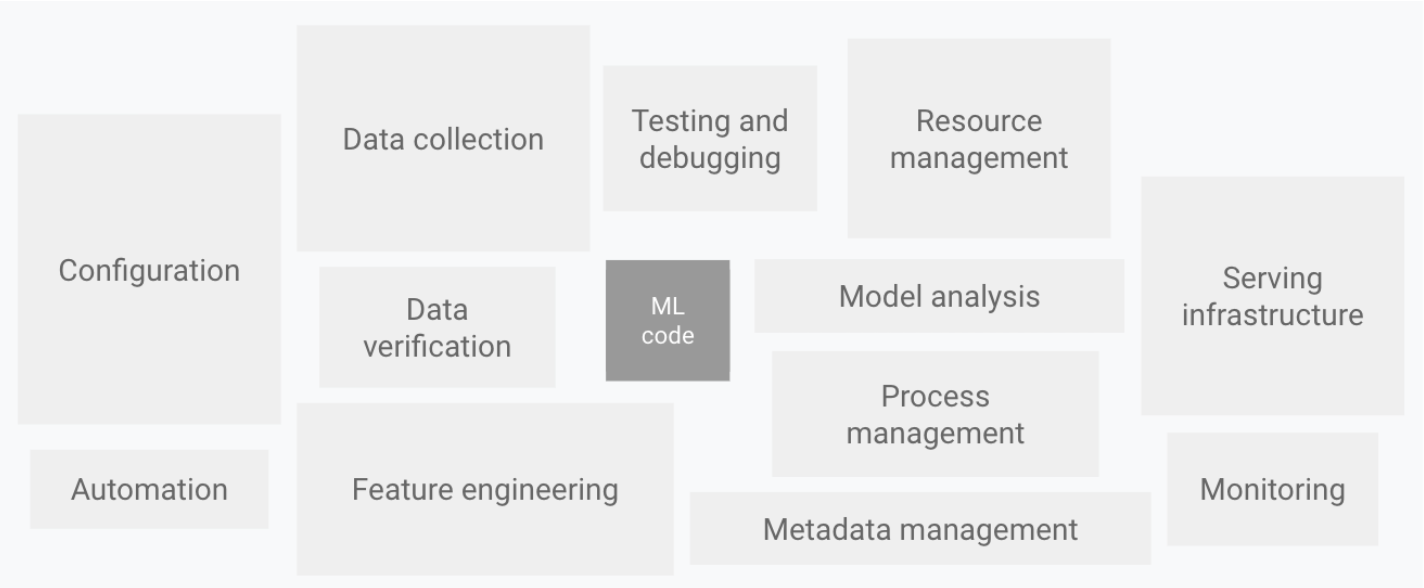
In ML systems, ML code accounts for a small percentage.
MLOps: Machine Learning Operations
To realize the value of machine learning, complex ML systems containing ML code must be operated in a production environment. The term MLOps was created to address these complex systems for sustainable development and operation.
Challenges of ML systems
Building an ML system has the following unique challenges:
-
More man-hours are required for development other than machine learning
Machine learning systems require man-hours for development and operation other than machine learning, such as integration into applications and construction of data pipelines. -
Takes time to reach a practical level
Machine learning is a complex technology with many ambiguous aspects, and even if it can be demonstrated in a development environment, there are many cases where problems arise in the production environment and the system ends up in a PoC. -
Reproducibility of experiments cannot be guaranteed
Code that worked fine during the model development phase may fail when implemented in the production environment. Also, even when the same model is trained on the same data, different results may be output. -
The quality of the model is difficult to maintain
Even if a model is of high quality when it is released, its quality will deteriorate over time due to some unforeseen change. The model must be kept up-to-date through continuous improvement, not just released. -
Easily conflicting between teams
Machine learning systems involve a variety of experts, including data engineers, data scientists, machine learning engineers, and system engineers. Because the team is composed of diverse individuals, it is easy for conflicts to arise within the team when problems arise.
MLOps Principles
The machine learning pipeline changes from three perspectives: data, machine learning models, and code.
