

What is AlloyDB
AlloyDB for PostgreSQL is a fully managed service provided by Google Cloud, designed to be compatible with PostgreSQL. It stands out for its exceptional performance, availability, and scalability, surpassing its competitor, Cloud SQL.
Equipped with proprietary technology in its storage mechanism, AlloyDB boasts significant speed enhancements over standard PostgreSQL. Transaction processing is more than four times faster, and analytic processing can reach up to a hundred times faster.
In addition to its remarkable performance, AlloyDB also shines in operational ease. Many operational tasks, including backups, patch application, and storage expansion, are automated. AlloyDB also guarantees a high availability SLA of 99.99%.
AlloyDB was previewed on May 11, 2022, and later became generally available on December 13, 2022. Its introduction and subsequent development have positioned it as a database capable of meeting the rigorous non-functional requirements of enterprise systems.
Compatibility with PostgreSQL
AlloyDB prides itself on being 100% compatible with PostgreSQL. This high level of compatibility means you can utilize the same database connections, such as the psql command-line, and other PostgreSQL clients.
In AlloyDB, parameters that are typically set in postgresql.conf in standard PostgreSQL are managed as database flags. These can be managed through the Web console or the gcloud command.
Pricing
AlloyDB employs a pay-per-use pricing model, meaning you are charged only for the resources you actually use. The pricing is determined based on several factors, including:
- CPU/Memory allocated
- Storage used, including backups
- Networking (egress to other regions only)
AlloyDB consists of "Primary Instances" and "Read Pool Nodes," and you can specify the specifications (CPU/Memory) for each. Billing is based on the duration of the instance existence, with charges accrued on an hourly basis.
Storage is automatically allocated as needed by the database, and scales up and down accordingly. You're billed only for the data size used. This automatic scaling of storage ensures that you pay only for what you need, providing cost efficiency and eliminating the need for manual resizing.
Architecture
AlloyDB consists of the following architecture.
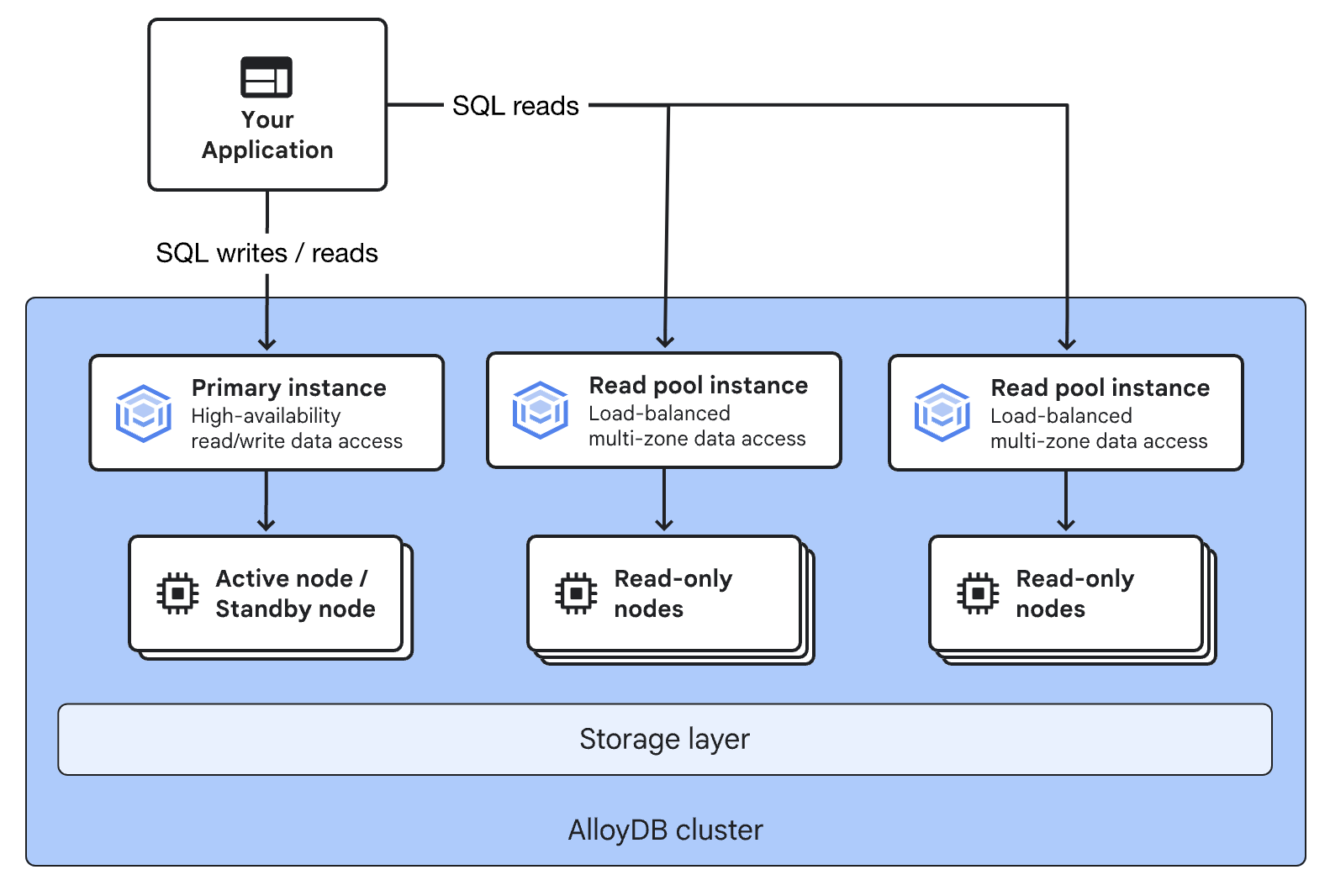
Cluster
The basic unit of management in AlloyDB for PostgreSQL is the cluster.
Primary Instance
Each cluster has a Primary Instance. In a high-availability setup, the Primary Instance can maintain a replica (standby instance) for failover. Clients direct both read and write access to this Primary Instance, which is issued a single IP address. This IP address remains constant even during failover, enabling the application to establish connections again after a certain downtime without any configuration changes.
A manual failover option is also available for testing purposes.
Read Pool Instance
The Read Pool Instance is not a single node but a group of nodes providing read-only access. Each Read Pool Instance is assigned an IP address for read operations, with any access to this IP address assigned to one of the nodes in the Read Pool Instance. By increasing or decreasing the number of nodes, you can balance the read workload.
While the Primary Instance is mandatory, creating a Read Pool Instance is optional. Creating one increases costs but also enables read workload distribution, particularly useful for analytical purposes.
Networking
Rather than being created within a user-managed VPC, AlloyDB clusters are created within a Google Cloud-managed VPC. This is a key feature and is facilitated by a mechanism known as Private Service Access. The network managed by Google Cloud where the cluster is located is called the Service Producer Network, a system shared with Cloud SQL and Cloud Memorystore.
The Service Producer Network and the user's VPC connect via VPC peering.
Cross-region Replication
AlloyDB supports optional cross-region replication. When this feature is activated, a secondary cluster is created in a different region from the primary cluster, and data is replicated asynchronously.
The secondary cluster is read-only but can be manually promoted to primary. This feature not only provides a disaster recovery solution but also reduces read latency by placing a read-only secondary cluster closer to users or applications.
Scalability
The primary instance is a single instance responsible for both read and write operations. Although horizontal scaling isn't possible with the primary instance, vertical scaling through spec changes is possible. The read pool instances, on the other hand, are a cluster of read-only nodes. These instances offer the flexibility to scale horizontally by increasing the number of nodes or vertically by upgrading the specs.
Backup
Backup is an essential aspect of any database management system, and AlloyDB in Google Cloud offers three types of backups: Continuous, On-Demand, and Automated backups. The backup process completes at the storage layer, ensuring there is no performance impact.
Continuous Backups
Continuous backups are enabled by default in AlloyDB. They allow for point-in-time recovery, which is a critical feature for managing and mitigating data losses.
On-Demand Backups
On-demand backups are manually executed backups. They can be initiated from the Google Cloud Console or using gcloud commands. This backup type provides flexibility and control over when and how frequently the backups are taken.
Automated Backups
Automated backups are taken based on a set schedule and are enabled by default. They offer the advantage of requiring no manual intervention, hence reducing the chances of human error. By default, these backups are retained for 14 days.
Connecting to AlloyDB
Connecting through Client Software
Connection to AlloyDB for PostgreSQL is feasible via common PostgreSQL client software such as the psql command.
Primary and Read Pool Instances Connection
From the client side, connections are made to the private IP address provided by either the primary instance or the read pool instances.
Authentication and Authorization in AlloyDB
When an AlloyDB cluster is freshly created, logging in is possible via the postgres user. The login password is defined at the time of cluster creation.
AlloyDB Auth proxy
The AlloyDB Auth Proxy is a proxy software installed locally on the client side of applications using AlloyDB. With the Auth Proxy, AlloyDB can authenticate and authorize using IAM permissions. Also, communication from applications to the database is encrypted with TLS.
When an application is operating in a Google Cloud environment, like Cloud Run, it is possible to log in to the database using the permissions of the Service Account attached to the instance (the roles/alloydb.client role).
References

















































































































Ryusei Kakujo




Weave the future of cities through data
Transportation modeling/ Urban planning/ Machine learning/ Computer science/ GIS