- Automation
- Continuous X
- Version control
- Tracking Experiments
- Testing
- Monitoring
- Reproducibility
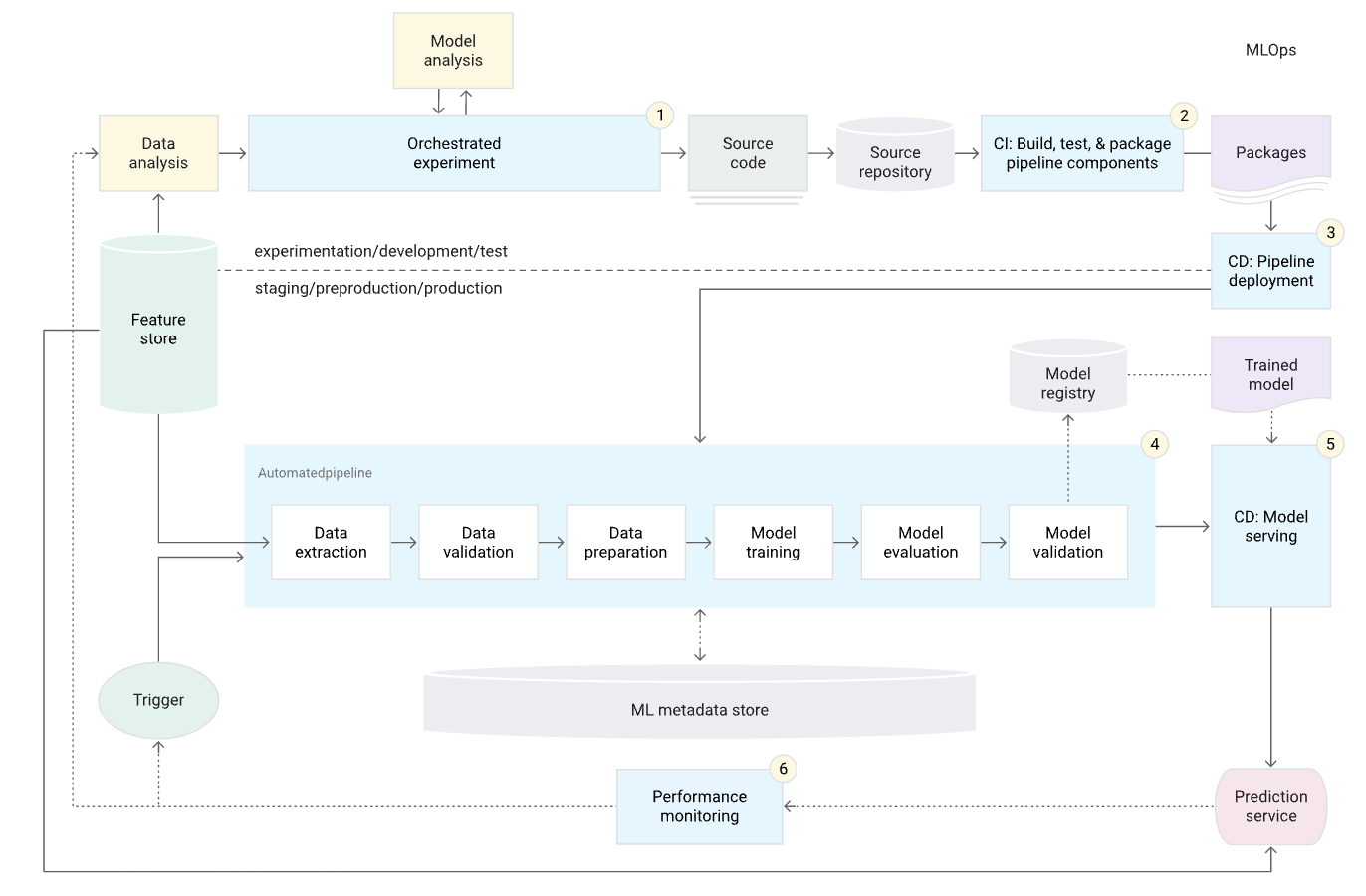
Automation
The level of automation of data, models, and pipelines determines the maturity of the ML process. As maturity increases, so does the speed of training new models, making it important to automate the deployment of ML models into the system without manual intervention.
MLOps: Machine Learning Operations
Continuous X
MLOps include the following practices:
-
Continuous Integration (CI)
Code, data, and model testing -
Continuous Delivery (CD)
Delivery of ML training pipeline to automatically deploy another ML model -
Continuous Training (CT)
Automatically retrain and redeploy ML models. -
Continuous Monitoring (CM)
Monitor data and model performance in production environment.
Version control
Treat ML scripts, models, and datasets as an intrinsic part of the DevOps process Since ML models and data are subject to change, it is important to track them with a version control system Common reasons why ML models and data may change include
- Models are retrained based on new training data
- Models are retrained based on new training methods
- Models degrade over time
- Models are deployed in new applications
- Models attacked and needs to be revised
- Data disappears for some reason
- Data ownership becomes an issue
- Statistical distribution of data changes
Tracking Experiments
Machine learning development is an iterative and research-centric process. In contrast to the traditional software development process, ML development involves running multiple experiments on model learning in parallel before deciding which models should be promoted to production. The content of those experiments must be tracked.
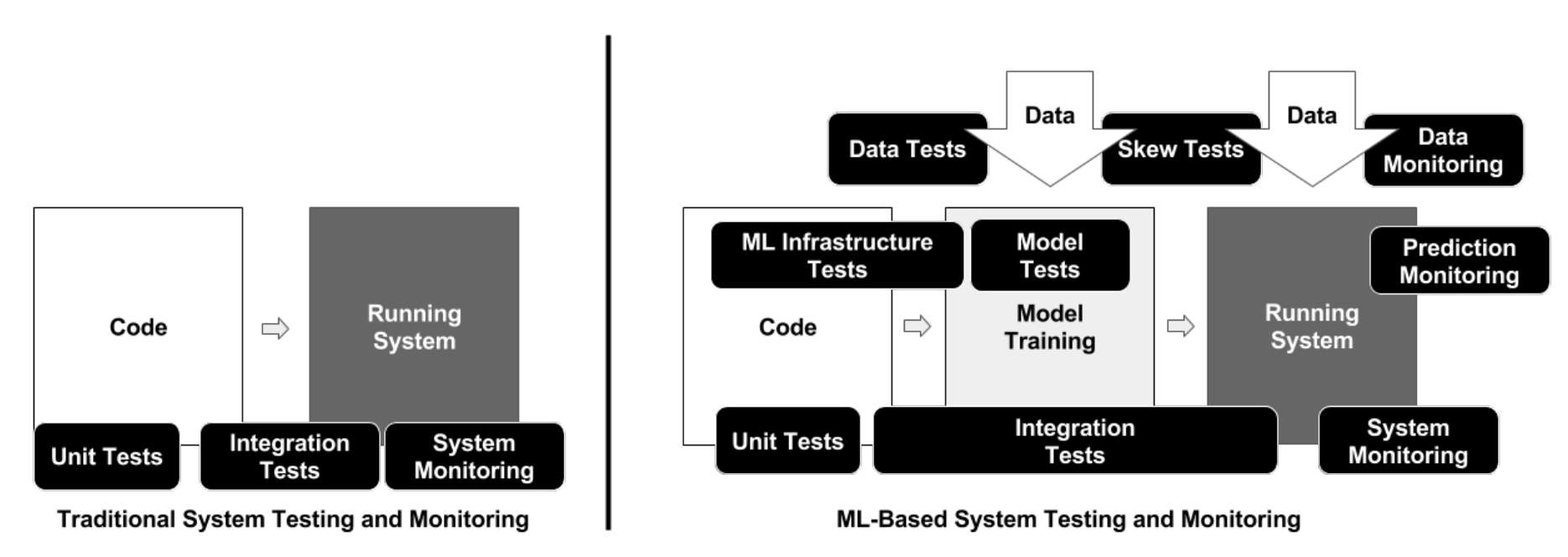
Testing
The ML development pipeline consists of the following three components
- Data pipeline
- ML model pipeline
- Application pipeline
The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
Following this separation, testing in ML systems is distinguished to the following three scopes:
- Features and data testing
- Model development testing
- ML infrastructure testing
Features and data testing
-
Automatically check data and feature schema
- To build the schema, compute statistics from the training data
-
Conduct feature importance tests to understand if new features increase predictive power
- Calculate correlation coefficients for feature columns
- Train a model with one or two features
- Measure data dependence, inference latency, and RAM usage of new features
- Remove unused or deprecated features from the infrastructure and document them
-
Verify that features and data pipelines are compliant with policies such as GDPR
-
Unit test feature creation code
Model development testing
-
Check the correlation between loss metrics (e.g., MSE) and business impact metrics (e.g., revenue, user engagement) of the ML algorithm
- Perform small A/B tests with intentionally degraded models
-
Conduct obsolescence testing on the model
- Perform A/B testing with obsolete models
-
Validate model performance
- Use additional test sets decoupled from the training and validation sets
-
Perform fairness and bias testing of ML model performance
- Collect more data, including potentially underestimated categories
ML infrastructure testing
-
Ensure reproducibility of ML model learning
- Identify non-deterministic portions of the model learning codebase and strive to minimize non-determinism
-
Stress test the ML API
- Perform unit tests to randomly generate input data and train models
- Perform crash tests for model training (test if ML model can be recovered from checkpoints after a crash in the middle of training)
-
Check the correctness of the algorithm
- Perform unit testing to ensure that the ML model is not trained to completion, but rather iterated several times and that losses are reduced during training
-
Perform integration testing of the entire ML pipeline
- Create fully automated tests that periodically trigger the entire ML pipeline
-
Validate the ML model before serving
- Set thresholds and test for slow degradation of model quality across many versions of the validation set
- Set thresholds and test for sudden performance degradation in new versions of ML models
Monitoring
The following monitoring is required to ensure that the deployed ML model is working as expected.
-
Monitor dependency changes throughout the pipeline and notify you of the results
- Data version changes
- Source system changes
- Dependency upgrades
-
Monitor data invariants of training and serving inputs
- Alerts when data at serving does not match the schema specified at training
-
Monitor whether features at training and serving compute the same values
- Log samples of serving traffic
- Calculate descriptive statistics (minimum, maximum, average, value, percentage of missing values, etc.) of training and sampled serving features and verify that they match
-
Monitor how out of date the system is in the production environment
- Identify elements for monitoring and create a strategy for monitoring the model before deploying to production
-
Monitor the computational performance of the ML system
- Pre-set alert thresholds and measure performance of code, data, model versions and components
- Collect system usage metrics such as GPU memory allocation, network traffic, and disk usage å
-
Monitor the feature generation process
- Frequently rerun feature generation
-
Monitor dramatic and gradual degradation of predictive performance of ML models
- Measure statistical bias of predictions (average of predictions over slices of data)
- Measure the quality of predictions in real time if labels are present immediately after the prediction
Reproducibility
Reproducibility in the ML pipeline means that the same inputs will produce the same results in each phase of ML model development. Reproducibility is an important principle of MLOps. The following is an overview of what should be done to ensure reproducibility in the following phases
- Data collection phase
- Feature engineering phase
- Model training and build phases
- Model deployment phase
Data collection phase
To ensure reproducibility of training data generation, the following should be done.
- Always back up your data
- Keep snapshots of the dataset
- Design data sources with timestamps
- Do data versioning
Feature engineering phase
To make feature engineering reproducible, do the following.
- Place feature generation code under version control
Model training and build phases
To ensure reproducibility of model training and building, we do the following
- Ensure that the feature order is always the same
- Document and automate feature transformations such as normalization
- Document and automate hyperparameter selection
Model deployment phase
To ensure reproducibility of the model deployment, the following will be performed.
- Match software versions and dependencies to the production environment
- Use Docker and document its specifications, including image versions
Tools to enable MLOps
The following tools are useful to realize MLOps.
- Version Control: GitHub, GitLab
- Container: Docker
- Container orchestration: Kubernetes, Mesos
- CI: Circle CI, Jenkins, GitHub Actions, Gitlab CI
- Infrastructure as Code (IaC): Terraform, Ansible, Pupet
- Monitoring: Sentry, Datadog, Prometheus, Deequ
- Model serving: FastAPI, KFServing, BentoML, Vertex AI, Sagemaker
- Machine learning platform: Sagemaker, Vertex AI
- Feature store: Feast, Hopworks, Rasgo, Vertex AI, SageMaker, Databricks, Tecton, Zipline
- Experiment management: Weights & Biases, MLFlow, Trains, Comet, Neptune, TensorBoard
- Pipeline management: Airflow, Argo, Digdag, Metaflow, Kubeflow, Kedro, TFX, Prefect
- Hyperparameter optimization: Scikit-Optimize, Optuna, Hydra
References


















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS